

在本文中,你将学习如何理解和调试Node.js应用程序的内存使用情况,并使用监控工具来全面了解堆内存和垃圾回收的情况。以下是本教程结束时你会得到的东西。
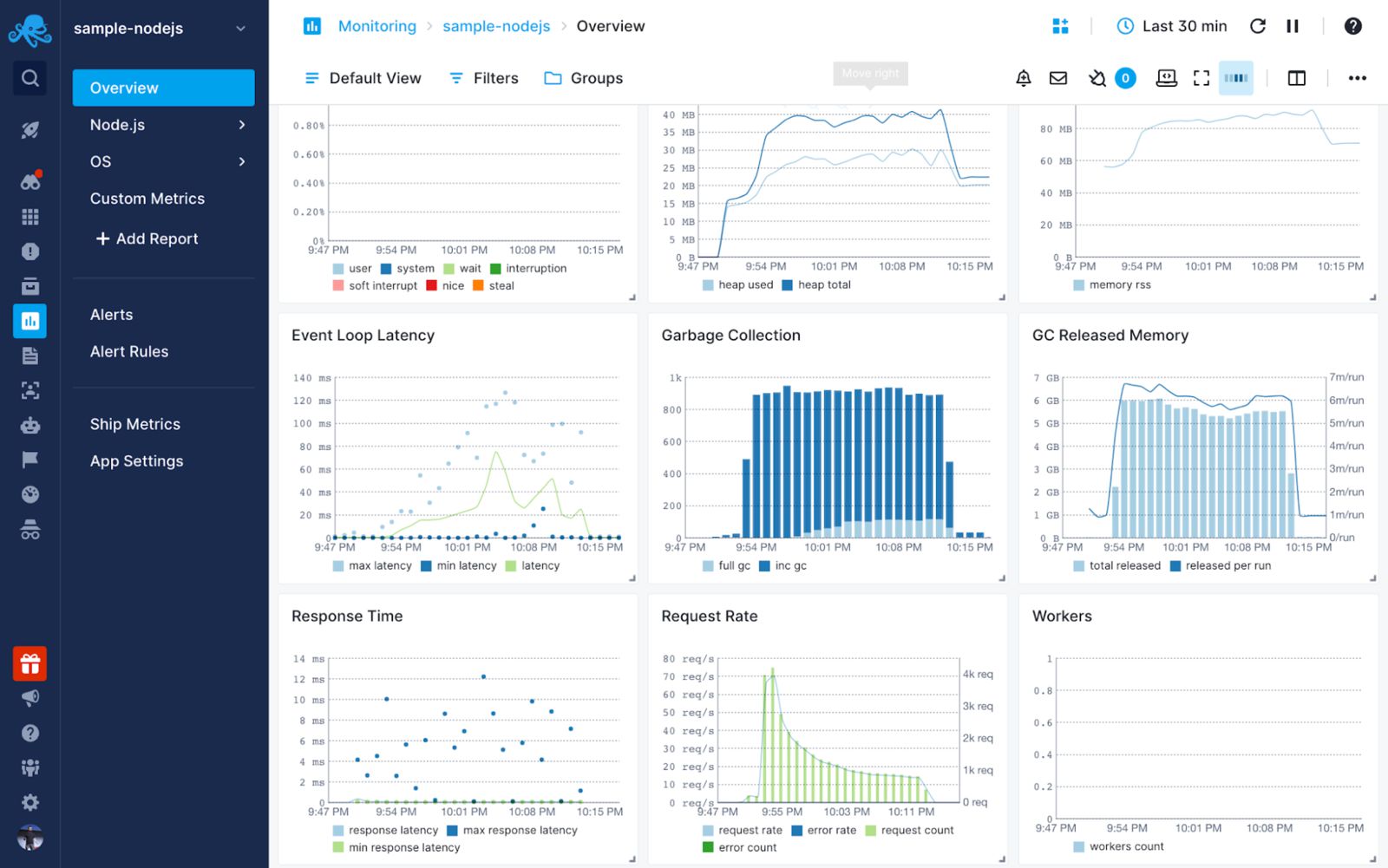
内存泄漏常常不被注意。这就是为什么我建议使用一个工具来跟踪垃圾收集周期的历史数据,并在堆内存用量开始不受控制地飙升时通知你。
你可以重新启动应用程序,让它神奇地消失。但是,你最终想了解发生了什么,以及如何阻止它再次发生。
这就是我今天要教你的。让我们开始吧!
什么是Node.js的内存泄漏?
长话短说,它是指你的Node.js应用程序的CPU和内存使用量随着时间的推移而增加,没有明显的原因。
简单地说,Node.js内存泄漏是堆上的一个孤儿内存块,它不再被你的应用程序使用,因为它没有被垃圾收集器释放。
这是一个无用的内存块。这些块会随着时间的推移而增长,并导致你的应用程序崩溃,因为它耗尽了内存。
让我告诉你这一切意味着什么,在引擎盖下。
什么是Node.js的 垃圾收集?
如果一块内存段没有被任何地方引用,它可以被释放。然而,垃圾收集器很难追踪到每一块内存。这就是你如何得到应用程序负载的奇怪增加的原因,即使它没有任何意义。
Node.js使用Chrome的V8引擎来运行JavaScript。在V8中,内存被分为堆栈和堆内存:
- 堆栈:存储静态数据、方法和函数框架、原始值以及存储对象的指针。堆栈是由操作系统管理的。
- 堆:存储对象。因为JavaScript中的所有东西都是一个对象,这意味着所有的动态数据,如数组、闭包等。堆是最大的内存块,它是**垃圾收集(GC)**发生的地方。
垃圾收集释放了堆中被不再直接或间接从堆栈中引用的对象所使用的内存。其目的是为创建新的对象创造自由空间。垃圾收集是生成的。堆中的对象按年龄分组,在不同的阶段被清除。
有两个阶段和两种算法用于垃圾收集。
新空间和旧空间
堆有两个主要阶段:
- 新空间:发生新分配的地方。垃圾收集是快速的。其大小在1到8MB之间。新空间中的对象被称为年轻一代。
- 旧空间:在新空间的收集器中幸存下来的对象被提升到那里。旧空间中的对象被称为 "旧一代"。分配的速度很快,但是,垃圾收集是昂贵的,而且不频繁。
年轻一代和旧一代
大约有五分之一的年轻一代能在垃圾收集中存活下来,并被转移到旧一代。旧一代对象的垃圾收集只有在内存被耗尽时才会开始。在这种情况下,V8使用两种算法进行垃圾收集。
Scavenge和Mark-Sweep收集
- Scavenge收集:速度快,在年轻一代上运行。
- Mark-Sweep收集:速度较慢,在 "老一代 "上运行。
为什么垃圾收集很贵?
可悲的是,V8会在垃圾收集过程中停止程序的执行。这可能会导致延迟增加。很明显,你不希望垃圾收集周期占用大量时间,阻断主线程的执行。
哇,这可真让人难以忘怀。但是,现在一旦你知道了这些,让我们继续找出导致内存泄漏的原因以及如何修复它们。
导致它们的原因:常见的Node.js内存泄露问题
一些Node.js的内存泄漏是由常见的问题引起的。这些可能是由多种原因造成的循环对象引用。
让我告诉你内存泄漏的最常见原因。
全局变量
Node.js中的全局变量是指根节点所引用的变量,它是全局的。它相当于在浏览器中运行的JavaScript的窗口。
全局变量在应用程序的整个生命周期内都不会被垃圾回收。只要应用程序在运行,它们就会占用内存。最重要的是:这适用于被全局变量引用的任何对象,以及它们的所有子对象。在Node.js应用程序中,如果有大量的对象从根部被引用,就会导致内存泄漏。
让我掀起一股潮流,"请不要这样做"。
多重引用
如果你从多个对象中引用同一个对象,如果其中一个引用被垃圾回收,而另一个则被悬空,就会导致内存泄露。
闭包
闭包会记忆其周围的环境。当一个闭包在堆中持有一个大对象的引用时,只要闭包在使用中,它就会将该对象保留在内存中。
这意味着很容易出现这样的情况:持有这种引用的闭包可以被不适当地使用,从而导致内存泄漏。
计时器和事件
当重度对象引用被保留在其回调中而没有得到适当的处理时,setTimeout、setInterval、Observers和事件监听器的使用会导致内存泄露。
如何避免Node.js应用程序中的内存泄漏。预防最佳实践
现在你对Node.js应用程序中的内存泄漏的原因有了更好的了解,让我解释一下如何避免它们以及一些最佳实践,以确保内存得到有效利用。
减少对全局变量的使用
由于全局变量永远不会被垃圾回收,所以最好确保你不要过度使用它们。这里有一些方法可以确保这种情况不会发生。
避免意外的全局变量
当你给一个未声明的变量赋值时,JavaScript会自动将其 "提升"。这意味着它被分配到全局范围。非常糟糕的是!
这可能是一个打字错误的结果,并可能导致内存泄漏。另一种方式可能是在全局范围内的函数中把一个变量分配给这个:
// This will be hoisted as a global variable
function hello() {
foo = "Message";
}
// This will also become a global variable as global functions have
// global `this` as the contextual `this` in non strict mode
function hello() {
this.foo = "Message";
}
为了避免这样的问题,总是在严格模式下编写JavaScript,在JS文件的顶部使用 "use strict"; 注释。
当你使用ES模块或像TypeScript或Babel这样的转码器时,你不需要它,因为它是自动启用的。
在Node.js中,你可以通过在运行node命令时传递-use_strict标志来全面启用严格模式:
"use strict";
// This will not be hoisted as a global variable
function hello() {
foo = "Message"; // will throw runtime error
}
// This will not become global variable as global functions
// have their own `this` in strict mode
function hello() {
this.foo = "Message";
}
当你使用箭头函数时,你还需要注意不要创建意外的globals,不幸的是,严格模式在这方面没有帮助。你可以使用ESLint的no-invalid-this规则来避免这种情况。
如果你不使用ESLint,只要确保不从全局箭头函数中赋值给this即可:
// This will also become a global variable as arrow functions
// do not have a contextual `this` and instead use a lexical `this`
const hello = () => {
this.foo = 'Message";
}
最后,请记住不要使用绑定或调用方法将全局this绑定到任何函数,因为这将违背使用严格模式的目的。
少用全局范围
你应该尽可能地避免使用全局范围,包括全局变量。以下是你在这方面应该遵循的一些最佳实践:
- 在函数中使用局部范围,因为它将被垃圾回收。这样可以释放内存。如果你由于某些限制而不得不使用一个全局变量,当它不再需要时,将其值设置为空。这意味着你可以 "手动 "收集它。
- 只在常量、缓存和可重复使用的单子中使用全局变量。
- 不要为了避免传递数值的方便而使用全局变量。对于函数和类之间的数据共享,应将值作为参数或对象属性来传递。
- 不要在全局范围内存储大对象。如果你必须存储它们,在不需要它们的时候,将其值设置为空。
- 当你使用对象作为缓存时,设置一个处理程序来偶尔清理它们,不要让它们无限制地增长。
有效地使用堆栈内存
访问堆栈内存比访问堆更有效率和性能。只使用静态值是不符合逻辑的,因为在现实世界中你会使用对象和动态数据。
然而,有几件事你可以做,使这个过程对内存更友好。
首先,尽可能避免从堆栈变量中引用堆对象。第二,删除未使用的变量。第三,解构对象,只使用你需要的对象或数组的字段,而不是将整个对象或数组传递给函数、闭包、计时器和事件处理程序。
如果你遵循这些简单的建议,你就可以避免在闭包中保留对对象的引用。你传递的字段是基元,它们将被保存在栈中。下面是一个例子:
function outer() {
const obj = {
foo: 1,
bar: "hello",
};
const closure = () {
const { foo } = obj;
myFunc(foo);
}
}
function myFunc(foo) {}
有效地使用堆内存
在你构建的每个Node.js应用程序中,你都必须使用堆。这取决于你如何有效地使用它。
就堆的使用而言,传递对象引用比复制对象更昂贵。只有当对象是绝对巨大的时候,你才应该传递一个引用。但是,这在你日常的Node.js开发中根本不会经常发生。
你可以使用对象传播语法(...)或Object.assign来复制一个对象。这种范式与函数式编程中的不变性是一致的,在函数式编程中,你要不断地创建新的对象,同时确保函数尽可能地 "纯"。
这也意味着你应该避免创建巨大的对象树。如果你不能避免,尽量让它们在本地范围内保持短暂的存在。
这也是你应该对一般的变量所做的,使它们成为短命的。
当你在做这件事的时候,确保你监控你的堆大小。我将在本文中进一步解释如何用Sematext做这件事。
正确使用闭包、定时器和事件处理程序
在Node.js应用程序中,闭包、定时器和事件处理程序往往会造成内存泄漏。
让我们看看Meteor团队的一段代码,它解释了一个导致内存泄漏的闭包。
它导致了内存泄漏,因为longStr变量从未被收集,并在内存中不断增长。细节在这篇博文中有所解释:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) console.log("hi");
};
theThing = {
longStr: new Array(1000000).join("*"),
someMethod: function () {
console.log(someMessage);
},
};
};
setInterval(replaceThing, 1000);
上面的代码创建了多个闭包,这些闭包持有对象的引用。在这种情况下,内存泄漏可以通过在 replaceThing 函数的结尾处将 originalThing 清空来解决。
你可以通过创建对象的副本和使用我上面提到的不可变的对象的方法来避免这样的问题。
同样的逻辑也适用于定时器。记住要传递对象的副本,避免突变。当你不再需要它们的时候,通过使用clearTimeout和clearInterval方法来清除定时器。
事件监听器和观察者也是如此。一旦它们完成了你想让它们做的事情,就清除它们。不要让事件监听器永远运行下去,尤其是当它们要从父作用域保持任何对象引用时。
Node.js内存泄漏检测器
修复内存泄漏并不像看起来那么简单。你需要检查你的代码库,找出全局范围、闭包、堆内存或我上面概述的任何其他痛点的任何问题。
短期内修复Node.js内存泄漏的一个快速方法是重新启动应用程序。请确保首先这样做,然后拿出时间来寻找内存泄漏的根本原因。
这里有几个工具可以帮助你检测内存泄露。
Memwatch
自memwatch在npm上发布以来,已经过去了9年,但你仍然可以用它来检测内存泄露。
这个模块很有用,因为如果它看到堆的增长超过了连续5次垃圾回收,它就会发出泄漏事件。
Heapdump
Heapdump是另一个很好的工具,用于拍摄堆内存的快照。然后你可以在随后的Chrome开发者工具中检查它们。
节点检查器
遗憾的是,memwatch和heapdump不能连接到正在运行的应用程序。但是,节点检测器可以!它可以让您连接到正在运行的应用程序。它可以让你通过运行node-debug命令连接到一个正在运行的应用程序。该命令将在你的默认浏览器中加载 Node Inspector。
V8检查器与Chrome开发工具
你可以使用Chrome中的开发工具来检查Node.js应用程序。怎么做?它们都运行相同的V8引擎,其中包含Dev Tools使用的检查器。
这里有一个例子,是一个Express应用的样本。它的唯一目的是显示它曾经收到的所有请求:
const express = require('express')
const app = express()
const port = 3000
const requestLogs = [];
app.get('/', (req, res) => {
requestLogs.push({ url: req.url, date: new Date() });
res.status(200).send(JSON.stringify(requestLogs));
})
app.listen(port, () => {
console.log(`Sample app listening on port ${port}.`)
})
为了暴露检查器,让我们用-inspect标志运行Node.js:
node --inspect index.js
Debugger listening on ws://127.0.0.1:9229/7fc22153-836d-4ed2-8090-a84a842a199e
For help, see: <https://nodejs.org/en/docs/inspector>
Sample app listening on port 3000.
打开Chrome浏览器,转到chrome://inspect。Voila!为你的Node.js应用程序提供了一个全功能的调试器。在这里,你可以对内存使用情况进行快照。
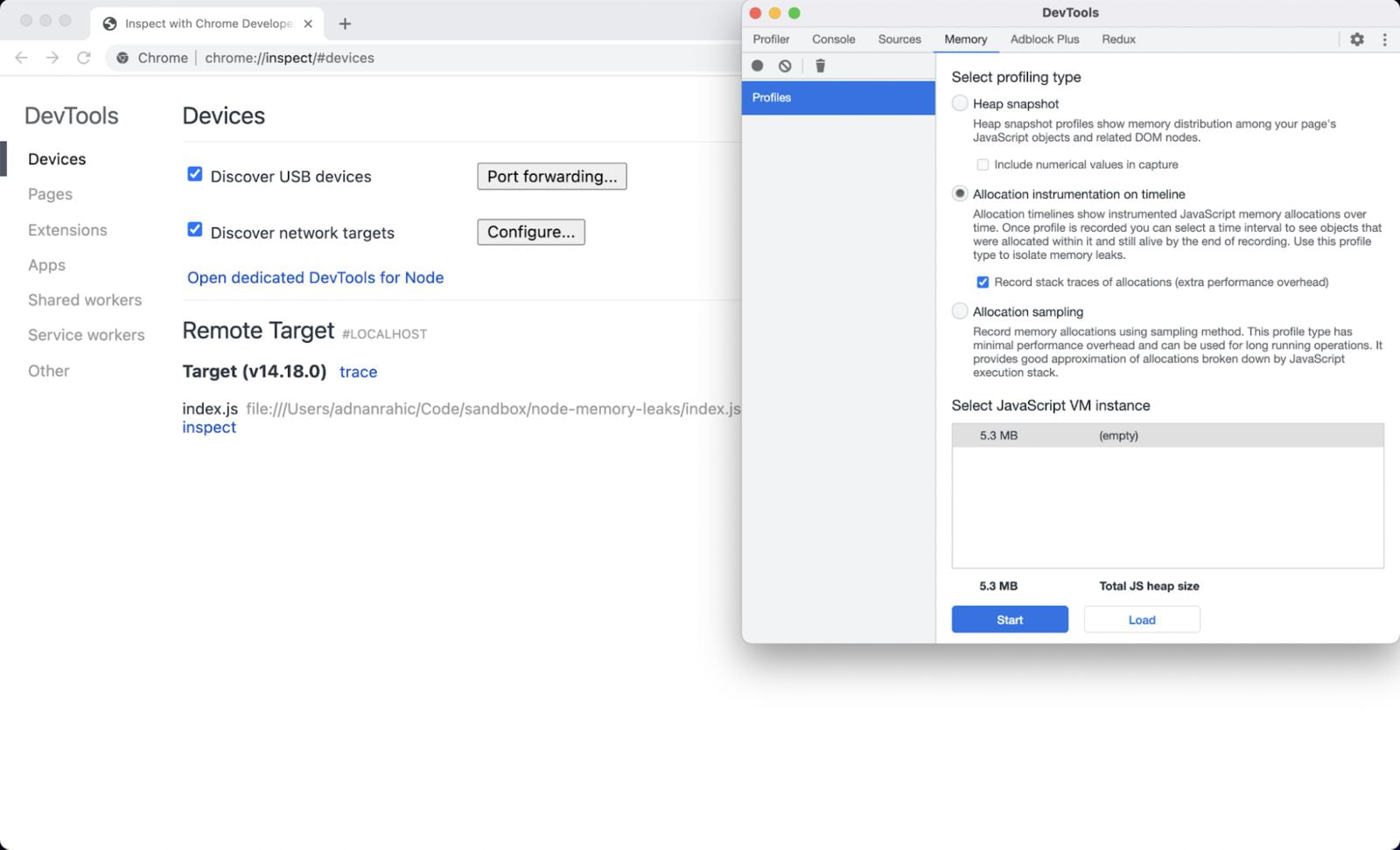
实时观察内存分配
测量内存分配的一个更优化的方法是实时查看,而不是拍摄多个快照。
在这种情况下,你使用时间轴上的分配仪器选项。选择该单选按钮并选中记录分配的堆栈痕迹复选框。这将启动内存使用情况的实时记录。
在这个用例中,我使用loadtest在并发数为10的情况下对样本Express应用运行了1000个请求。
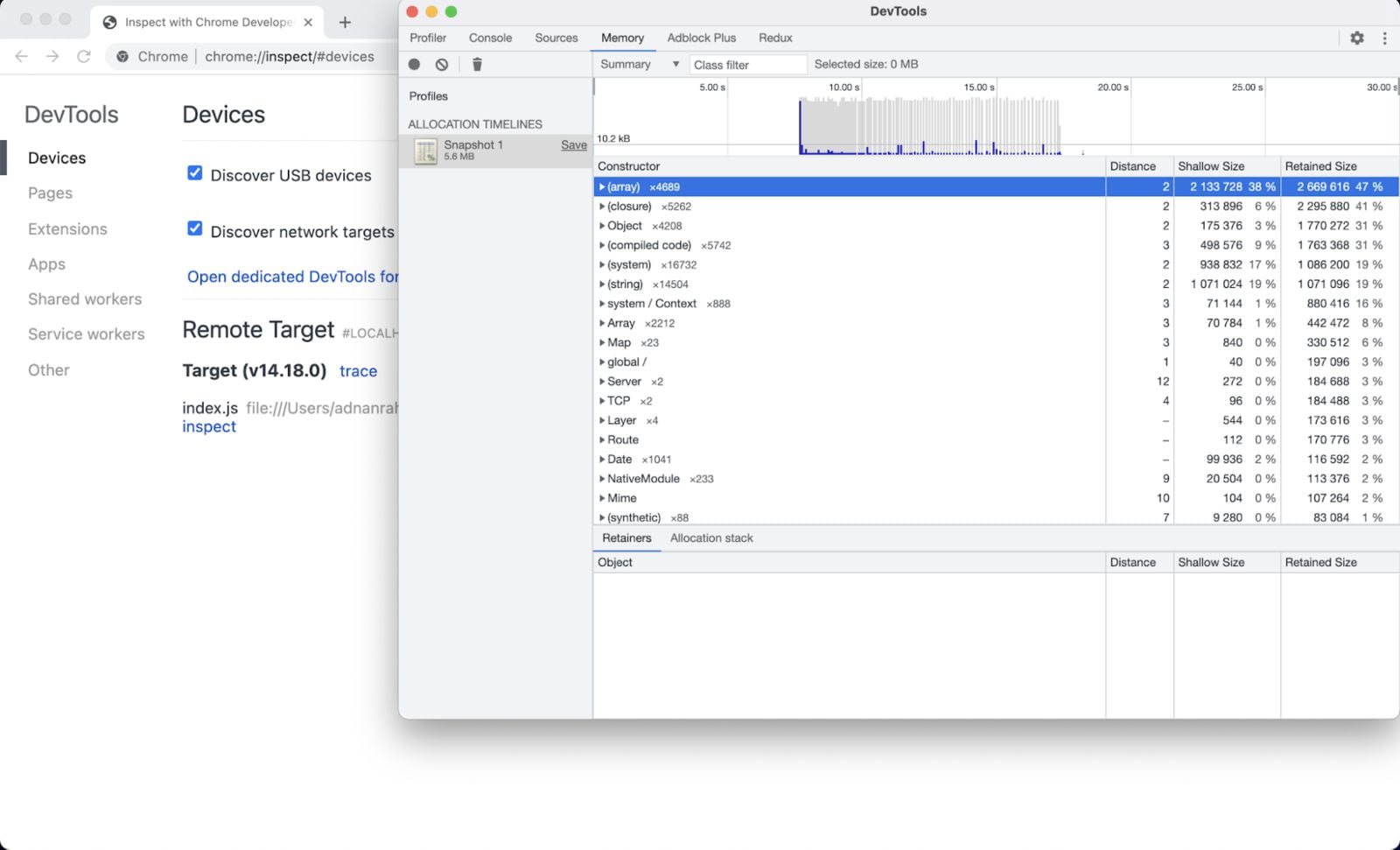
在最初的几个请求中,你可以看到内存分配的峰值。但很明显,大部分内存被分配给了数组、封闭和对象。
监控工具
使用调试工具来观察内存分配和发现内存泄漏是一回事,但一直实时跟踪它是另一回事。
你需要适当的监控工具来给你历史数据一个时间维度,你可以跟踪并获得对你的应用程序如何表现的真正洞察力。
以下是一些可以参考的工具:
如果你想更深入地了解检测内存泄露的众多选项,你可以看看我前段时间写的另一篇文章。Node.js监控工具。
现在,让我们更上一层楼,用合适的监控工具实时观察Node.js的内存泄露。
调试实例:如何使用Sematext查找泄漏点
Sematext Monitoring使你能够通过一个工具来监控你的整个基础设施堆栈,从顶部到底部。你可以实时绘制并监控你的整个基础设施,细化到1分钟以下的粒度。
你还可以实时了解你的Node.js应用程序的性能。这包括垃圾收集、工作线程、HTTP请求和响应延迟、事件循环延迟、CPU和内存使用等等。
你已经准备好设置你的监控了!
首先在Sematext Cloud中创建一个Node.js应用程序。
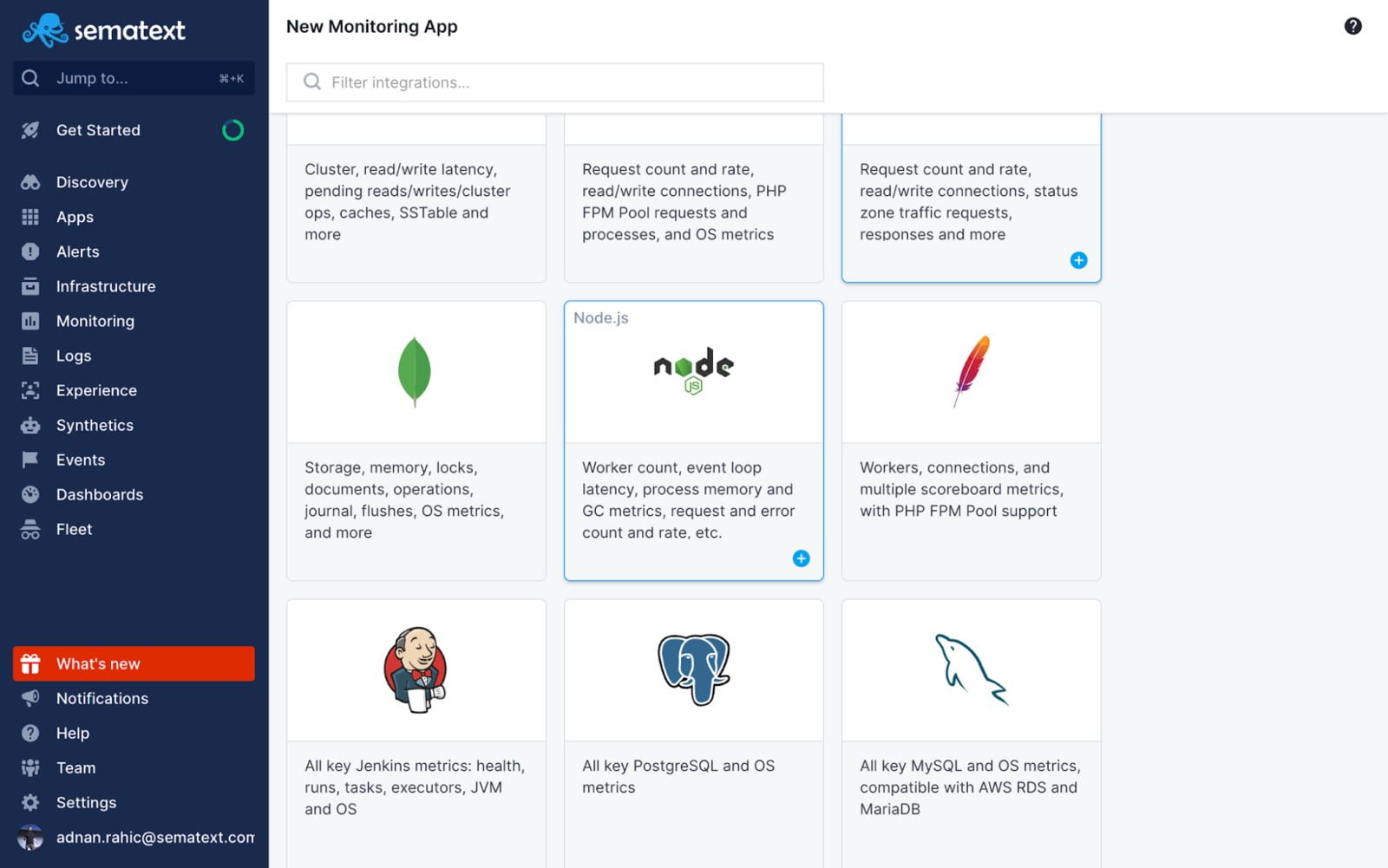
按照用户界面的指示,安装所需的代理,收集infra和Node.js的指标。
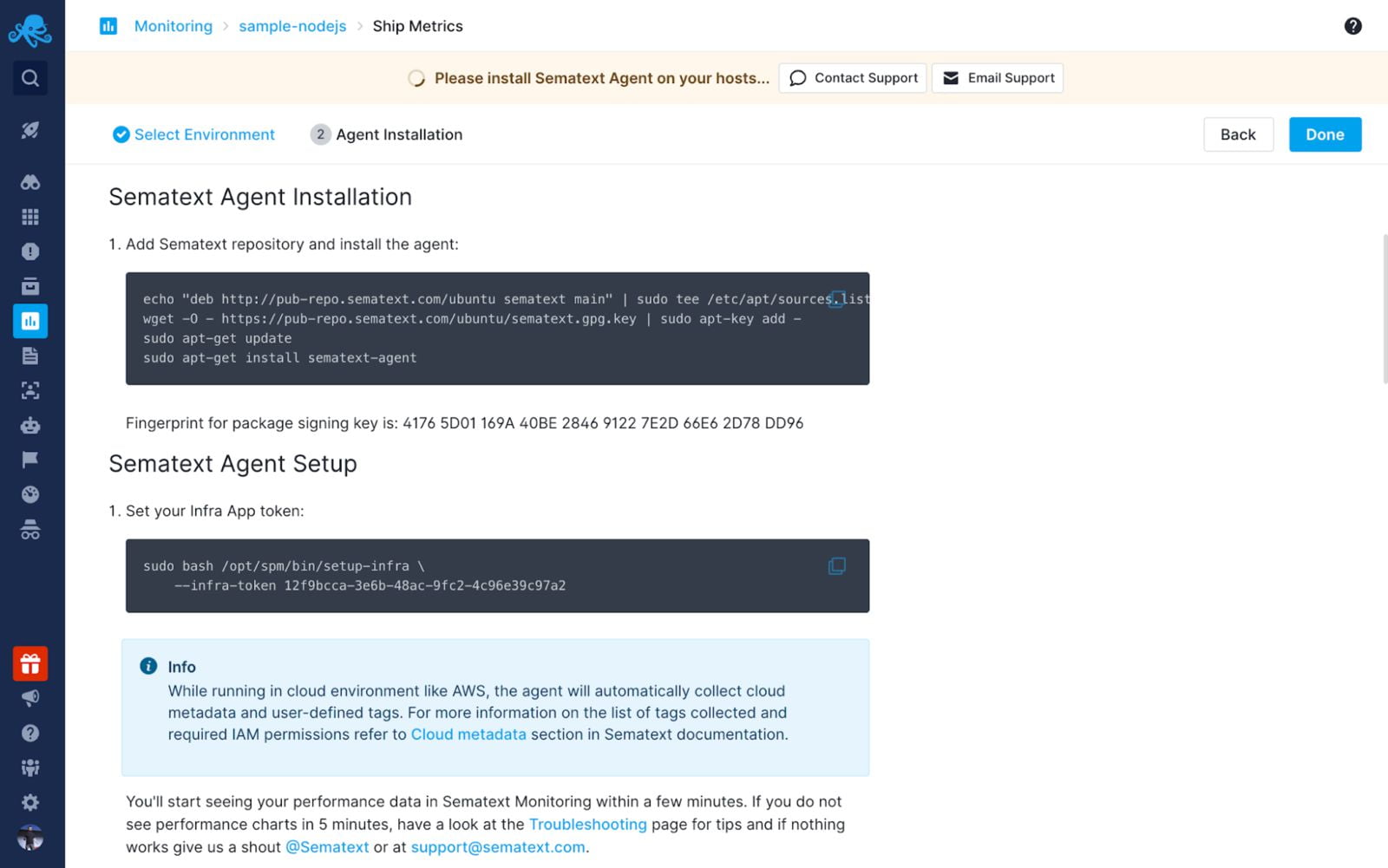
在你项目的根部创建一个.env文件,添加这个片段:
MONITORING_TOKEN=b2b0b02b-xxxx-xxxx-xxxx-11f89c2ccc64
编辑你的应用程序的index.js,要求sematext-agent-express。确保在index.js文件的最顶端包含它:
// Load env vars
require('dotenv').config()
// require stMonitor agent
const { stMonitor } = require('sematext-agent-express')
// Start monitoring metrics
stMonitor.start()
你会看到仪表盘在几分钟内被填充了Node.js的指标。
通过使用垃圾收集和内存图表,你可以全面了解你的应用程序中正在发生的事情。
如果垃圾收集和堆内存不断上升而没有持续释放恒定的内存,你肯定有一个问题。一个快速的解决方案是重新启动你的应用程序。但从长远来看,这是不可能的。你需要应用我上面概述的所有步骤来减少内存泄漏的机会。
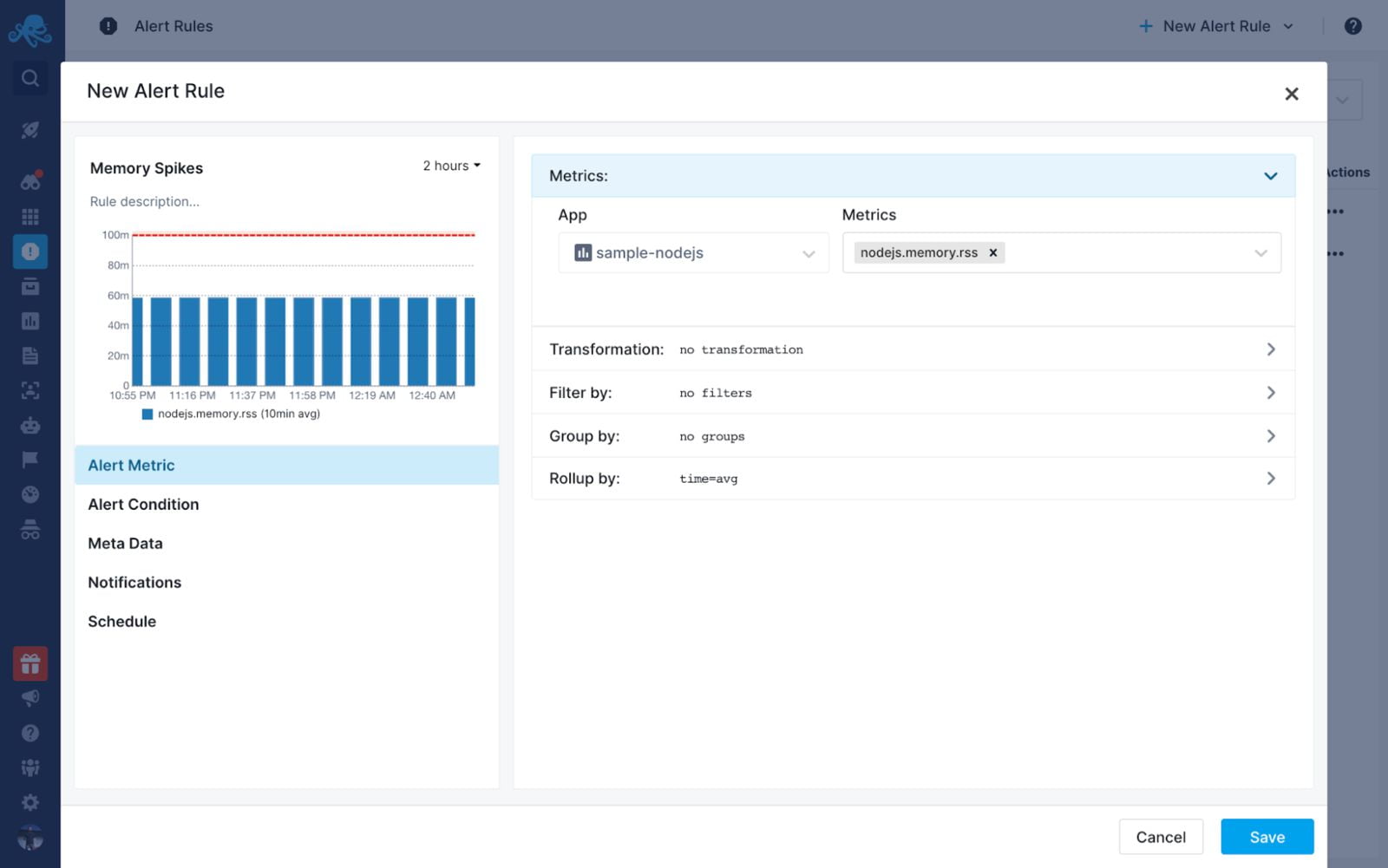
当使用像Sematext这样的工具时,一个很好的选择是当你的内存达到一定的阈值时创建警报。
下面是你如何做的!
点击左侧导航中的警报规则,创建一个新的警报规则,将内存作为一个指标,并将内存的数量设置为阈值。
总结
这肯定是一次情感的过山车之旅。你学会了如何理解和调试Node.js应用程序的内存使用情况,并使用Sematext Monitoring等监控工具来全面了解堆内存和垃圾回收的情况。现在你知道如何检测Node.js的内存泄漏,所以它们永远不会被忽视。希望这能帮助你构建更可靠、性能更好的Node.js应用程序,最终为你节省调试问题的时间和你的理智。
