

嘿,伙计们!在本教程中,我们将建立一个RNN和LSTM模型来帮助我们根据每个角色的名字预测国籍。
让我们先来了解一下我们的数据集。
了解数据集
数据集是一个文本文件,包含人名和名字的国籍,每一行用逗号分开。该数据集包含超过2万个名字和18个独特的国籍,如葡萄牙、爱尔兰、西班牙等。
下面是数据的快照。你可以在这里下载该数据集。

数据集快照 国籍预测器
使用Python中的人名预测国籍
让我们直接进入代码实现。我们将首先导入模块,然后导入我们为这次演示选择的名字和国籍数据集。
第一步:导入模块
在我们开始建立任何模型之前,我们需要将所有需要的库导入我们的程序中。
from io import open
import os, string, random, time, math
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
from IPython.display import clear_output
第二步:加载数据集
为了加载数据集,我们要翻阅数据中的每一行,并创建一个包含姓名和国籍的图元列表。这将使模型在后面的章节中更容易理解这些数据。
languages = []
data = []
X = []
y = []
with open("name2lang.txt", 'r') as f:
#read the dataset
for line in f:
line = line.split(",")
name = line[0].strip()
lang = line[1].strip()
if not lang in languages:
languages.append(lang)
X.append(name)
y.append(lang)
data.append((name, lang))
n_languages = len(languages)
print("Number of Names: ", len(X))
print("Number of Languages: ",n_languages)
print("All Names: ", X)
print("All languages: ",languages)
print("Final Data: ", data)

加载数据集国籍预测器
第三步:训练-测试分离
我们将按照80:20的比例将数据分成训练和测试,其中80%的数据用于训练,其余20%用于测试。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 123, stratify = y)
print("Training Data: ", len(X_train))
print("Testing Data: ", len(X_test))
Training Data: 16040
Testing Data: 4010
第4步:对数据进行编码
字符编码将被用作序列模型的输入,而不是原始文本数据。因此,我们必须对输入进行加密,并在字符层面进行识别。
一旦我们在字符级别创建了编码,我们需要将所有的字符级别的编码连接起来,以获得整个单词的编码。这个过程是针对所有的名字和国籍进行的.CodeText。
all_letters = string.ascii_letters + ".,;"
print(string.ascii_letters)
n_letters = len(all_letters)
def name_rep(name):
rep = torch.zeros(len(name), 1, n_letters)
for index, letter in enumerate(name):
pos = all_letters.find(letter)
rep[index][0][pos] = 1
return rep
上面的函数name_rep为名字生成了一个一次性的编码。首先,我们声明一个零的张量,其输入大小等于名字的长度,外在大小等于我们列表中的全部字符数。
之后,我们在每个字符上循环,以确定一个字母的索引,并将该索引位置值设置为1,其余值为0。
def nat_rep(lang):
return torch.tensor([languages.index(lang)], dtype = torch.long)
编码国籍的逻辑比编码姓名要简单得多。我们只需确定在我们的国籍列表中出现的那个特定国籍的索引来编码国籍。然后,该索引被分配为一个编码。
第5步:建立神经网络模型
我们将使用Pytorch建立一个RNN模型,为了实现这一目标,我们创建了一个类。
init函数(构造函数)帮助我们初始化网络特征,如与隐藏层相关的权重和偏差。
class RNN_net(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN_net, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim = 1)
def forward(self, input_, hidden):
combined = torch.cat((input_, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def init_hidden(self):
return torch.zeros(1, self.hidden_size)
前进函数首先连接一个人物的输入和隐藏表征,然后利用它作为输入,使用i2h、i2o和softmax层计算输出标签。
def infer(net, name):
net.eval()
name_ohe = name_rep(name)
hidden = net.init_hidden()
for i in range(name_ohe.size()[0]):
output, hidden = net(name_ohe[i], hidden)
return output
n_hidden = 128
net = RNN_net(n_letters, n_hidden, n_languages)
output = infer(net, "Adam")
index = torch.argmax(output)
print(output, index)
网络实例和人名被作为输入参数传递给推断函数。我们将把网络设置为评估模式,并在这个函数中计算输入人名的一热表示。
之后,我们将根据隐藏的大小计算出隐藏的表示,并在所有的字符上循环,然后将计算出的隐藏表示返回给网络。
最后,我们将计算输出,也就是这个人的国籍。
第6步:计算RNN模型的准确度
在继续训练模型之前,让我们创建一个函数来计算模型的准确性。
为了实现这一点,我们将创建一个评估函数,该函数将把以下内容作为输入。
- 网络实例
- 数据点的数量
- k的值
- X和Y的测试数据
def dataloader(npoints, X_, y_):
to_ret = []
for i in range(npoints):
index_ = np.random.randint(len(X_))
name, lang = X_[index_], y_[index_]
to_ret.append((name, lang, name_rep(name), nat_rep(lang)))
return to_ret
def eval(net, n_points, k, X_, y_):
data_ = dataloader(n_points, X_, y_)
correct = 0
for name, language, name_ohe, lang_rep in data_:
output = infer(net, name)
val, indices = output.topk(k)
if lang_rep in indices:
correct += 1
accuracy = correct/n_points
return accuracy
在该函数中,我们将执行以下操作。
- 使用
data loader,加载数据。 - 遍历数据加载器中的所有人名。
- 在输入上调用模型并获得输出。
- 计算预测的类别。
- 计算正确预测的类的总数
- 返回最后的百分比。
第7步:训练RNN模型
为了训练模型,我们将编码一个简单的函数来训练我们的网络。
def train(net, opt, criterion, n_points):
opt.zero_grad()
total_loss = 0
data_ = dataloader(n_points, X_train, y_train)
for name, language, name_ohe, lang_rep in data_:
hidden = net.init_hidden()
for i in range(name_ohe.size()[0]):
output, hidden = net(name_ohe[i], hidden)
loss = criterion(output, lang_rep)
loss.backward(retain_graph=True)
total_loss += loss
opt.step()
return total_loss/n_points
def train_setup(net, lr = 0.01, n_batches = 100, batch_size = 10, momentum = 0.9, display_freq = 5):
criterion = nn.NLLLoss()
opt = optim.SGD(net.parameters(), lr = lr, momentum = momentum)
loss_arr = np.zeros(n_batches + 1)
for i in range(n_batches):
loss_arr[i + 1] = (loss_arr[i]*i + train(net, opt, criterion, batch_size))/(i + 1)
if i%display_freq == display_freq - 1:
clear_output(wait = True)
print("Iteration number ", i + 1, "Top - 1 Accuracy:", round(eval(net, len(X_test), 1, X_test, y_test),4), 'Top-2 Accuracy:', round(eval(net, len(X_test), 2, X_test, y_test),4), 'Loss:', round(loss_arr[i]),4)
plt.figure()
plt.plot(loss_arr[1:i], "-*")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.show()
print("\n\n")
n_hidden = 128
net = RNN_net(n_letters, n_hidden, n_languages)
train_setup(net, lr = 0.0005, n_batches = 100, batch_size = 256)
在训练了100个批次的模型后,我们的RNN模型能够达到66.5%的top-1准确率和79%的top-2准确率。

损失图 国籍预测器
第8步:对LSTM模型进行训练
我们还将讨论如何实现LSTM模型来对一个人的名字进行国籍分类。 为了实现这一点,我们将利用Pytorch并创建一个自定义的LSTM类。
class LSTM_net(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM_net, self).__init__()
self.hidden_size = hidden_size
self.lstm_cell = nn.LSTM(input_size, hidden_size) #LSTM cell
self.h2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim = 2)
def forward(self, input_, hidden):
out, hidden = self.lstm_cell(input_.view(1, 1, -1), hidden)
output = self.h2o(hidden[0])
output = self.softmax(output)
return output.view(1, -1), hidden
def init_hidden(self):
return (torch.zeros(1, 1, self.hidden_size), torch.zeros(1, 1, self.hidden_size))
n_hidden = 128
net = LSTM_net(n_letters, n_hidden, n_languages)
train_setup(net, lr = 0.0005, n_batches = 100, batch_size = 256)
在训练了100批模型后,我们能够用LSTM模型达到52.6%的最高1级准确率和66.9%的最高2级准确率。
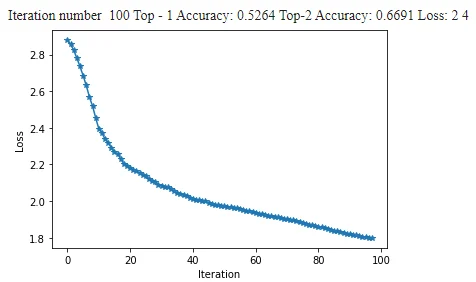
损失图 国籍预测器 LSTM
结语
祝贺你!你刚刚学会了如何使用Pytorch建立一个国籍分类模型。希望你喜欢它!😇
谢谢你抽出时间!希望你能学到新的东西!!😄
