

本文将介绍安装和使用EasyOCR命令行工具和Python模块的指南。作为一个免费和开源的应用程序,它可以用来识别和提取图像中的文本。它使用光学字符识别(OCR)技术和各种不同的算法和语言模型来检测文本。
EasyOCR的主要特点
EasyOCR可以检测80多种语言和文字的文本。它包括这些语言的预训练模型,但你可以使用EasyOCR从头开始训练你自己的模型。除了图像中发现的数字和印刷文本内容,EasyOCR还可以检测和提取手写文本。EasyOCR的其他主要功能包括:能够一次批量处理多个图像,能够限制和阻止某种语言中的某些字符,能够将提取的行转换成段落,能够调整图像的大小和放大以提高检测的准确性,等等。
在Linux中安装EasyOCR
你可以使用pip软件包管理器在Linux中安装EasyOCR。要在Ubuntu中安装pip软件包管理器,请使用以下命令。
$ sudo apt install python3-pip
Pip包管理器在许多Linux发行版的官方仓库中都有,所以你可以从股票包管理器中安装它。
在你成功安装了pip软件包管理器后,运行以下命令在Linux中安装EasyOCR。
$ pip3 install easyocr
在Linux中使用EasyOCR
下面的图片将被用来通过下面解释的各种EasyOCR命令来提取文本。

要从上述图片中提取文本,你需要运行以下格式的命令。
$ easyocr -l en -f image.png
第一个选项"-l "可以用来指定你想被EasyOCR捕获的文本内容的语言。你可以使用命令分隔的语言代码指定多种语言。开关"-f "用于指定输入图像文件。
运行上述命令后,你应该在终端看到以下输出。
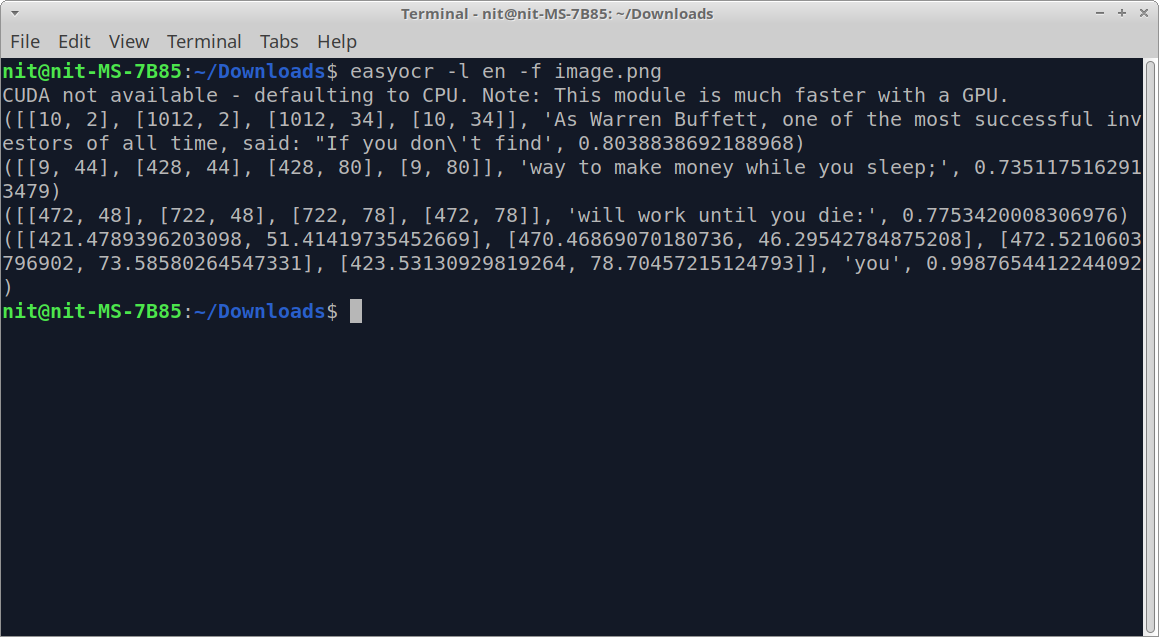
该输出显示了某些数字和从图像中提取的文本。这个输出可以按以下格式阅读:单个文本片段的坐标>检测到的文本>置信度。因此,最左边的数字代表已识别的文本框的坐标,而最右边的数字表示提取的文本的准确程度。
如果你只想以人类可读的形式获得检测到的文本,在上述命令中加入"-detail 0 "开关。
$ easyocr -l en --detail 0 -f image.png
运行上述命令后,你应该得到一些类似这样的输出。
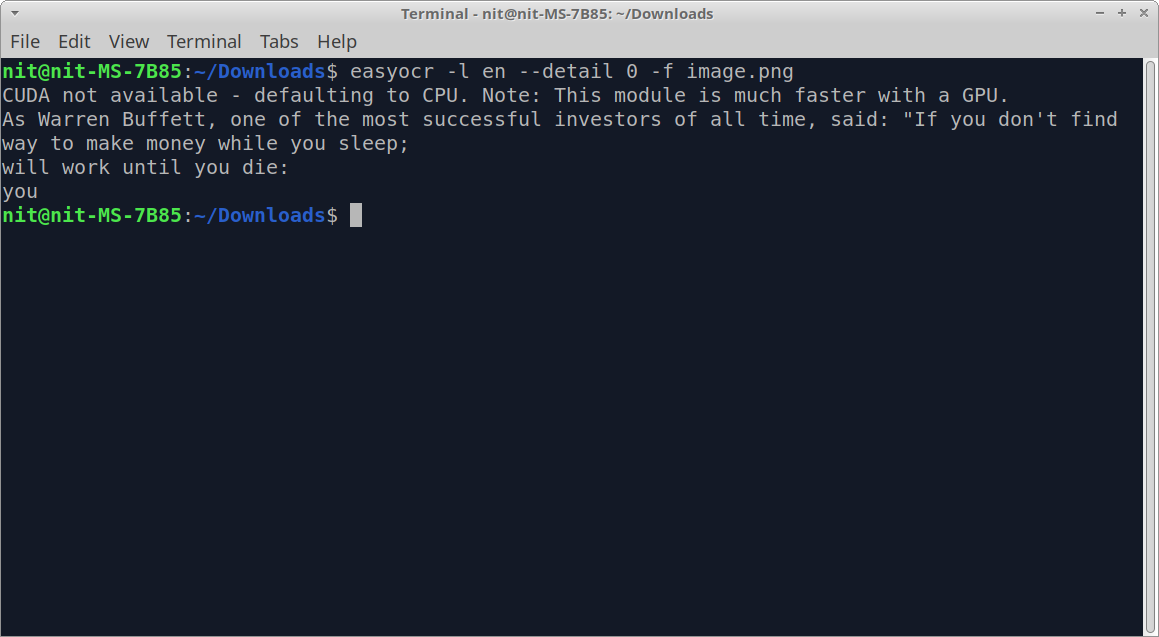
正如你在输出中所看到的,所提取的文本没有按照正确的顺序排列。 你可以尝试使用"-paragraph True "命令行选项,将各个片段和句子按正确的顺序连接起来。
$ easyocr -l en --detail 0 --paragraph True -f image.png
运行上述命令后,你应该得到一些类似这样的输出。
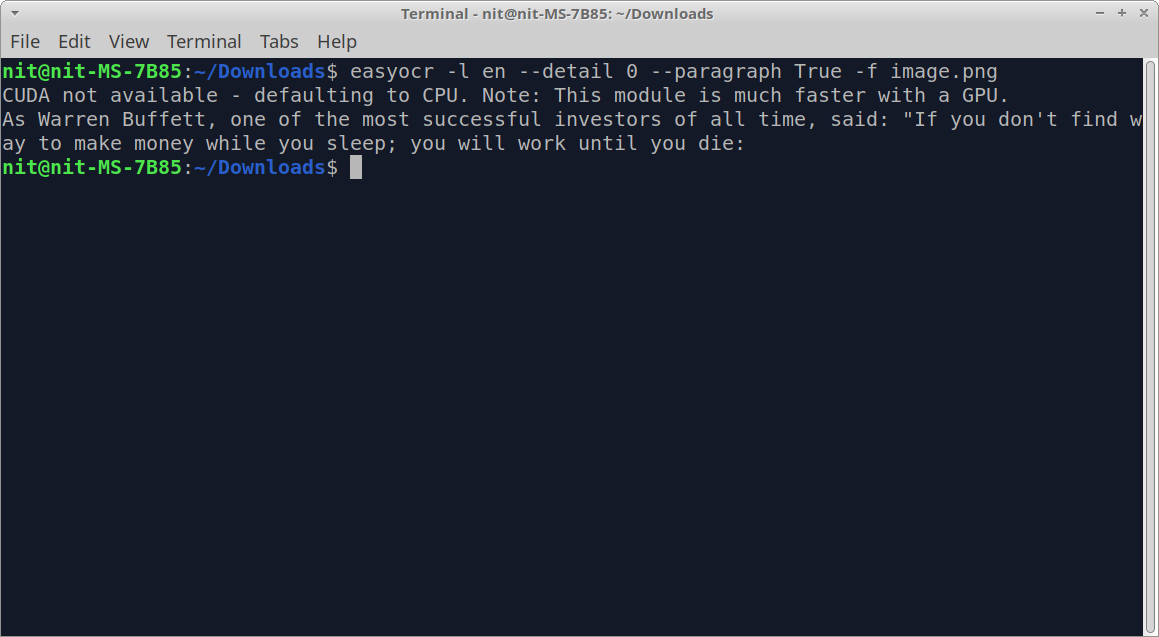
请注意,根据图像的质量和清晰度以及图像的文本内容,在提取的文本中可能总是存在某些不准确的地方,你可能不得不进行手动修正来解决这些问题。
要把识别出的文本保存到外部文件中,请使用">"符号并提供一个输出文件的名称。下面是一个命令的例子。
$ easyocr -l en --detail 0 --paragraph True -f image.png > output.txt
要了解更多关于EasyOCR支持的所有命令行选项,请使用以下命令。
$ easyocr --help
在Python程序中使用EasyOCR
EasyOCR也可以作为一个Python库,所以你可以在你的Python程序中导入其主要模块。下面是一个代码样本,说明它在Python程序中的使用。
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('image.png', detail=0, paragraph=True)
with open("output.txt", "w") as f:
for line in result:
print(line, file=f)
第一条语句是用来在你的Python程序中导入 "easyocr "模块。接下来,通过提供EasyOCR支持的语言列表作为主要参数,创建一个新的 "阅读器 "类(基类)实例。如果你的图像包含多种语言的文本,你可以在列表中添加更多的语言代码。接下来,"readtext "方法在 "阅读器 "实例上被调用,图像文件的路径被作为第一个参数提供。这个方法将识别并从提供的图像中提取文本。两个可选参数,"细节 "和 "段落 "与上面解释的命令行选项相同。它们通过删除不必要的元素来简化文本。
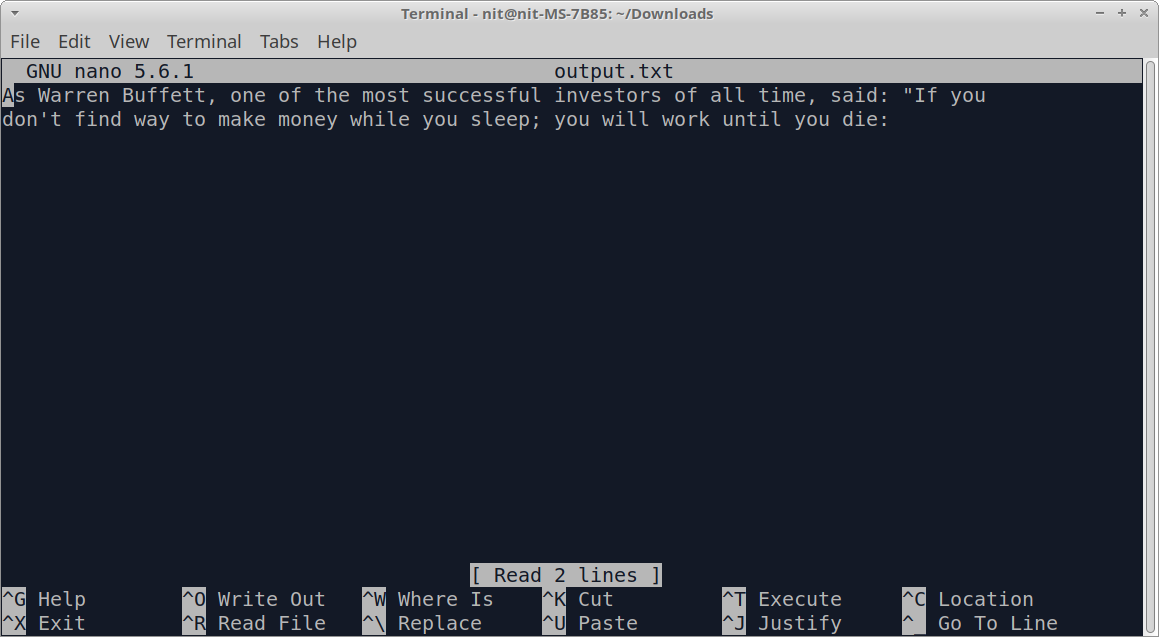
运行上述命令后,你应该在 "output.txt "文件中看到以下一行。
结论
EasyOCR是一个命令行文本提取工具,它带有多种语言的预训练模型。这使得终端用户可以很容易地从图像中快速识别和提取文本,而不需要自己的语言模型。它还提供了识别和标记文字周围的边界框的详细坐标,使得分析单个文本变得容易。
