

创建单词的表征是为了捕捉它们的意义、语义关系和不同单词的上下文;在这里,不同的单词嵌入技术起到了作用。词语嵌入是一种用来提供密集的词语向量表征的方法,它可以捕捉到一些关于自己的背景词语。这些是简单的词袋模型的改进版,如单词计数和频率计数器,大多代表稀疏的向量。
词嵌入使用一种算法来训练固定长度的密集向量和基于大型文本语料库的连续价值向量。每个词代表向量空间中的一个点,这些点被学习并通过保留语义关系围绕目标词移动。词的向量空间表示提供了一个投影,具有相似含义的词在该空间内被聚类。
嵌入的使用超过了其他文本表示技术,如one-hot encodes,TF-IDF, Bag-of-Words等,是导致深度神经网络上许多杰出表现的关键方法之一,如神经机器翻译等问题。此外,一些单词嵌入算法,如GloVe和word2vec,也有可能产生神经网络达到的性能状态。
今天在这篇文章中,我们将看看斯坦福大学给出的GloVe单词嵌入模型。我们将加载预先训练好的模型,通过给定的单词找到相似的单词,并尝试用单词实现数学类比,并将向量可视化。
实现GloVe
GloVe是全局向量(Global Vectors)的缩写,用于表示单词。它是由斯坦福大学的研究人员开发的一种无监督学习算法,旨在通过聚合给定语料库的全局词共现矩阵来生成词嵌入。
GloVe词嵌入的基本思想是通过统计学得出词与词之间的关系。 与发生率矩阵不同,共发生率矩阵告诉你一个特定的词对一起出现的频率。共现矩阵中的每个值都代表一对一起出现的词。
让我们看看如何解释共现矩阵。
以下面这个矩阵为例:

考虑到两个语料库中的独特词,形成的矩阵写在第1块和第2块。从cat这个词开始垂直移动;在第1块中,cat这个词没有重复,同样在第2块中也没有重复。转到下一对cat-fast,它在两个区块中都出现过一次,而且这对词在给定语料库中出现过两次。如果你再看一个配对,cat-the,"the "和cat一起出现了多少次,也就是3次。类似地,整个矩阵就形成了。
现在,当你计算两对词之间的概率比时,比如你有(cat/fast)=1和(cat/the)=0.5的概率;当你计算这些的比率时,结果是2,这说明'fast'比'the'更相关
这就是GloVe预训练词嵌入背后的想法,它被表达为:
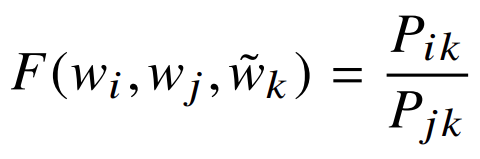
要开始使用GloVe,首先我们要下载托管在nlp.stanford.edu/projects/gl… 的预训练模型;总共有四个预训练模型;你可以选择任何你想要的。如果文件没有被下载,请尝试在隐身标签中打开下载链接。
在这里,我们选择下载维基百科2014年的模型,它的大小约为800MB。让我们开始编写代码。
导入所有的依赖性
import os
import urllib.request
import matplotlib.pyplot as plt
from scipy import spatial
from sklearn.manifold import TSNE
import numpy as np
在Colab或Jupyter笔记本中,我们可以用urllib直接访问下面的URL中的文件:
urllib.request.urlretrieve('https://nlp.stanford.edu/data/glove.6B.zip','g
love.6B.zip')
由于它是一个压缩文件,我们可以通过在下面的命令中提到文件的来源和解压文件的目的地来简单地解压它:
!unzip "/content/glove.6B.zip" -d "/content/"
有五个文本文件代表单词和其相应的不同维度的向量,如50维、100维等。我们在这里使用glove.6B.200d.txt,200d指的是每个词的200维。
我们来看看文件中的一行和它的维度:
after 0.38315 -0.3561 -0.1283 -0.19527 0.047629...
现在要创建单词嵌入;首先,我们需要创建一个字典,保存每个单词及其各自的向量;这可以通过循环浏览文件简单实现,这将提取单词和向量,如下所示:
emmbed_dict = {}
with open('/content/glove.6B.200d.txt','r') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.asarray(values[1:],'float32')
emmbed_dict[word]=vector
字典的样本看起来如下:
现在让我们通过查询找到一个类似的词;在这个方法中,我们将使用欧氏距离来衡量这两个词之间的距离。使用这个欧氏距离作为排序函数中的键和emmbed_dict的键一起,我们可以得到类似的词,如下图:
def find_similar_word(emmbedes):
nearest = sorted(emmbed_dict.keys(), key=lambda word: spatial.distance.euclidean(emmbed_dict[word], emmbedes))
return nearest
现在让我们找出 "河流 "这个词的前10个相似词:
find_similar_word(emmbed_dict['river'])[0:10]

我们并不局限于只得到相似的词,我们也可以尝试通过组合两个或更多的词来搜索单词:
find_similar_word(emmbed_dict['king'] + emmbed_dict['queen'] + emmbed_dict['prince'])[0:10]

为了实现向量的可视化,我们使用了一种叫做分布式随机梯度邻接嵌入的方法,简称TSNE,它被用来减少数据维度。在这里,我们要处理的是200维的数据,TSNE将按照我们的要求把它分解成各个部分;我们将把它分成两个维度。
在训练和拟合TSNE模型之后,就是绘制矢量图;我们使用的是散点图,因为矢量是分布在空间上的。matplotlib库可以做到这一点。对每一个点进行注释,将给出一个更有洞察力的矢量表示:
distri = TSNE(n_components=2)
words = list(emmbed_dict.keys())
vectors = [emmbed_dict[word] for word in words]
y = distri.fit_transform(vectors[700:850])
plt.figure(figsize=(14,8))
plt.scatter(y[:, 0],y[:,1])
for label,x,y in zip(words,y[:, 0],y[:,1]):
plt.annotate(label,xy=(x,y),xytext=(0,0),textcoords='offset points')
plt.show()

结语
从这篇文章中,我们已经看到了GloVe等矢量表示技术是如何被用来表示具有语义的给定语料库的。此外,我们还看到了GloVe背后的主要工作思路,即共现矩阵,以及GloVe如何基于概率考虑特定的词而不是其他的词。
