

你有没有注意到,当我们在搜索引擎中搜索任何一句话并开始填写小部件时,它会自动显示其余的东西或给我们推荐其余的查询内容?他们是如何做到这些的呢?在这里的图片中,有一件事进入了关系提取的部分。关系提取模型是专门为完成预测实体的属性以及单词和句子之间的关系的任务而制作的。例如,从 "Elon Musk创立了Tesla "这个句子中提取实体--"Elon Musk""创立了""Tesla "来理解 "Elon Musk是Tesla的创始人 "这个句子,与第一个句子类似。因此,关系提取是一些自然语言处理任务的关键组成部分之一。
知识图谱的构建发挥着巨大的作用;我们可以通过使用关系提取找到许多关系事实。利用这些事实,我们可以扩展知识图谱,这是机器学习模型理解人类世界的一个路径。同时,代替NLP,它可以被用于问题回答、推荐系统、搜索引擎和总结应用。
有各种类型的数据集可用于这种类型的建模,如DocRED、TACRED、ACE 2005。而且,各种模型和框架也已经在它们上面进行了训练,如COKE、SSAN等。任何简单架构的基本结构,我们称之为HRERE(神经关系提取的异质表示):
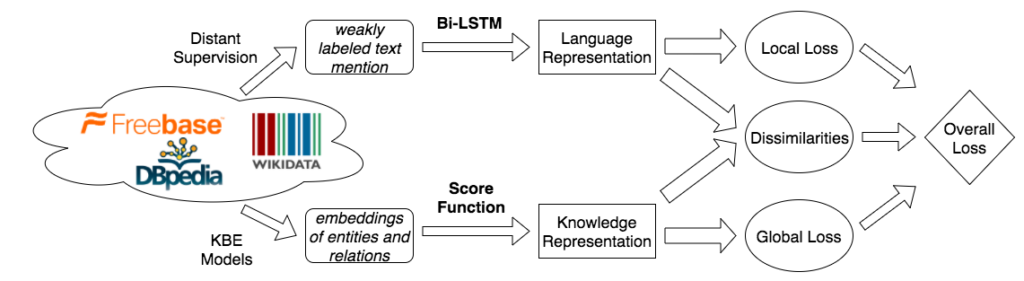
图片来源
大致上有四种关系提取任务,我们可以使用不同的算法来执行:
- 句子层面的关系提取是最常出现的关系提取任务。在给定的句子中,我们使用预定义的关系集找到两个标记实体之间的关系。TACRED 是这项任务最常使用的数据集。

图片来源
- 袋级关系提取--在这项任务中,我们使用现有的知识图谱来寻找实体之间的关系。有许多可用的知识图谱,如freebase和wikidata。其中已经包括了实体之间的关系。在这种任务中,我们最常使用的数据是NYT10。

图片来源
- Few-Shot Relation Extraction - 这种类型的学习是用来调整modelfaster以适应新的关系。我们也可以说它是通过使用非常小的数据集的样本,对人类的学习过程的概念进行工作。在这种关系提取的任务中,FewRel主要被用作数据。下面的图片可以理解基本的方法。

图片来源
- 文档级别的关系提取--这项任务的重点是提取单一实体对的句内关系,以加速学习。在DocRED 中,我们可以找到这种类型的方法的数据集。该方法可以显示在下面的图片中。
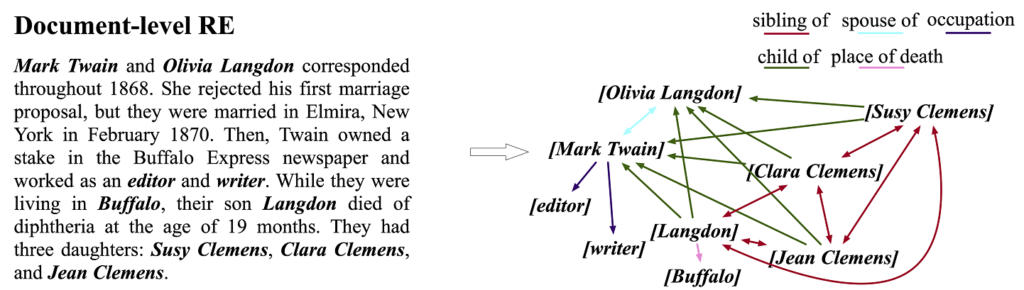
图片来源
什么是OpenNRE?
OpenNRE是一个开源的工具包,用于进行神经关系提取。下面的图片可以理解NRE的基本算法:

图片来源
OpenNRE提供了一个实现关系提取模型的框架,作为一个开源和可扩展的工具包。这个软件包提供了以下设施
- 从事关系提取的新人
- 开发人员提供了一个易于使用的环境,可以在任何生产中部署,而不需要对模型进行培训。而且,这些模型的性能也非常高
- 研究人员可以很容易地使用这些包来进行实验
在该软件包中,有各种模型是在wiki80、wiki180、TACRED数据集上训练的。要了解更多关于这些数据集的信息,读者可以通过这个链接。 这个软件包提供了基于卷积神经网络和BIRT算法的高性能模型。
代码实现OpenNRE
让我们使用google colab来快速启动OpenNRE。
在安装工具包之前,我们需要为笔记本启动一个GPU;这将帮助我们为我们的程序提供速度。为了启动GPU,我们可以直接进入运行时按钮;之后,点击改变运行时类型。接下来,你会得到小部件硬件加速器,选择GPU并点击保存:

在这里,在colab中我们要克隆包;这就是为什么我们需要在笔记本中挂载我们的驱动器。下面的例子将告诉你如何使用授权码在你的运行时间上挂载驱动器:
from google.colab import drive
drive.mount('/content/drive')
输出:

现在我们可以开始试用该软件包了。
我们可以用下面的命令克隆OpenNRE资源库:
!git clone https://github.com/thunlp/OpenNRE.git
输出:

为了使用我们克隆的模型,我们需要将笔记本引导到我们的软件包所在的文件夹。
cd OpenNRE
输出:
使用其requirement.txt文件安装软件包:
`!pip install -r requirements.txt`
输出:

现在我们准备使用OpenNRE。
导入OpenNRE:
`import opennre`
在Wiki180数据集上用CNN编码器从软件包模式加载一个预训练的模型
`model = opennre.get_model('wiki80_cnn_softmax')`
输出:

这将需要几分钟的时间来加载模型。加载后,我们将使用推断命令的模型进行关系提取。
`model.infer({'text': 'He was the son of ashok, and grandson of rahul.', 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})`
输出:
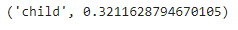
这里我们可以看到模型的预测是一个孩子,置信度大约为32%;分数很低,但预测结果几乎是令人满意的,因为模型已经告诉我们这个儿子和这个孩子有关系。
让我们检查一下该包的另一个模型。
加载该模型:
`model = opennre.get_model('wiki80_bert_softmax')`
输出:

这里我加载了软件包中的一个模型,这个模型是用wiki180数据上的birt编码器训练而成的。
检查该模型的性能:
`model.infer({'text': 'He was the son of ashok, and grandson of rahul.', 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})`
输出:
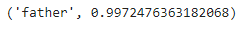
在这里我们可以看到,它又预测出了正确的结果,而且信心十足地告诉我们Rahul是Ashok的父亲,Ashok是他的父亲。该模型的置信度约为99%,这也是非常令人满意的。
还有一个模型是内置在名为wiki180_bertentity_softmax的包中的,它也是用BIRT编码器制作的。
加载该模型:
`model = opennre.get_model('wiki80_bertentity_softmax')`
输出:
检查模型的性能:
`model.infer({'text': 'He was the son of ashok, and grandson of rahul.', 'h': {'pos': (18, 46)}, 't': {'pos': (78, 91)}})`
输出:

这个模型也说子词与子词的关系,预测的置信度也很好。
在这里,我们在文章中看到,OpenNRE包的所有预训练模型的性能都很高,模型的预测也很好。与其他软件包不同,它非常容易使用。如果我们进入软件包的例子文件夹,我们会看到有各种可用的模型,我们可以根据自己的要求来编辑和使用。因为它是开源的,所以在部署预训练的模型时不会有任何费用。我鼓励你去阅读工具包的文档,并尝试用OpenNRE进行更多的操作。
