

在本教程中,我们将使用Selenium制作一个网络搜刮器,从任何网站获取数据。Selenium是一个开源项目,用于实现浏览器的自动化。它为自动化提供了大量的工具和库。我们可以用各种语言编写脚本来实现浏览器的自动化,如java、python、c#、Kotlin等。
实现Web Scraper来获取数据
在我们的例子中,我们将通过从IMDB获取最受欢迎的电影列表来演示python网络刮削。
第一步-导入模块
为了开始我们的网络刮削器,我们要导入Selenium和相关模块。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
第2步-初始化WebDriver
为了实现浏览器的自动化,我们需要下载我们打算使用的网络浏览器的WebDriver。在我们的案例中,我使用的是谷歌浏览器,所以我下载了chrome WebDriver。
请确保Chrome版本和WebDriver版本相同。我们需要在Chrome方法中传递WebDriver的路径,如下图所示。
driver = webdriver.Chrome('C://software/chromedriver.exe')
步骤3-通过Python访问网站
为了访问网站数据,我们需要打开我们要搜刮的网站URL。
要做到这一点,我们使用get方法,并将网站的URL作为方法的参数传递。在我们的例子中,它是IMDB的最受欢迎的电影的网页。
driver.get("https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm")
当我们运行这段代码时,它将在我们的计算机系统中用传递的地址(URL)网站打开网页浏览器。
第4步-找到你要搜刮的具体信息
在我们的案例中,我们要找的是IMDB中评分最高的电影的名字,所以我们要找到HTML元素的XPath。
XPath可以理解为HTML文档中某些特定事件(对象)的路径位置,它被用来寻找或定位网页上的元素。
要获得一个元素的XPath,需要进入浏览器的检查工具,然后使用选择器工具选择那个特定的工具(我们需要获得其路径),在HTML代码上点击右键,然后选择复制XPath。
 检查网页中的元素
检查网页中的元素
在我们的例子中,在检查了电影的名字元素后,似乎每个名字都在类中--titleColumn,所以我们可以在代码中把它作为xpath传递,访问电影的名字。
<td class="titleColumn">
<a href="" title="Chloé Zhao (dir.), Gemma Chan, Richard Madden">Eternals</a>
</td>
我们将使用方法 find_elements_by_xpath() 来找到每个titleColumn类。
movies = driver.find_elements_by_xpath('//td[@class="titleColumn"]')
注意:每个xpath前面都有双斜线。- '//td**[@class=**"titleColumn"]'
第5步-将数据存储在一个Python列表中
现在我们可以成功地获取所需的信息,我们需要把它存储在一个变量或数据结构中,以便在代码的后面部分进行检索和处理。我们可以将搜刮到的数据存储在各种数据结构中,如数组、列表、元组、字典。
在这里,将我们搜刮到的数据(最高评分的电影名称)存储在一个列表中。要做到这一点,我们可以写一个循环,遍历每个电影名称并将其存储在一个列表中。
movies_list是一个空的列表,包含所有从网站上获取的信息。
movies_list = []
for p in range(len(movies)):
movies_list.append(movies[p].text)
最后,用于网络搜刮网站数据的python代码是
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('C://software/chromedriver.exe')
driver.get('https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm')
movies = driver.find_elements_by_xpath('//td[@class="titleColumn"]')
movies_list = []
for p in range(len(movies)):
movies_list.append(movies[p].text)
如果我们在一行中打印movies_list列表,那么
print(*movies_list, sep = "\n")
我们得到的输出是这样的:
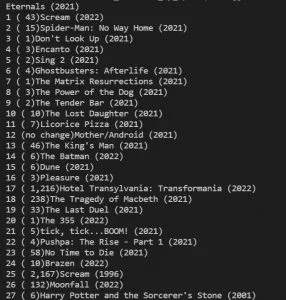
刮取的网络数据输出
总结
这就是如何使用Selenium和Python从几乎所有的网站刮取网站数据。只要你找到正确的XPath,并能识别网站使用的模式,就可以非常容易地获取任何网站上的所有数据。
来吧,做同样的实验,让我们知道我希望你喜欢这个教程。请关注AskPython.com,了解更多有趣的教程。
