

如果你能在手机上监控你的Colab、Kaggle或AzureML机器学习项目,会怎么样?你将能够在飞行中检查你的模型--甚至在散步的时候🚶。
如果你是一个ML开发人员,你知道训练模型可以很容易地花费很长的时间。如果从你的手机上监控这一切,那该有多酷?
嗯,你可以做到这一点--而且是在<5行代码中。
为什么远程监控你的模型会有帮助
在开始教程并向你展示它是如何工作的之前,让我简单介绍一下你可以用TF Watcher做什么,这是一个开源项目,我们将用来监控我们的ML工作:
- 与你的ML工作流无缝集成,所以你不需要改变你工作流中的任何其他代码就可以使其发挥作用
- 你所有的可视化和仪表盘都是实时的
- 你可能想与你的同事分享你的实时仪表盘或之前运行的仪表盘,这也允许你创建可共享的链接。
- 这是一个PWA,可以让你在有限的能力范围内离线监控你的模型
- 你还可以精确控制你想记录指标的时间
如何在手机上监控你的ML项目
现在让我们来看看如何用谷歌Colab在移动设备上监控你的模型的教程。我将向你展示如何在Google Colab中使用这个工具,所以任何人都可以尝试,但你几乎可以在任何地方(甚至在你的本地机器上)复制这个。
请随时关注这个colab笔记本。
安装tf-watcher Python包
为了监测移动设备上的机器学习作业,你需要安装tf-watcher Python包。这是我建立的一个开源的Python包,你可以在这个GitHub repo中找到源代码。
要从PyPI安装Python包,在你的笔记本单元中运行以下命令:
!pip install tf-watcher
如何创建一个简单的模型
在这个例子中,我们将看到如何监控一个训练工作--但你也可以用这个包来监控你的评估或预测工作。你很快就会看到你如何轻松地指定你想要监控的指标。
在这个例子中,我们将使用时尚MNIST,一个由10个时尚类别的60,000张灰度图像组成的简单数据集。我们首先加载数据集,然后做一些简单的预处理以进一步加快我们的例子。
然而,你可以在你更复杂的实验中使用我们在本文中谈到的一切。
让我们来获取数据集:
import tensorflow as tf
# Load example MNIST data and pre-process it
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 784).astype("float32") / 255.0
x_test = x_test.reshape(-1, 784).astype("float32") / 255.0
# Limit the data to 1000 samples to make it faster
x_train = x_train[:1000]
y_train = y_train[:1000]
x_test = x_test[:1000]
y_test = y_test[:1000]
取出时尚MNIST数据集
现在我们将创建一个简单的神经网络,它只有一个Dense 层。我将向你展示如何使用TensorFlow的Sequential API,但这在使用Functional API或子类化模型时也以完全相同的方式运作:
# Define the Keras model
def get_model():
model = keras.Sequential()
model.add(keras.layers.Dense(1, input_dim=784))
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=0.1),
loss="mean_squared_error",
metrics=["accuracy"],
)
return model
创建一个简单的模型
你可能已经注意到,在编译我们的模型时,我们还指定了metrics ,让我们指定我们需要监测的指标。
这里我提到了 "准确性",所以我应该能够在我的移动设备上监测准确性。默认情况下,我们记录了 "损失",所以在这种情况下,我们将监测2个指标:损失和准确性。
你可以根据你的需要添加任意多的指标。你也可以使用TensorFlow的内置指标或添加你自己的自定义指标。
如何创建一个回调类的实例
现在你将导入TF Watcher并创建其一个类的实例:
import tfwatcher
MonitorCallback = tfwatcher.callbacks.EpochEnd(schedule = 1)
创建一个TF观察者类的实例
在这个例子中:
- 我们使用 TF Watcher 中的
EpochEnd类来指定我们对在纪元水平上的操作感兴趣。有很多这样的类,你可以根据自己的需要来使用--在文档中找到所有关于其他类的信息。 - 我们把
schedule,以便在每1个纪元后进行监测。你可以传入3(每3个纪元后进行监测),或者你也可以传入一个你想监测的特定纪元号码的列表。
当你运行这段代码时,你应该看到类似这样的东西被打印出来:

你的会话的唯一ID
这包括你的会话的一个独特的7个字符的ID。一定要记下这个ID,因为你将用它来监测你的模型。
如何开始监控你的模型 🚀
现在我们将训练我们建立的模型,并监测移动设备上训练的实时指标:
model = get_model()
history = model.fit(
x_train,
y_train,
batch_size=128,
epochs=100,
validation_split=0.5,
callbacks = [MonitorCallback]
)
训练你的模型
在这段代码中,我们开始训练我们的模型,训练100个epochs(在这种情况下应该是相当快的)。我们还添加了我们在前面步骤中制作的对象作为callback
如果在你的案例中,你是监测预测而不是训练,你会在预测方法中添加callbacks = [MonitorCallback] 。
一旦你运行了上述代码,你就可以从移动设备的网络应用中开始监测。
进入www.tfwatcher.tech/,输入你上面创建的唯一ID。这是一个PWA,这意味着你也可以把它安装在你的移动设备上,也可以把它作为一个本地的安卓应用来使用。

安装网络应用程序
一旦你添加了你的会话ID,你应该能够通过图表看到你的日志的实时进展。除了指标之外,你还应该能够看到每个纪元所花费的时间。在其他情况下,这可能也是一个批次所花的时间:
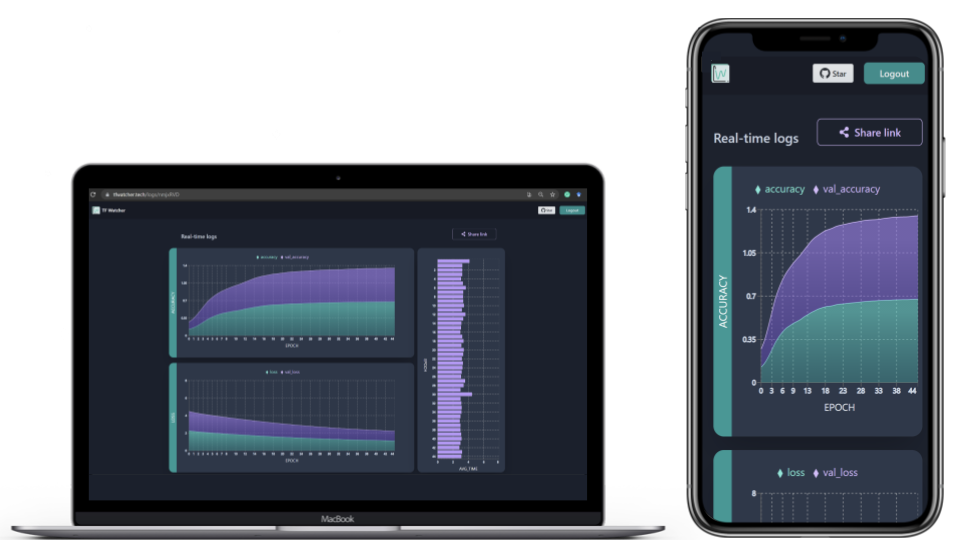
监测仪表板
如何分享仪表板
由于ML是高度协作的,你可能想与同事分享你的实时仪表盘。要做到这一点,只需点击共享链接按钮,该应用程序就会创建一个可共享的链接,供任何人查看你的实时进度或存储的仪表板:
你还能用 TF Watcher 做什么?
虽然我刚才展示的例子看起来很酷,但我们还可以用这个工具做很多事情。现在我将简要地谈一谈其中的两种情况。分布式训练和非急迫执行。
分布式训练
你可能经常将你的机器学习训练分布在多个GPU、多个机器或TPU上。你可能正在用 [tf.distribute.Strategy](https://www.tensorflow.org/api_docs/python/tf/distribute/Strategy)TensorFlow API。
你可以用与大多数分布式策略完全相同的方式来使用它,同时在自定义的训练循环中使用ParameterServer 。

分布式训练
你可以在这里找到一些关于如何用TensorFlow Keras使用这些策略的好例子。
非急迫执行
在TensorFlow 2中,默认开启了急切执行。但你经常想用 tf.function来制作你的程序的图形。它是一个转换工具,可以从你的Python代码中创建独立于Python的数据流图。
这个项目最早的一个版本使用了一些Numpy调用,但你猜怎么着,现在你也可以在非急迫模式下以同样的方式使用代码。
谢谢你的阅读!
谢谢你坚持到最后。你现在可以在任何地方通过移动设备监控你的机器学习项目,并将它们提升到新的水平。我希望你能像我一样兴奋地开始使用它。
如果你学到了新的东西或喜欢读这篇文章,请分享它,以便其他人能看到它。在那之前,请在下一篇文章中看到你!
