

这个数据科学领域也涉及到文本数据,我们需要从数据中提取许多特征。文本数据由大量的信息组成。对信息的提取可以给我们带来各种重要和有洞察力的结果。在与NLP相关的任何任务中,我们都会进行各种测试和修改,如部分语音标记、删除停顿词和命名实体识别。本文概述了命名实体识别(NER),并对其进行了实践。本文要讨论的主要内容列在下面的内容表中。
内容表
什么是命名实体?
在任何文本数据中,命名实体是存在于现实世界中的对象。对象的例子可以是任何人、地方或事物的名称,它们可以用适当的名称在任何数据中表示。命名实体的例子有Narendra Modi、Mumbai、MacBook pro等等,或者任何可以有名字的东西。
更正式的说,我们可以说一个被命名的实体是指任何对象的正式名称。正如上面的例子中提到的,Narendra Modi是一个领导人的名字,Mumbai是一个城市的名字,MacBook pro是一台笔记本电脑的名字。
什么是命名实体识别(NER)?
命名实体识别是一个过程,在这个过程中,命名实体被识别并与它的类别相联系。我们知道,任何给定的原始文本数据都是由各种类型的词组成的,比如其中一些是停顿词,部分语音词,同样,在一个文本文件中也可以有各种类型的词,这些词可以被分离出来作为命名实体。这些词不代表任何感觉,但它们可以代表两个句子或两个词之间的关系。
因此,有时识别和分类它们变得非常重要,这样,将在数据上工作的模型可以很容易地理解文本数据,并准确地从它们中得出结果。比如从一个句子中:
"Rahul在2015年以50000卢比出售了他的Maruti 800"
而命名实体识别系统将给出如下结果
"拉胡尔(人)在2015年(时间)以50000卢比(价格)出售了他的Maruti 800(汽车/物品)"
在这个句子中,我们可以看到NER模型的识别过程,将单词分类为人名、汽车、奖金和时间。
使用spaCy实现NER
有各种平台可用于NER,其中一些值得注意的平台是:
- GATE(文本工程的通用架构)--适合使用java编程语言。
- Apache OpenNLP- 它是一个基于机器学习的自然语言处理工具包。
- Spacy--它的特点是快速统计NER与开源的命名实体可视化。
- NLTK--它是一个用于各种NLP任务的标准python库。
在这篇文章中,我们使用的是python语言,这就是为什么我在实现spacy和NLTK提供的NER包和模型的一些功能。
Spacy是一个开源的NLP库,它提供了各种设施和包,可以帮助完成NLP任务,如POS标签,词法分析,快速句子分割。
让我们开始导入库的工作:
`import spacy`
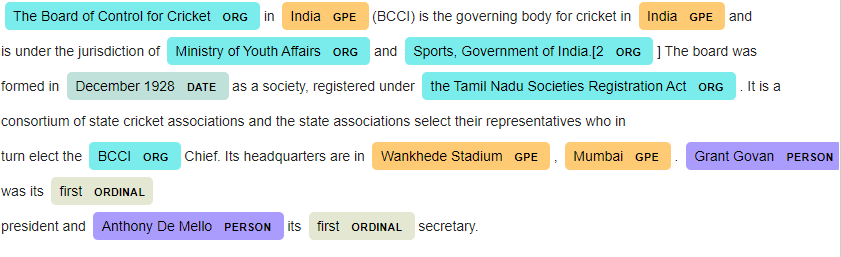
定义一个用于测试模型的样本文本,我从维基百科的BCCI页面上取了这个样本。
`raw_text="""The Board of Control for Cricket in India (BCCI) is the governing body for cricket in India and is under the jurisdiction of Ministry of Youth Affairs and Sports, Government of India.[2] The board was formed in December 1928 as a society, registered under the Tamil Nadu Societies Registration Act. It is a consortium of state cricket associations and the state associations select their representatives who in turn elect the BCCI Chief. Its headquarters are in Wankhede Stadium, Mumbai. Grant Govan was its first president and Anthony De Mello its first secretary. """`
只加载Spicy的NER模型:
`NER = spacy.load("en_core_web_sm", disable=["tok2vec", "tagger", "parser", "attribute_ruler", "lemmatizer"])`
在样本文本上拟合模型:
`text= NER(raw_text)`
打印模型在我们的样本文本中发现的命名实体:
for w in text.ents:
print(w.text,w.label_)
输出:

我们还可以使用spacy的deposplacy包将名字实体与数据可视化。
spacy.displacy.render(text, style="ent",jupyter=True)
输出:
在这里,我们可能会对命名实体的代码感到困惑。我们也可以检查这些NE代码的解释。
`spacy.explain(u"NORP")`
输出:
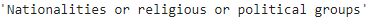
使用NLTK实现NER
让我们从导入库开始:
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
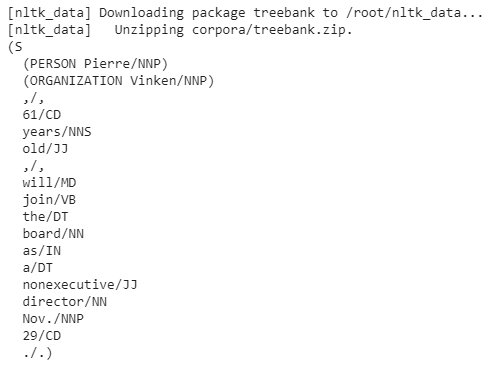
NLTK提供了一些已经被标记过的句子,我们可以用treebank包来检查它:
nltk.download('treebank')
sent = nltk.corpus.treebank.tagged_sents()
print(nltk.ne_chunk(sent[0]))
输出:
我们也可以在我们的样本文本中使用NLTK进行NER。
在提取命名实体之前,我们需要对句子进行标记,并给标记过的词加上语音部分的标签:
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
raw_words= word_tokenize(raw_text)
tags=pos_tag(raw_words)
现在我们可以使用NLTK的ne_chunk模块对修改后的样本进行NER:
nltk.download('maxent_ne_chunker')
nltk.download('words')
ne = nltk.ne_chunk(tags,binary=True)
print(ne)
输出:

由于结果非常大,我给出了一个简短的结果图片。
为了更好地理解,我们可以使用IOB标签格式。这种格式提供的标签与pos标签类似,但对词的位置和实体进行了说明:
from nltk.chunk import tree2conlltags
iob = tree2conlltags(ne)
iob
输出:

这里,IOB标签系统包含的标签形式为:
- B-{CHUNK_TYPE}。- 为起始块中的词
- I-{CHUNK_TYPE}表示在起始块中的词,I-{CHUNK_TYPE}。- 表示在该大块中的词
- O-{CHUNK_TYPE}在任何语块之外
NER的应用
在NLP领域,NER模型可以有各种不同的使用情况,其中一些使用情况的例子是:
文件中的信息总结
正如我们所知,如今数字数据的数量正在迅速增加,这种情况在大多数情况下,文件由各种未使用的信息组成,例如在任何保险文件中,可能有很多信息,但检查员只需要其中的少数信息,在这种情况下,我们可以从文件中提取姓名、电子邮件、电话号码,这将花费较少的时间来检查文件中的信息。
优化搜索引擎的算法
搜索引擎包含了大量的信息,用于任何类型的查询,但它是如何知道哪个网站是最适合查询的?让我们举一个关于命名实体识别的例子,所以如果我们在网上搜索它,那么肯定也会在某个地方看到这篇文章。所以在这种情况下,搜索引擎会根据查询在文章或提供的信息中运行一个NER模型,并提取与之相关的命名实体,这样对任何查询的推荐就会变得更加有力和有见地。
在识别不同的生物医学子部分方面
NER被广泛用于生物医学数据中的基因识别、DNA识别,以及药物名称和疾病名称的识别。这些实验使用了为其领域数据设计的特征的CRFs。
内容推荐
在今天的情况下,我们看到我们手机中的每一个应用程序都在征求反馈意见,以便他们能够越来越多地改进,给他们的客户提供最好的服务。像Netflix和Prime这样的应用程序要求对你所观看的内容进行评论。如果你向他们提供评论或反馈,他们的算法会使用NER从反馈中提取重要信息,并根据这些信息向我们或类似的用户推荐最好的产品。
POS标签和NER之间的区别
- 在POS标签中,我们关注的是任何句子中任何单词的语音部分,而在NER中,我们更关注的是对物体、人、地点、时间等不同名称的识别。
- 在NLTK的实现中,我们看到我们在NER之前进行了POS标记。所以我们可以说POS标记是一个针对整个数据的过程,在NER中我们可以使用POS标记识别的名词。
- POS标签对整个数据起作用,它检查每个词并将它们分类到不同的类别,而NER只对数据中作为命名实体的几个词起作用。
- POS标签比NER更能增加数据的大小。
最后的话
在这篇文章中,我们可以看到关于命名实体识别(NER)的细节。我们还讨论了可以帮助我们进行NER的不同的库,我们也通过流行的库,spacy和NLTK,来实现。我鼓励读者也使用这些库,因为它们可以在不同的编程语言中运行。我没有提供使用它们的实现。在许多地方,NER在一些基本的NLP过程中也起着至关重要的作用,这些过程需要它来提供许多有用的结果。
参考文献
