

当给定的数据精确地覆盖了模型所设计的领域,并根据模型的特征进行结构化时,机器学习模型才能准确地工作。由于大多数可用的数据都是非结构化或低结构化的格式,对这种类型的数据进行注释时,要采用机器学习中的弱监督概念。主要是如果数据被注释了但质量不高,弱监督就会出现。在这篇文章中,我们将尝试详细了解弱监督,以及执行弱监督的方法和策略。本文所涉及的主要内容如下。
目录
- 什么是弱势监督?
- 弱监督的演变
- 标签化训练数据的问题
- 如何获得更多的标签化训练数据?
- 弱化标签的类型
- 支持弱监督的基本系统功能
让我们从理解弱监督开始。
什么是弱监督?
弱监督是机器学习的一部分,在机器学习中,无组织或不精确的数据被用来提供指示,以标记大量的无监督数据,从而使大量的数据可以被用于机器学习或监督学习。更正式地说,我们可以说指示是一种监督信号,用于标记未标记的数据。我们知道获得手工标记的数据集是非常昂贵和耗时的,这种方法试图通过为一些数据提供标签和使用一些数据为未标记的数据提供标签来减少手工标记数据的努力。
特别是在自然语言处理中,我们有许多特定的数据模式,导致预训练的模型在特定的模式下表现不佳。在这种情况下,弱监督有助于提高模型在模式方面的性能。使数据适用于建模需要大量的努力、时间和金钱。为了使数据集结构化,我们可以将数据注释水平分为三部分,如果数据被高度注释,我们可以直接进行建模程序,模型可以属于监督学习(如果数据很大)、无监督学习和转移学习(如果数据很小),如果数据没有被注释,我们遵循无监督学习程序,如聚类、PCA等,以下图片代表了我们为什么需要弱监督的概况。
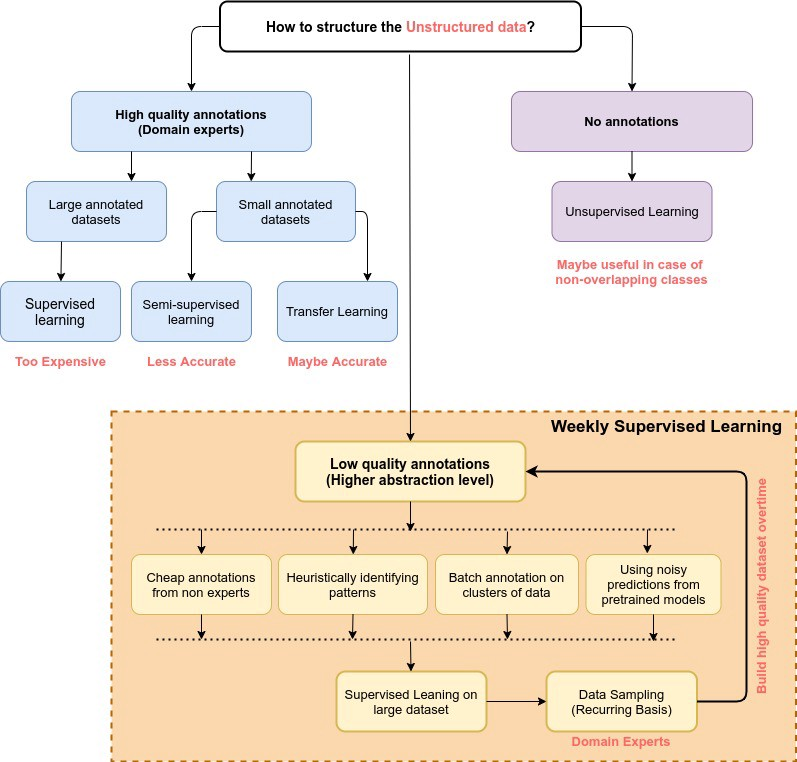
弱监督的演变
在开始的时候,人工智能的主要焦点是专家系统。其中包括中小企业的知识库与推理引擎的结合。在人工智能的中间时代,模型开始以强大和灵活的方式完成基于标记数据的任务。经典的ML方法被引入,主要包括两种方式来放置来自领域专家的知识库。第一种是向来自领域专家的模型提供少量的手工标记的数据,第二种是提供手工设计的特征,这样的特征可以处理模型对数据的基础表示。
在现代,深度学习项目正处于蓬勃发展的阶段,因为它们有能力在许多领域和任务中学习表示。这些模型不仅为特征工程提供了便利,而且还产生了许多系统来使数据自动标记,如snorkel是一个支持和探索与机器学习互动的系统。该系统只要求标记功能,黑匣子式的代码片段,帮助标记未标记数据的子集。因此,这就是从弱监督的基本部分到监督的高级部分,弱监督已经发展了,而且,人们仍在努力在该领域进行更多的工作,寻找改善弱监督的新方法。

标签化训练数据的问题
以下是标签化训练数据的主要问题:
标记的数据数量不足
在机器学习训练的初始阶段,模型依赖于标记的数据,问题是大部分的数据都是没有标记的,或者不足以应用到模型上进行更好的训练。获取训练数据几乎是不切实际的,昂贵的,或耗时的。
没有足够的主题专家来标记数据
当涉及到给无标签的数据贴标签时,我们需要一个人或一个团队的主题专家。而没有这样的设施,人为干预数据的标签需要大量的时间,而且还包括中小企业的成本。这使得这个过程不切实际。
没有足够的时间来标记和准备数据
在任何数据中实施机器学习模型之前,预处理数据的任务是必须的,以获得更好的性能。当涉及到现实生活中的经验时,我们有很多数据,但并不是每个数据都是准备好的,所以它可以被部署在模型上。根据模型迅速做出准确的数据几乎是不可能的。
为了克服所有这些问题,我们需要一些刚性的、可靠的方法,这样我们就可以进行数据预处理的主要部分,即数据标签。
如何获得更多标记的训练数据?
在任何情况下,这是最传统的获得标签数据的方法,我们必须雇用SME(主题专家)来标记数据,但当事情发生在大型未标记的数据集时,这个过程就变得非常昂贵,一个人或一群人很难提供标签。 在这种情况下,为了减少努力,我们基本上遵循三个主要方法。
-
主动学习--主动学习方法的主要目标是提供对模型最有价值的标签数据点,或者我们可以说我们选择需要标签的新数据点。例如,在情感分析中,我们有愤怒的情绪,它接近于模型的决策边界,在这种情况下,我们要求SME只对那些包含情绪的句子进行标注。或者我们可以只对这些数据点进行较弱的监督,这样主动学习就可以与弱监督变得更加互补。
-
半监督学习-- 这种方法背后的主要目标是通过假设未标记数据的平滑性和低距离度量,在高水平上使用一个小的标记数据集与一个大的未标记数据集。它有助于通过这些假设来减少中小企业的努力,以利用未标记的数据来开发未标记的数据。当数据可以廉价地大量获得时,我们就会使用这些方法。 生成性方法,如生成性对抗网络、启发式转换模型,有助于使决策边界正规化。
-
迁移学习--该方法的主要目标是让一个已经训练好的模型来学习我们所拥有的数据。如果我们之前训练的数据集和要应用模型的数据集有相似之处,那么已经在不同数据集上训练过的模型就可以应用到数据集上。在今天的深度学习场景中,一个常见的方法是制作一个模型,在一个大的数据集中训练它,把它调整好,然后把这个模型用于感兴趣的任务。

以上给出的方法肯定有助于减少标记数据的工作。在上面给出的图片中,我们可以看到弱监督是如何帮助弥补其他方法的缺点的。基于标签的类型,我们可以用下面的方式对弱标签进行分类。
弱标签的类型
有三种主要的弱标签类型: --
不精确或不准确的标签:这种类型的标签可以通过主动学习的方法获得,在这种方法中,主题专家给开发人员的数据贴上不太精确的标签。然后,开发人员可以使用弱标签来创建规则,定义分布,在训练数据上应用其他约束。
不准确的标签:这种类型的标签可以通过半监督学习获得,其中数据集上的标签可以通过一些昂贵的手段,如众包,获得质量较低的标签。开发人员可以通过规范化模型的决策边界来使用获得的标签。这种标签数量很多,但不是完全准确。
现有标签:这种类型的标签可以从现有的资源中获得,如知识库、用于训练的替代数据,或者从预训练模型中使用的数据中获得。这些标签可以被开发者使用,但它们并不完全适用于给模型的任务。在这种情况下,使用预训练的模型是有益的。
支持弱监督的基本系统功能
到目前为止,我们已经看到了什么是弱监督的规范,并且可以很容易地理解任何系统可以包括的功能,这些功能是用来支持弱监督的。我们可以说,用一些函数给数据贴上标签可能会产生噪声输出。 我们需要一些函数来给数据贴上标签,并通过模型来找出标签准确性的测量。一个系统可以由三个特征组成。
- 一个标记功能,为未标记的数据提供标签。
- 一个模型来学习标签的准确性。
- 一个可以输出训练标签集的模型。

最后一句话
在这篇文章中,我们已经看到了什么是弱监督,以及它在三个部分的演变。此外,我们还了解了建模中未标记的数据所带来的问题,以及使数据标记的方法是什么,如果生成一个系统来支持弱监督,它的主要特征应该是什么,以帮助执行弱监督。
