

许多机器学习 包需要将字符串特征转化为数字表示,以便模型的正常运行。分类字符串特征可以代表广泛的数据(例如,性别、姓名、婚姻状况等),并且是众所周知的难以机械地进行预处理。这篇文章将介绍这样一个基于Python的框架,该框架旨在自动处理文本数据时需要的准备任务。以下是本文要讨论的主要内容。
目录
- 自动预处理的问题
- 该框架所面临的挑战
- 方法论
- 评估结果
- Python的实现
让我们先讨论一下我们在实现自动化过程中面临的一般问题。
自动预处理的问题
现实世界的数据集经常包含类别字符串数据,如邮政编码、姓名或职业。许多机器学习技术需要将这些字符串特征转换为数字表示,以便正常运行。具体的处理是必要的,这取决于数据的类型。例如,纬度和经度可能是传达地理字符串数据(例如,地址)的理想方式。
数据科学家必须手动预处理这种原始数据,这需要大量的时间,最多可占到他们一天的60%。有一些自动化的数据清理技术,然而,它们经常不能满足类别字符串数据的巨大范围。
John W. van Lith和Joaquin Vanschoren提供了一个框架,名为 ***"从字符串到数据科学"***的框架,用于系统地识别和编码表格式数据集中的各种分类字符串特征。我们还将研究一个开源的Python实现,并在一个数据集上进行测试。
该框架所解决的挑战
这种方法处理各种问题。首先,类型识别试图发现预设的字符串数据(例如,日期)的 "类型",这需要额外的准备。概率有限状态机(PFSMs)是一种可行的方法,它可以生成类型概率,并以正则表达式为基础。它们还可以检测缺失或失位的条目,如字符串列中的数字值。
该框架还涉及统计类型推断,它使用内在的数据分布来预测一个特征的统计类型(例如,序数或分类),以及SOTA编码技术,它将分类字符串数据转换为数值,由于小的错误(例如,错别字)和内在的意义(例如,一个时间或地点),这是很困难的。
现在让我们详细看看这个框架的方法。
方法论
如图所示,该系统旨在检测和适当编码表格数据集中的各种类型的字符串数据。 首先,我们使用PFSMs来确定一列是数字,有已知的字符串特征(如日期),还是包含任何其他类型的标准字符串数据。为了纠正不一致的地方,相关的缺失值和离群点处理算法被应用到基于这个第一分类的完整数据集上。
然后,具有公认的字符串类型的列以中间类型的方式进行处理,而其他列则根据其统计类型(例如,名义或序数)进行分类。最后,使用最适合每个特征的编码对数据进行编码。

字符串特征推理
最初阶段是在PFSMs和概率类型库的基础上,为九种不同类型的字符串特征开发基于正则表达式的PFSMs:坐标、日期、电子邮件地址、文件路径、月份、数字字符串、短语、URL和邮政编码。
处理缺失值和异常值
随后,根据Little测试(随机缺失、非随机缺失、完全随机缺失),使用平均/模式推算或基于数据缺失性的多变量推算技术对缺失值进行推算。为了确保后续过程的稳健性,小的错误会用字符串度量来纠正,如果合适的话,会对数据类型的异常值进行纠正。
处理字符串特征
然后,对于PFSMs检测到的所有字符串类型,我们进行中间处理。首先,我们通过删除句子中的所有名词来减少字符串,例如。第二,我们分配或进行某些编码技术,例如用年、月、日的值来代替日期。第三,我们提供额外的信息,如邮政编码的经度和纬度值。
统计学类型预测
PFSMs不识别的字符串特征被标记为标准字符串。它通过确定这些数据是否包含有序(ordinal)或无序(nominal)数据来确定其统计类型。

预测是基于从特征中检索出的八个特征,如上图所示,包括字符串值的唯一性,列名或值是否显示出顺序性,以及字符串值的GloVe词嵌入是否显示出值之间的明确联系。为了预测统计类型,这些特征被赋予一个梯度提升分类器。这个分类器是使用手工注释的真实世界信息学习的。
编码
最后,对于每个分类字符串特征,都要进行适当的编码。一个预设的编码被应用于由PFSMs识别的字符串类型。由于其对形态变异和大心数特征的容忍度,它对名义数据使用类别编码和目标编码。
当cardinality低于30,低于100和至少100时,它分别使用相似性、Gamma-Poisson和min-hash编码器。一个文本情感强度分析器(FlairNLP)将字符串值(例如,非常差,非常好)转换为有序编码,定义了序数数据的排序。
评估结果
该框架及其独立组件在包含分类字符串特征的各种真实世界数据集上进行了测试。他们看了在编码数据上训练的梯度提升模型在下游的表现如何。提升模型对高维数据有内在的抵抗力,可以进行更准确的比较。对于分类任务,我们采用了分层的5倍交叉验证,而对于回归任务,我们采用了MAE。
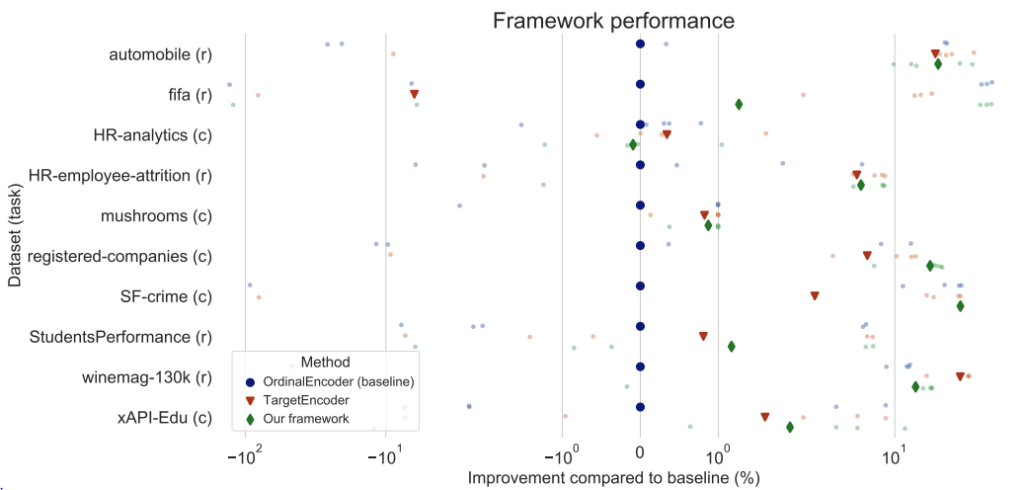
首先,我们对完整的框架进行了整体评估,并与基线进行了比较,在基线中,数据被手动预处理,并对分类字符串属性进行了平均/模式归类和序数或目标编码。
五个折叠的相对性能差异,以及它们的平均值显示在上图中。这些发现表明,该框架在真实世界的数据中有效地工作。自动编码在winemag-130k数据集上的表现很差,这可能是由于应用了启发式方法。
Python的实现
在这一节中,我们将实现上述框架,官方资料库可以在这里找到 ,你可以在这里测试它。我们使用的是女装电子商务数据集,通过它的评论,以客户为中心。它的九个有用的功能为解析出各个维度的测试提供了一个很好的环境。
通过使用这个框架,我们要尝试对数据集进行清洗和编码。按照repo 中提到的安装说明进行操作。
首先,我们将有几个数据集的实例,并将检查缺失值:
import pandas as pd
data = pd.read_csv('/content/drive/MyDrive/data/Womens Clothing E-Commerce Reviews.csv')
print(data.head())

print(data.info())

我们可以看到,总共有23486个实例和11个属性,其中5个属性有缺失值。现在我们来试试这个框架。我们将直接使用完整的执行脚本,它将对数据集进行清理和编码。首先,我们将通过设置encoding=False来清理数据集,随后将对数据集进行编码:
from auto_string_cleaner import main
x = main.run(data,encode=False)
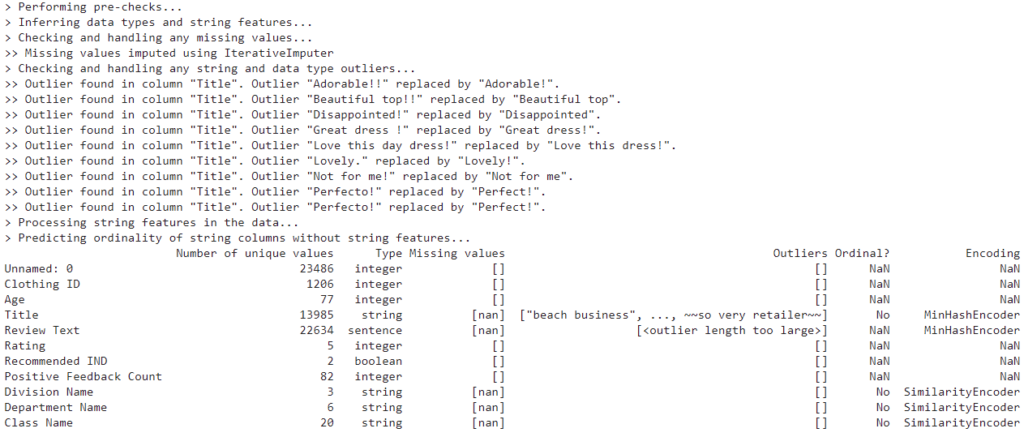
x.head()

我们可以看到框架已经处理了所有必要的预处理步骤,如缺失值的归纳、离群点检测和移除。下面你可以看到编码后的分类特征。

最后的话
在这篇文章中,我们已经看到了一个结合了尖端技术和创新组件的框架,以实现自动字符串数据清理。这个系统产生了令人鼓舞的结果,它的一些创新组件(例如,字符串特征类型推断,ordinality检测,以及利用FlairNLP进行编码)表现良好,特别是在识别和处理分类字符串数据时。
