

在过去的几年里,我们看到自监督学习方法正在迅速崛起。我们也可以注意到,使用自监督学习方法的模型已经解决了许多关于未标记数据的问题。这些方法在计算机视觉和自然语言处理等领域的应用已经显示出许多伟大的成果。在这篇文章中,我们将讨论在计算机视觉领域使用的自监督学习方法。我们还将讨论作为自监督方法使用的对比学习,以解决计算机视觉中的数据标记问题。本文要讨论的主要内容如下。
目录
- 为什么需要自我监督的学习?
- 对比性学习
- 对比预测编码(CPC)
- 实例识别方法
让我们从了解为什么需要自我监督学习开始讨论。
为什么需要自监督学习?
在使用监督学习技术时,我们需要大量的标记数据。大多数时候,数据标记变得非常昂贵和耗时,特别是在计算机视觉领域,需要执行诸如物体检测的任务。计算机视觉任务中也有 图像分割任务,这需要对每一个小细节进行良好的注释和标记。我们也知道,我们可以提供大量的未标记的数据。
自监督学习的基本思想是让模型只从未标记的数据池中学习数据的重要表示。在这种学习方法中,模型被训练,因为它们可以监督自己,在监督之后,它们可以在数据上提供一些标签,这样就可以对其进行监督学习任务。如果我们谈论的是计算机视觉,监督学习任务可以是最简单的图像分类任务,也可以是语义分割,这是计算机视觉领域的一项复杂任务。
在自然语言处理领域,像 BERT和T5这样的转化器模型正在提供很多富有成效的结果。这些模型也是建立在自我监督学习的理念上,它们已经用大量的未标记的数据进行了训练,然后它们用少数标记的数据应用一些微调的监督学习模型。同样,在计算机视觉领域,也有一些模型遵循自监督学习的理念。在这篇文章中,我们将介绍其中一些。
在计算机视觉中,自监督学习的基本思想是创建一个模型,该模型可以使用输入数据或图像数据来解决任何基本的计算机视觉任务,并且在模型解决问题的时候,它可以从图像中呈现的物体结构中学习。可以有很多自我监督的学习方法,但在计算机视觉的情况下,一种名为对比法的方法似乎比其他方法更成功。因此,在本文的下一节,我们将介绍对比性学习方法。
对比性学习
为了理解对比学习法,请参考下面的图片,其中使用对比学习法的模型有一个函数f(),它接受输入a并给出输出f(a)。
比方说,可以有两种类型的输入,正面和负面。因此,如果有两个相似的输入(在下面的图片中,我们认为a1和a2c是相似的正向输入)给函数f(),那么它们的输出应该是相同的,并且这个输出应该与相反的输入的输出不同。以上可以被认为是任何对比学习方法的声明。
正面或相似的输入可以是同一图像的两个部分或同一视频的两个帧,负面或不相似的输入可以是不同计算机视觉数据的一部分或不同图像的一部分。
对比性预测编码(CPC)
对比预测编码(CPC)的总体思路是从图像的粗略网格中提取一些上行,其任务是预测图像的一些下行,在生成下行预测的时候,模型需要学习图像的结构行为和对象。例如,通过看到猫的脸,模型可以预测猫在图像的下部有四条腿。
让我们假设一个基本的计算机视觉建模任务被分为三个部分:
- 将图像划分为网格,例如,如果图像的大小为256×256,它可以划分为7×7的网格,如果单元格的大小为64px和32px,它可以与每个相邻的单元格重叠。
- 将网格单元编码为一个向量,如果给定图像的大小与第一点相似,那么网格单元可以被编码为一个1024维的向量,这样整个图像就可以转换为7x7x1024的张量。
- 一个自回归生成模型可以用来预测图像的下行,使用转换为上行张量的网格单元。例如,转换为7x7x1024张量的上3行可用于生成或预测最后3行。PixelCNN模型可用于上述过程。
下面的图片可以作为上述步骤的代表:

为了训练这样一个模型,我们需要引入一个损失函数,该函数可以计算补丁预测之间的差异,更正式地说,如果是正数对和负数对之间的相似度测量。大多数情况下,损失函数使用N个补丁的X集,其中X集可以被认为是N-1个负样本和1个正样本的集合。这个损失函数可以通过估计噪声和对比度之间的差异来计算。这个损失函数也可以称为infoNCE函数,其中NSE代表噪声对比度的估计。

优化这个损失将产生一个估计密度比的函数,它是。
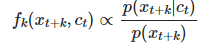
上述函数与log softmax函数非常相似,后者通常用于计算预测值和实际值或原始值之间的相似性。 在 "Representation learning with contrastive predictive coding"一文中,介绍了CPC的概念,我们可以找到使用不同技术的模型的准确性比较。下表显示了这一点。
| 方法 | 准确率 |
| 运动分割 | 27.6 |
| 示例 | 31.5 |
| 相对位置 | 36.2 |
| 着色 | 39.6 |
| 对比性预测编码(CPC) | 48.7 |
在上表中,我们可以看到CPC方法在表征学习方面的表现,与许多监督学习模型相比仍有差距,如ResNet-50在Imagenet上使用100%的标签,其最高准确率为76.5%。对CPC的更新是为了提高模型的准确性,这可以称为实例识别方法。文章的下一部分是对实例判别方法的介绍。
实例判别方法
正如我们在CPC中看到的,该方法被应用于图像的一部分。与CPC相比,实例判别方法的基本思路是在整个图像中应用CPC。图像与它们的增强版可以组成一个正对,它们应该有相似的表示,而任何一个图像与它的增强版应该有不同的表示。

图像增强的主要动机是,如果已经从模型中学到了任何表征,就不应该改变,增强的图像可以是水平翻转、随机裁剪、不同的颜色通道等,把增强的图像作为输入可以改变图像,但模型学到的类信息不应该改变。
在这个方法中,模型的过程可以分为三个基本步骤:
- 将输入的图像与其随机增强的版本一起交给模型,使其成为一个正面的配对,同时也将负面的样本与其增强的版本一起交给模型。
- 使用任何编码器对图像对进行编码,并在图像上获得标签或表示,同时使用编码器对负样本进行表示。
- 应用InfoCPC交叉检查阳性对之间的相似性水平和阳性与阴性对之间的不相似性水平。
有两篇论文SimCLR和Momentum Contrast (MoCo)对实例判别方法进行了研究,它们之间的主要区别在于如何处理负面样本。我们可以使用他们的技术来制作计算机视觉领域的自监督学习模型。
最后的话
在这篇文章中,我们看到在计算机视觉领域,自我监督学习是一种表征学习方法,我们可以使用监督学习模型来对数据进行标注,这对减少数据标注的成本、时间和精力非常有帮助。有各种基于对比学习的模型,如MoCo和SimCLR,可用于计算机视觉的自监督学习。
