布隆过滤器(Bloom Filter),是由Howard Bloom在1970年提出的二进制向量数据结构,具有很好的空间和时间效率,尤其是空间效率极高,BF常常被用来检测某个元素是否是巨量数据集合中的成员。
基本原理
BF可以高效地表征集合数据,其使用长度为m的位数组来存储集合信息,同时使用k个相互独立的哈希函数将数据映射到位数组空间。

其基本思想如下:首先,将长度为m的位数组元素全部置为0。对于集合S中的某个成员a,分别使用k个哈希函数对其计算,如果hi(a)=x,(1≤i≤k,1≤x≤m),将位数组的第x位置为1,对于成员a来说,经过k个哈希函数计算后,可能会将位数组中的w(w≤k)位为1。对于集合中的其他成员也如此处理,这样即可完成位数组空间的集合表示。其算法流程如下:
BloomFilter(set A, hash_functions, integer m)
filter[1...m]= 0;
foreach ai xin A:
foreach hash function hj:
filter[hj(ai)] = 1;
end foreach
end foreach
return filter
当查询某个成员a是否在集合S中出现时,使用相同的k个哈希函数计算,如果其对应位数组中的w位(w≤k)都为1,则判断成员a
属于集合S,只要w位中有任意一位为0,则判断成员a不属于集合S,其算法流程如下:
MembershipTest(element, filter, hash_functions)
foreach hash function hj:
if filter[hj(element)] != 1 then
return False
end foreach
return True
在查询某个成员是否属于集合时,会发生误判(False Positive)。也就是说,如果某个成员不在集合中,有可能BF会得出其在集合中的结论。但是不会发生漏判(False Negative)的情况,即如果某个成员确实属于集合,那么BF一定能够给出正确判断。
误判率计算
集合大小n、哈希函数的个数k和位数组大小m会影响误判率,对其关系进行推导:
某元素由Hash函数插入时相应位置不为1的概率为:1−m1经过k个Hash函数,该位置仍然没有被置为1的概率为:(1−m1)k那么插入n个元素,该位置仍未被置为1的概率为:(1−m1)kn该位置被置为1的概率为:1−(1−m1)kn在检测某个元素是否存在于集合中时,误判时会认为相应位置所有的Hash值对应的位置的值都是1,误判的概率[1−(1−m1)kn]k由于limx→0(1+x1)x=e⇒[1−(1−m1)kn]k=[1−(1−m1)−m∗−mkn]k≈(1−e−mkn)k假设给定m和n,计算k为什么值时误判率最低?对于误判函数f(k)=(1−e−mkn)k记b=e(mn),则f(k)=(1−b−k)k两边去对数则,ln[f(k)]=k∗ln(1−b−k),对其求导得f(k)1∗f′(k)=ln(1−b−k)+k∗1−b−k1∗(−b−k)∗lnb∗(−1)=ln(1−b−k)+k∗1−b−kb−k∗lnb令ln(1−b−k)+k∗1−b−kb−k∗lnb=0⇒ln(1−b−k)∗(1−b−k)=−k∗b−k∗lnb⇒ln(1−b−k)∗(1−b−k)=b−k∗lnb−k⇒1−b−k=b−k⇒b−k=21⇒e(−mkn)=21⇒mkn=ln2⇒k=ln2∗nm=0.7∗nm假设已知集合大小n,并设定好误判率p,需要计算给BF分配多大内存合适当k已经取得最优时:P(error)=2−k⇒log2P=−k⇒k=log2P1⇒ln2∗nm=log2P1⇒nm=ln21∗log2P1=−ln22lnp
有上述关系可知:
集合大小n、哈希函数的个数k和位数组大小m和误判率之间的关系:
误判率pfp=(1−em−kn)k
假设n和m已知,即已知位数组大小和集合元素个数,设定多少个哈希函数误判率能够达到最低呢?经过分析,最优的哈希函数个数为:
k=nmln2
假设已知集合大小n,并设定好误判率p,需要计算给BF分配多大内存合适,即确定m的大小。
m=−(ln2)2nlnp
ClickHouse BloomFilter代码实现
上面的公式推导可以看到,当nm固定,存在一个k使得误判率p最低,这就是k的最右取值。如表就展示了不同m/n和k的误判率
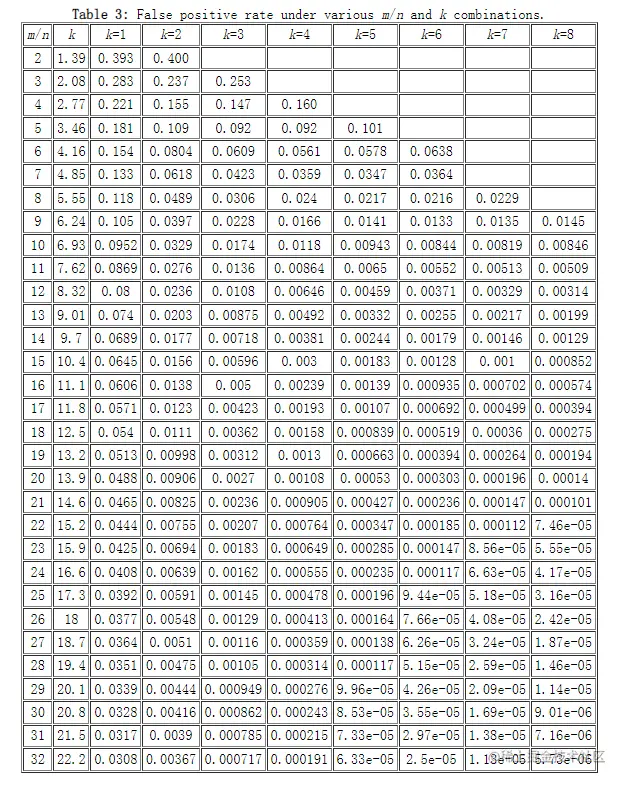
ClickHouse就利用了查表的原理,根据输入的误判率的大小,反推出k和nm的大小。相关实现详见src\Interpreters\BloomFilterHash.h中的calculationBestPractices函数。
static std::pair<size_t, size_t> calculationBestPractices(double max_conflict_probability)
ClickHouse的BloomFilter的实现源码位于src\Interpreters\BloomFilter.cpp,代码实现BloomFilterParameters封装了BF相关输入参数。
BloomFilterParameters::BloomFilterParameters(size_t filter_size_, size_t filter_hashes_, size_t seed_)
: filter_size(filter_size_), filter_hashes(filter_hashes_), seed(seed_)
BloomFilter负责实现布隆过滤器的功能,主要的功能接口:
void BloomFilter::add(const char * data, size_t len)
bool BloomFilter::find(const char * data, size_t len)
参考资料


