

热烈感谢🤗Benjy Weinberger对这篇文章的评论。请听他在《Semaphore Uncut》节目中谈论他对Pants的贡献以及他对monorepos的看法。
网络开发者、数据科学家、人工智能和机器学习专家都将Python视为一种有价值的工具。作为一种通用语言,Python没有对手。然而,构建和测试Python应用程序是一个完全不同的罐子。这是一个由虚拟环境、pip、pipenv、setuptools或poetry命令组成的复杂拼图。
本教程将向你展示摆脱整个混乱局面的方法:我们将学习如何使用Pants v2,一个由Twitter和Foursquare开源的全面、用户友好的构建系统。
什么是Pants
Pants是一个用于Python应用程序的快速、可扩展的构建系统。它的设计有一个特定的目标:在大型资源库和单库中大规模工作。单体库是一个代码库,有许多独立但可能相互关联的应用程序和共享组件。
Pants将一个复杂的构建过程分解成小的逻辑工作单元,这些单元可以被并行化和缓存。Pants的特点是:
- 完整的工具集:Pants负责所有的小技术细节,如创建虚拟环境或下载依赖性。在引擎盖下,它采用了著名的Python工具,如pip、setuptools和pytest。
- 测试自动化:Pants找到测试文件并为你运行它们。
- 速度和可扩展性:核心是用Rust编写的,以提高性能,而特定语言的后端在Python上运行,以提高可扩展性。
- 依赖性推理:Pants了解项目的结构,可以自己确定依赖关系,不需要很多模板。
- 内置缓存:工作被分割成小的单元,这些单元被打上指纹并缓存起来。Pants尽可能地从缓存中解决工作。
- 隔离:每个工作单元在一个隔离的沙盒中运行,以防止副作用。
- 并发:工作单元并行运行以提高速度。
- 远程执行:当工作超出单台机器的能力时,Pants可以在一个集群中分配任务。
由于其并行处理能力和缓存,Pants的速度很快。它不会在重复已经完成的工作上浪费时间。
安装和配置Pants
让我们简单看一下Pants是如何安装和配置的。我们将使用一个名为semaphore-demo-python-pants的演示项目。请自由地分叉它并克隆它来学习本教程:
semaphoreci-demos / semaphore-demo-python-pants
该项目由两个文件夹组成,一个包含一个 "hello world "应用程序,另一个包含一些共享函数:
[demo structure]
│
├── commons [shared libraries]
│ ├── __init__.py
│ ├── math_utils.py
│ ├── math_utils_test.py
│ ├── string_utils.py
│ └── string_utils_test.py
│
├── hello_world [sample application]
│ ├── __init__.py
│ ├── main.py
│ ├── requirements.txt
│ └── test_main.py
├── LICENSE.md
└── README.md
在你的机器上克隆完资源库后。用这几行字创建一个名为pants.toml 的新文件:
[GLOBAL]
pants_version = "2.4.1"
下载Pants shell脚本,你可以用curl来做这个:
$ curl -L -o ./pants https://pantsbuild.github.io/setup/pants
$ chmod +x ./pants
Pants第一次运行时,它将自己启动并启动一个后台进程,pantsd :
$ ./pants --version
你可能想把Pants脚本和初始配置文件添加到版本控制中。任何克隆版本库的人都可以运行./pants --version ,并启动构建系统:
$ git add pants pants.toml && git commit -m "add pants"
Pants的功能是通过后端实现的。你要启用的第一个后端是pants.backend.python ,负责支持Python,在pants.toml 中添加以下一行:
backend_packages = ["pants.backend.python"]
Pants BUILD文件
下一步是创建BUILD文件。这些文件包含关于项目结构和输出的信息,在Pants-lingo中被称为目标,偶尔也包含不能自动推断出的依赖关系。目标可能是内部库、可执行的二进制文件、可发布的包,或者只是测试输出。
要创建初始BUILD,请使用pants tailor :
$ ./pants tailor
Created commons/BUILD:
- Added python_library target commons
- Added python_tests target commons:tests
Created hello_world/BUILD:
- Added python_library target hello_world
- Added python_tests target hello_world:tests
Pants 递归地扫描文件夹,并为每个检测到的带有Python代码的文件夹创建BUILD。打开任何一个构建文件都会显示其基本结构:
python_library()
python_tests(
name="tests",
)
初始构建通常包含两个指令:
- python_library:将当前文件夹标记为包含Python非测试代码。
- python_tests:因为Pants在该文件夹中检测到了测试,所以创建了它。
用Pants测试
既然Pants检测到了测试,让我们试着运行它们:
$ ./pants test commons/:
✓ commons/math_utils_test.py:tests succeeded.
✓ commons/string_utils_test.py:tests succeeded.
冒号(:)作为通配符,所以本质上,该命令说:"运行commons/ 文件夹中的所有测试"。
让我们试试hello_world 文件夹中的测试:
$ ./pants test hello_world/:
== ERRORS ==
__ ERROR collecting hello_world/test_main.py __
ImportError while importing test module '/tmp/process-execution23AVPp/hello_world/test_main.py'.
Hint: make sure your test modules/packages have valid Python names.
E ModuleNotFoundError: No module named 'ansicolors'
== short test summary info ==
哎呀,出错了。错误很明显:缺少一个模块。一个经验丰富的 Python 开发者会用pip install ansicolors 或pip install -r hello_world/requirements.txt 来安装丢失的包。 但 Pants 会为你做这些。它可以找出缺失的依赖性,并在运行中下载它们。要启用这个功能,我们必须在hello_world/BUILD 中添加以下一行:
python_requirements()
这使得Pants解析requirements.txt ,并将每个模块转换为目标。现在再次运行失败的测试命令。这一次你应该看到缺少的模块被按需要下载:
$ ./pants test hello_world/:
✓ hello_world/test_main.py:tests succeeded.
你可以使用两个双冒号(::)一次性运行所有测试,这使得Pants递归地旅行所有文件夹和子文件夹:
$ ./pants test ::
✓ commons/math_utils_test.py:tests succeeded.
✓ commons/string_utils_test.py:tests succeeded.
✓ hello_world/test_main.py:tests succeeded.
保持依赖性的检查
Pants维护着版本库中所有依赖关系的图表。你可以使用pants dependencies 来查看某个特定文件导入了哪些模块:
$ ./pants dependencies hello_world/main.py
commons/string_utils.py
hello_world:ansicolors
这里Pants检测到main.py 需要ansicolors ,再加上一个同级文件夹中的一个文件。正如你所看到的,它可以交叉引用整个版本库。这极大地简化了单版本设置中的依赖关系管理。
要看反向的依赖关系,也就是依赖特定文件的部分,使用pants dependees :
$ ./pants dependees commons/string_utils.py
commons
commons:tests
commons/string_utils_test.py:tests
hello_world
hello_world/main.py
构建二进制文件
Pants使用PEX库构建独立的可执行文件。要尝试它,请在hello_world/BUILD
pex_binary(
name="pex_binary",
entry_point="main.py",
)
PEX文件是专门制作的压缩文件,包含了应用程序和它的依赖关系。pants run 命令构建并运行该程序
$ ./pants run hello_world/:
Hi world
你甚至可以用pants package 制作一个可分发的文件。Pants也可以让你创建传统格式的软件包,如wheel或sdists:
$ ./pants package hello_world/:
Wrote dist/hello_world/pex_binary.pex
你应该在dist 里面有一个新的文件夹和文件。试着从那里运行hello world程序:
$ ./dist/hello_world/pex_binary.pex
Hi world
分析代码
因为Pants对版本库中的所有代码都有完整的了解,它可以在更深的层次上分析事物。Pants自带了对几种静态分析工具的开箱即用支持:
- black:自动格式化Python文件的地方。
- docformatter:自动格式化文档字符串。
- flake8:一个强制执行Python风格指南的linter。
- pylint:另一个Python的linter。
- mypy:为 Python 代码添加静态类型检查,需要代码包含类型提示才能工作。
- isort:按字母顺序排列进口。
- bandit:发现 Python 代码中常见的安全问题。
启用它们只是在pants.toml 中添加后端:
backend_packages = [
"pants.backend.python",
"pants.backend.python.lint.black",
"pants.backend.python.lint.docformatter",
"pants.backend.python.lint.flake8",
"pants.backend.python.lint.pylint",
"pants.backend.python.typecheck.mypy"
]
通过pants lint ,我们可以同时运行所有linters:
$ ./pants lint ::
--------------------------------------------------------------------
Your code has been rated at 10.00/10 (previous run: 10.00/10, +0.00)
✓ Black succeeded.
✓ Docformatter succeeded.
✓ Flake8 succeeded.
✓ Pylint succeeded.
我们也有一个类型检查器:
$ ./pants typecheck ::
Success: no issues found in 8 source files
✓ MyPy succeeded.
还有一个代码格式化器来修复风格偏差:
$ ./pants fmt ::
你甚至可以同时运行多个动作。裤子会计算出正确的顺序:
$ ./pants fmt lint typecheck ::
将更新后的文件放入仓库,因为我们在下一节配置Semaphore的持续集成时需要它们:
$ git add pants.toml commons/BUILD hello_world/BUILD
$ git commit -m "add pants build config"
$ git push origin master
在Semaphore上用Pants构建
当然,如果我们不告诉你如何用SemaphoreCI/CD构建Pants项目,这个教程就不完整了。
首先,创建一个新项目并将你的仓库添加到Semaphore:


下一页可以让你授予权限给你组织中的其他用户。继续,选择单一作业,然后自定义:

构建阶段
第一个作业将启动构建阶段,我们将在这里构建二进制包,以检查项目是否可构建。
构建作业将需要完成以下步骤:
- 克隆 Git 仓库,Semaphore为此提供了内置的checkout命令。
- 用sem-version 确保我们使用正确的 Python 版本。
- 从以前的构建中恢复 Pants 缓存,认识到工作第一次运行时它将是空的。
- 运行
pants package来构建PEX二进制文件。 - 保存缓存,这样连续的作业会运行得更快。
我们将通过在作业中添加以下命令来实现这些步骤:
checkout
sem-version python 3.8
cache restore pants-$SEMAPHORE_GIT_BRANCH,pants-master
./pants package ::
cache store pants-$SEMAPHORE_GIT_BRANCH,pants-master $HOME/.cache/pants

Pants对cache的密集使用要求我们做出一些战略性的决定。在作业中,我们调用cache两次。第一次,它按分支查找缓存的文件,默认为master 。如果你的版本库默认的分支不一样,根据需要调整。

缓存工具采用逗号分隔的键列表来查找缓存的文件。它将总是返回找到的第一个匹配文件。
一旦构建完成,我们就会重复这个模式,并保存缓存。这样可以最大限度地提高作业找到活动分支的最新鲜缓存的机会。
静态测试
下一个模块将运行一些静态测试,以确保代码在发布时有足够的Pythonic性。
用+添加块创建一个新的块

向下滚动右边的窗格,直到找到序言。添加以下命令,这些命令在构建工作中可能听起来很熟悉:
checkout
sem-version python 3.8
cache restore pants-$SEMAPHORE_GIT_BRANCH,pants-master
序幕中的命令总是在区块中的任何作业之前运行,确保缓存被检索到:

打开序幕,键入这一行,在作业运行后保存缓存:
cache store pants-$SEMAPHORE_GIT_BRANCH,pants-master $HOME/.cache/pants
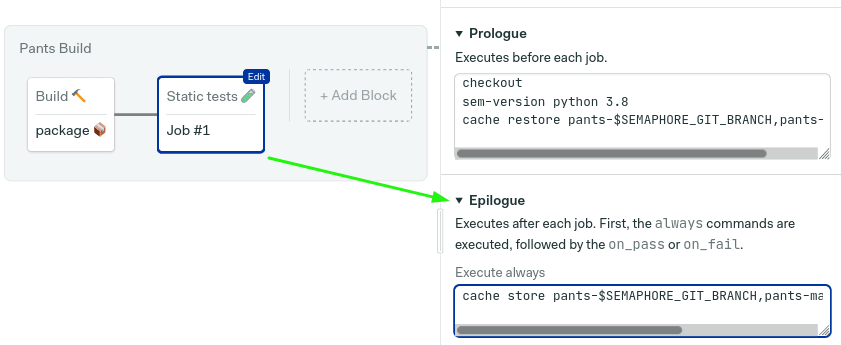
在作业中键入以下命令。这些都是运行linter和typecheck分析器:
./pants lint ::
./pants typecheck ::
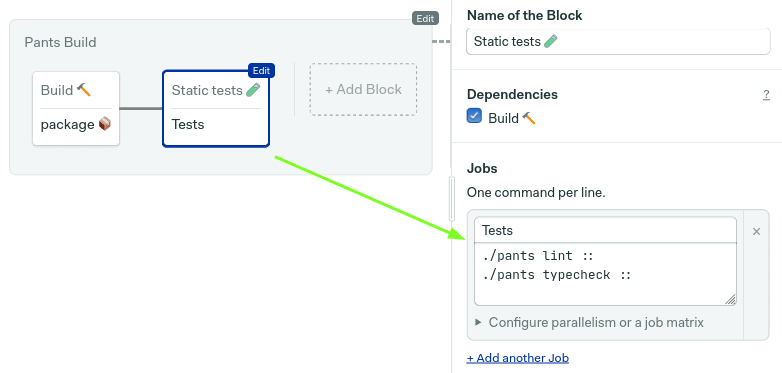
单元测试
我们将再添加一个块来运行单元测试。它将与上一个类似,因为序幕和尾声是一样的。唯一的区别是作业包含一个测试命令。
./pants test ::

至此,CI管道的基本设置结束。我们将在稍后看到优化大型存储库的策略。
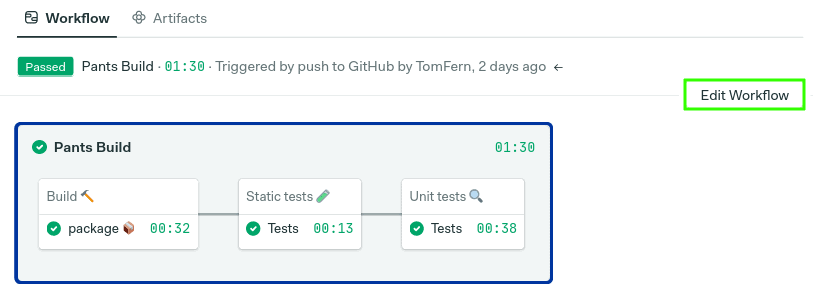
运行流水线
准备好试用管道了吗?点击运行工作流>看起来不错,开始。

第一次运行的时间应该是最长的,缓存是空的。从现在开始,每次代码被提交到版本库时,管道都会自动运行。
Monorepo的优化
Benjy Weinberger,与John Sirois一起的主要开发者之一,在Semaphore Uncut播客中谈到了Pants的起源和设计目标。
"在Pants V2中,一切都被建模为一个工作流程。你的构建被分解成非常多的小步骤。这为你提供了非常细化的无效性。你知道所有的输入,你可以对它们进行指纹识别。你可以并发运行,因为每件工作都被完全封装了,你知道所有的依赖关系。"
Pants团队花了很多心思来确保它与monorepos有良好的扩展性。当被问及monorepo提供的挑战和机会时,Benjy说。"关于扩展你的代码库的问题来自于分析变化以及它们如何通过你的依赖关系传播。你在单版本和多版本中都会遇到这个问题。我为什么要站在单版本的立场上,因为至少他们明确了这个问题。你的第一方依赖关系都和你一起生活在 repo 中。你可以看到所有依赖你的东西,当你做出改变时,你有机会在你的版本库中正确地传播该变化的连锁反应。"
一个CI优化的配置
默认情况下,Pants有一些对开发者友好的功能,如滚动的文本和冗长的信息,我们在CI环境中不需要这些。你可以通过在pants.toml 中添加以下几行来禁用这些功能,并限制并发进程的数量。
process_execution_local_parallelism = 2
dynamic_ui = false
colors = true
你应该确保并行数与CI机器的CPU核心数相匹配。上述设置在Semaphore默认的双核机器上运行良好。如果你使用的是更强大的替代品,你应该增加这个数字以充分利用其资源。
你可以将第二个CI专用的Pants配置文件(例如pants.ci.toml )签入资源库,并通过设置环境变量 PANTS_CONFIG_FILES = pants.ci.toml ,在管道上激活它。
平行作业
在Semaphore中运行并行作业很容易。只需将更多的作业添加到一个块中。管线会处理其余的事情。

然而,对于Pants来说,并行作业会干扰缓存的序列化,因为我们不能确定哪个作业会最后结束,覆盖缓存。如果你想尝试这个功能,你应该考虑为每个作业使用不同的键,比如说。
- Lint job:
pants-lint-$SEMAPHORE_GIT_BRANCH,pants-lint-master - 打字检查工作。
pants-typecheck-$SEMAPHORE_GIT_BRANCH,pants-typecheck-master - 格式化工作:
pants-fmt-$SEMAPHORE_GIT_BRANCH,pants-fmt-master
这里需要注意的是,你可能会更快地用完所有可用的缓冲区。当这种情况发生时,Semaphore会自动删除旧文件。
裤子变化检测
当缓存不够用时,我们可以启用变更检测。由于Pants了解Git的工作原理,它可以检测到过去的变化,并跳过对未变化部分的运行测试。对于在本地机器上测试大型仓库的开发者来说,变化检测是一个福音。
该功能是通过--changed-since 选项启用的。例如,你可以用它来对一个分支在偏离master/main 之后的所有代码进行测试。
./pants test --changed-since=origin/master
更改检测会扫描 Git 仓库并自动选择文件,所以我们不需要在命令中添加任何路径。你可以用它来过滤和选择新的或修改的代码。
如果你想在依赖关系改变时运行测试,你可能需要添加--changed-dependees :
./pants test --changed-since=origin/master --changed-dependees=transitive
如果你想运行最后一次提交中的所有修改:
./pants tests --changed-since=HEAD --changed-dependees=transitive
请记住,除非你改变checkout 命令,否则变化检测在CI环境中不会工作。这是因为Semaphore默认做的是浅层克隆,只下载最新的提交内容。然而,Pants 需要整个历史,所以你需要用完整的版本库做一个完整的签出,使用:checkout --use-cache~ 。
Semaphore变更检测
Semaphore通过change_in函数包括对单程序工作流程的支持。你可以用它来计算变化,而不需要克隆完整的版本库或在 Pants 中使用额外的参数。通常,这将是一个比使用Pants内置变化检测更好的选择。
为了在管道中启用变化检测,你必须围绕子项目重新设计管道。为每个应用程序文件夹或共享库创建一个块。对于我们演示项目的情况,你可以在管道中创建两个独立的CI路径,一个用于commons ,另一个用于hello_world 。主要区别是,我们不使用:: ,而是使用文件夹的路径。比如说:
./pants lint commons/:./pants lint hello_world/:
你可以通过调整块的依赖关系在管道中配置多个并行路径:

你最后应该得到的东西或多或少看起来像这样:

接下来,我们需要告诉Semaphore哪些条件会触发每个块的执行。打开运行/跳过条件部分,选择 "当条件得到满足时运行此块"。

输入以下条件:
change_in('/hello_world/')
这表示:"当hello_world 文件夹内的任何文件发生变化时,运行该块中的作业。"对所有与hello_world 文件夹相关的块应用同样的变化。
为了完成设置,对commons中的代码重复同样的程序(图片中最下面一行的块)。这种情况的条件是:
change_in('/commons/')
注意,如果你的版本库默认分支不是主干,你需要添加一个额外的参数:
change_in('/commons/', { default_branch: 'BRANCH_NAME'})
一旦完成,每个块都应该有一个匹配的条件:

接下来会发生什么?好吧,当我们改变其中一个应用程序时,只有相关的块会被运行,其他的会被跳过,这样可以节省时间和金钱:

不过有一点需要注意,当作业并行运行时,我们可能会丢失一些缓存信息。为了缓解这个问题,你应该尝试为每个应用程序或库使用不同的缓存键。
关于Semaphore变化检测的更多细节,请查看change_in参考页。
接下来的步骤
当需要部署的时候,你可以添加一个持续部署管道。要做到这一点,使用编辑工作流程按钮编辑管道,并点击+添加一个推广:

如果你正在使用AWS Lambda,你很幸运,因为Pants开箱即有AWS的集成。

对于其他目的地,请查看这些资源。
- Python持续集成和部署从零开始。
- 用Docker和Kubernetes部署应用程序。
- 下载我们的免费电子书。用Docker和Kubernetes进行CI/CD。
- Dockerizing a Python Django Application.
最后的话
随着应用程序复杂性的增加,对一个用户友好的、无意义的构建系统的需求也在增加。Pants提供了一种易于使用的体验,适用于各种规模的存储库。
对monorepos感兴趣吗?Semaphore是唯一一个原生支持monorepos的CI/CD平台。请查看这些教程以了解更多。
