

任何参加过PAX游戏大会的人都会遇到一个叫做 "执法者 "的团体(有点像调侃)。这个以社区为主导的团体负责大会的大部分运作,包括从组织活动的排队(以及在活动中招待人们)到管理游戏库或游戏机的借出。传统上,执行者在大会期间通常会使用一个老式的论坛手柄,这样做的目的是为了方便区分具有共同名字的执行者,但也带来了一些个人风格--在PAX期间,一些人甚至喜欢用手柄而不是他们的真名来称呼。像Waterbeards、Gundabad、Durinthal、bluebombardier、Dandelion、ETSD、Avogabro或IaMaTrEe这样的手柄会从普通的名字、双关语、个人背景或文学/流行文化中汲取不同的灵感。
在今年二月的PAX East上,我们想到了建立一个模型来生成新的Enforcer手柄的想法。这是一个序列模型的完美用例,就像一个循环神经网络--通过对数据序列的训练,该模型学会了为给定的种子生成新的序列(在这种情况下,根据迄今为止的单词预测每个连续的字符)。
我们在这里的目标是双重的。
- 探索在PyTorch中构建一个递归神经网络(这对我来说是一个新的领域,因为我们大多数的生产实现是在Tensorflow中进行的)。
- 展示转移学习的力量。
让我们深入了解一下吧
用于序列建模的递归神经网络
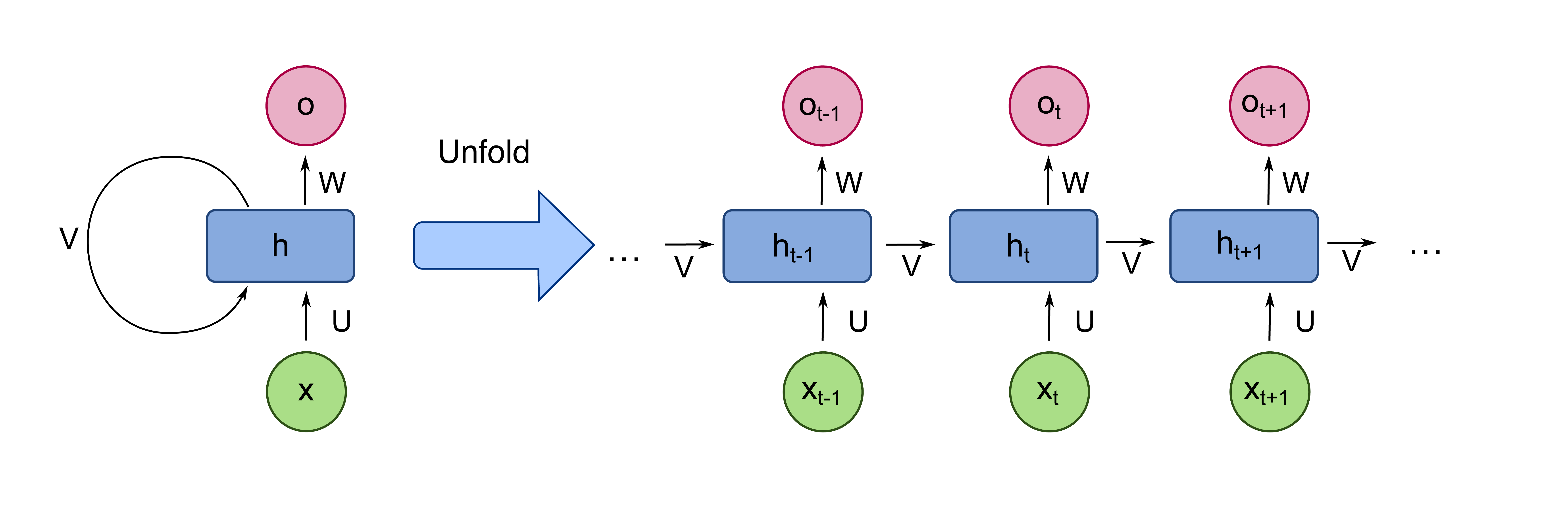
在对序列数据(音频、自然语言文本等)进行建模时,我们需要仔细考虑我们的架构--序列中每个点之间的时间互动经常比任何给定的单点的内容重要得多。因此,我们需要一种方法来组装和编码序列的互动,并将其与序列中每个点的输入相结合,以产生有意义的输出。循环神经网络(RNN)通过在网络中编码一个与序列相关的 "隐藏状态 "来实现这一点--在每个时间步骤中,网络同时接受该步骤的输入和上一步骤的隐藏状态,并使用它来生成该时间步骤的输出和传递给下一步骤的最新隐藏状态,如下所示。
 © Wikimedia Commons User:fdeloche /CC-BY-SA-4.0
© Wikimedia Commons User:fdeloche /CC-BY-SA-4.0
这种架构可以处理输入和/或输出的单个或多个值的映射,也就是说,我们可以做多对一、多对多、或一对多的处理任务。例如,我们可能关心序列分类的多对一映射,输入一连串的输入并生成一个单一的输出标签。不过,RNN特别适用的地方是多对多的任务(也叫序列对序列),输入一系列的输入并生成一个新的、不同的序列(例如,向谷歌翻译输入一句英文文本并得到一个法语句子)。
原则上,网络对隐藏状态的操作可以很简单--以输入和隐藏状态向量的线性组合和早期埃尔曼网络中发现的典型非线性激活(例如,一个sigmoid函数)为例。然而,由于这本质上相当于构建了一个极深的前馈网络(每个时间步长的层数倍增),这将受到 "梯度消失 "问题的影响,因为参数更新逐渐变弱,与权重有关的较小梯度的损失通过网络的许多层的连锁而变得复杂,网络将陷入不可训练的状态。在一个递归网络中,这产生了网络在足够长的序列中 "失去信息 "的效果。
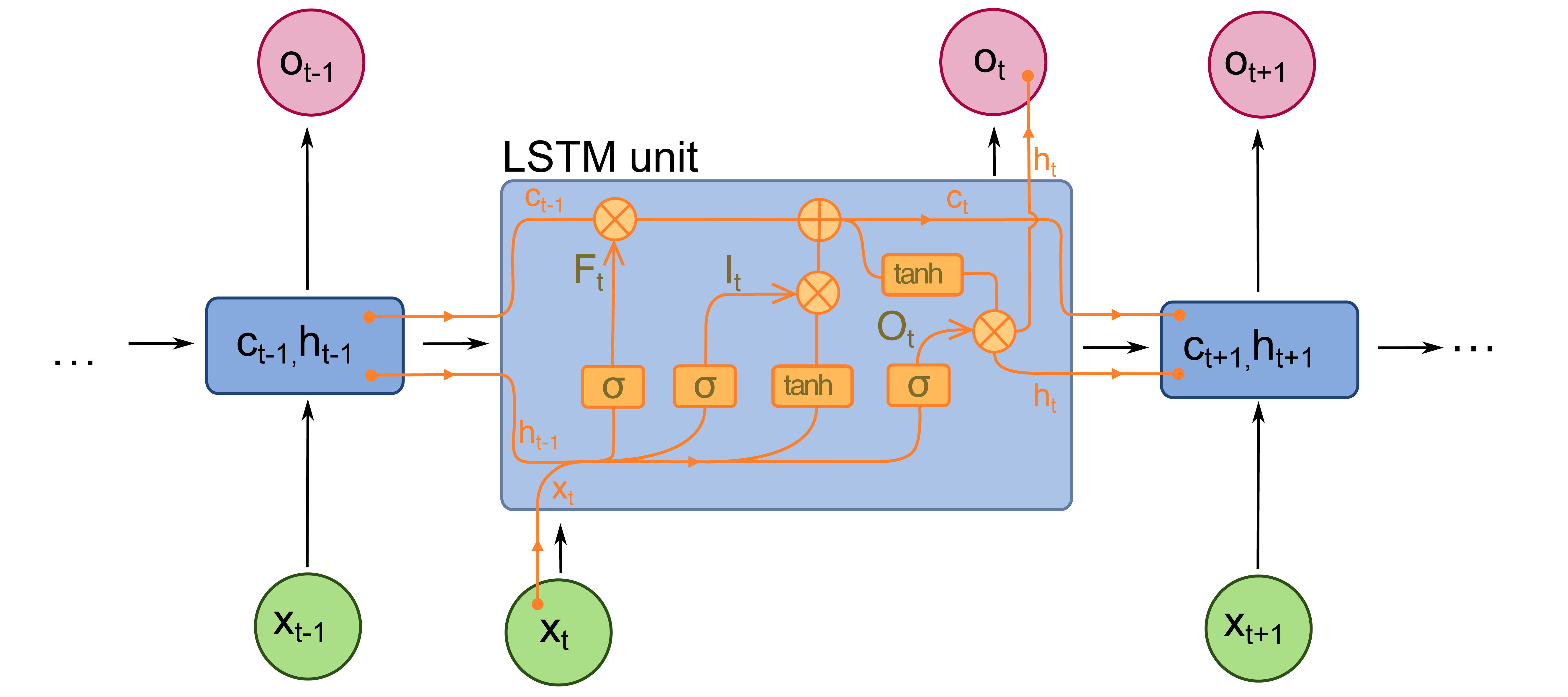
因此,最近关于序列的深度学习的许多研究都集中在对长序列的信息保留上。例如,长短期记忆(LSTM,如下图所示)或门控递归单元(GRU)网络包括单独的可学习参数,专门用于在长序列中保留或遗忘信息,而不是通过梯度更新在序列的每个点上盲目地压制参数。
 © Wikimedia Commons User:fdeloche /CC-BY-SA-4.0
© Wikimedia Commons User:fdeloche /CC-BY-SA-4.0
最近,研究特别关注序列到序列模型的注意力机制--注意力层学会对序列中的每一个点给予提升或抑制的权重,而不依赖于中间的步骤(而递归机制本质上必须通过每一个介入点来计算其状态)。这实质上是学会了对某些其他的点给予特别的关注(因此而得名),而不管它们在序列中的距离有多远,从而增强了网络在长序列中保留信息的能力。虽然注意力可以与递归操作结合使用,但最近的研究在Transformer架构中达到了顶峰,该架构完全摒弃了递归操作,只依赖注意力机制。基于Transformer的语言模型,如BERT或GPT-2(以及现在的GPT-3),是目前一些语言建模任务中最先进的。
由于我们在这项任务中使用的是相对较短的序列,我们现实中不必太在意保留序列的长期信息。然而,PyTorch包括建立更复杂的组件(如LSTM或GRU)的cookiecutter方法,所以我们使用更现代的方法并没有真正失去什么--我们将为这个项目使用LSTM层。
当我们的数据不足时,我们该怎么做?
在现代深度学习中,潜在的模型复杂性很容易超过你要训练它的数据规模。例如,InceptionV3计算机视觉架构,有大约2300万个可调整的参数,如果你只有几千张图片来训练,就不一定能帮助你。更糟糕的是,GPT-2自然语言模型,有大约15亿个参数,不仅需要在一个完全巨大的文本语料库上学习,而且其训练的计算成本非常高,以至于它有很大的碳足迹。幸运的是,有几种技术可以利用更大的独立数据集和/或以前的计算,从相对有限的数据中引导出复杂的模型--在这里,我们将考虑预训练和转移学习。
在这两种情况下,我们在其他数据上重复使用以前的计算:对于一个给定的模型架构,我们不是用随机初始化的权重从头开始训练模型,而是用以前训练过的权重实例化部分或全部模型。然后,我们可以将这些权重作为微调的 "温暖 "起点,或者干脆原封不动地使用它们,基本上作为一个固定的函数,将我们的输入转换成一些学习过的表征。通过这样做,我们把一个大的模型结构有效地减少到一个更适合我们的数据大小和时间限制的小模型。
通过简单的预训练,我们期待着基本相同的数据作为输入。例如,我们可以使用预训练的无监督词嵌入作为更大的语言模型的输入,但在这种情况下,我们只是按原样使用词级嵌入,将我们的文本转换成密集的向量表示。实际上,我们假设预训练中使用的输入与我们感兴趣的数据的分布大致相同。(在某些情况下,它可能真的是相同的分布--模型的 "热启动 "训练对于随着更多的数据进入一个由ML驱动的系统而持续更新一个实时模型是非常有用的)。
不过,这些技术真正闪耀的地方是转移学习--也就是说,我们使用一个在与我们实际使用情况完全不同的数据集上训练的模型,旨在利用数据集之间的潜在相似性。我发现这在计算机视觉模型的案例中最容易直观化(尽管它也适用于许多其他情况!)。在一个深度卷积神经网络中,最早的几层正在学习相对简单的过滤器(识别诸如明暗或尖锐边缘的东西),这在任何图像中都很常见。因此,与其在一个小的、专门的数据集上从头开始训练,我们可以利用在ImageNet这样的大规模数据集上训练出来的深度架构来训练模型的早期层,而只需要担心为我们的特定任务训练最后几层。因此,我们可以(例如)使用一个最先进的架构,尽管数据集很小(例如,二进制的 "热狗与非热狗 "分类)--即使该标签集根本不在原始的、共享的训练数据中
在我们的句柄生成器的情况下,这将是绝对必要的,因为我们只有少数现有的Enforcer句柄可以使用。然而,我们的RNN的大部分任务将仅仅是找出哪些字符组合作为音素具有模糊的感觉(这可能是一个很高的要求,因为英语正字法是一个有点垃圾的火),所以没有什么可以阻止我们使用其他英语文本(甚至其他人类名字)来处理大部分的训练
数据准备
对于我们这里的工作,我们将使用三个数据源。
- 弗兰肯斯泰因的全文*;或者,玛丽-沃斯顿克拉夫特-雪莱的《现代普罗米修斯*》(可在古腾堡项目的公共领域获得)。
- 一组由Faker生成的真实姓名,它发出了常见的姓和名的排列组合,并带有随机的后缀。
- 我们的Enforcer处理数据集(通过选择从社区收集,出于隐私原因,在本文中有些模糊)。
我们将使用一般文本和真实姓名数据集来调整我们的模型,以生成可读音素和类似姓名结构的合理组合,然后再对Enforcer手柄进行微调。为了保持一致性,我们将强制进行一些转换(比如允许连字符或大写字母的单词),但除此之外应该不需要太多的预处理。
文本表示
首先,我们需要用数字表示我们的文本输入--对于一个词级模型来说,这需要对停顿词进行处理,可能还要对单词进行词干化或外文处理,对一个大的(可能是数以百万计的独特标记)词汇进行标记化和矢量化,这本身可能是相当复杂和昂贵的计算。幸运的是,表示一个字符级的数据集要简单得多--我们只需要表示每个小写和大写的ASCII字母,加上连字符和撇号(因为我们想为我们的生成器保留这些),我们可以在查找字典中从头开始做。
LETTERS = string.ascii_letters + "-'"
charset_size = len(LETTERS) + 1 # add one for an EOS character
char_index = {char: i for i, char in enumerate(LETTERS)}
inverse_index = {i: char for char, i in char_index.items()}
inverse_index[charset_size - 1] = "<EOS>"
这就建立了每个字符的序号索引,再加上它的逆序(其中我们还包括一个序列末尾的字符,它不会出现在我们的输入数据中,但可以由生成器产生)。
接下来,我们需要用这些指数来表示文本的PyTorch张量。具体来说,我们需要在序列的每一步将字符的数字索引编码为输入,并将序列中下一个字符的索引(包括一个明确的序列结束标记)作为输出--然后我们将训练网络在每个时间步骤中连续预测序列中的下一个字符。
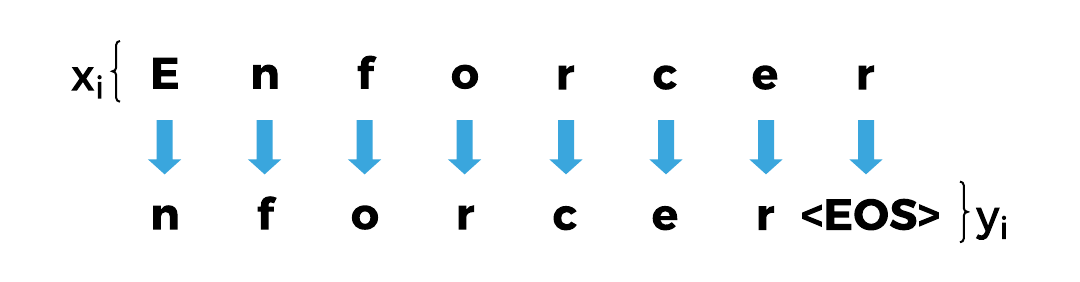
我们将使用一个tensorize 函数来为一个输入文本建立这些。我们可以使用这个输入张量来生成一个单热编码(即用非零指数表示哪个字符的二进制向量),但现在我们将布置我们的网络架构,以便我们只需要输入和输出的每个字符的整数指数。
TensorPair = typing.Tuple[torch.LongTensor, torch.LongTensor]
def tensorize(word: str) -> TensorPair:
input_tensor = torch.LongTensor([char_index[char] for char in word])
eos = torch.zeros(1).type(torch.LongTensor) + (charset_size - 1)
target_tensor = torch.cat((letter_indices[1:], eos))
return input_tensor, target_tensor
PyTorch中的数据管理
为了管理我们的输入,我们将使用PyTorch的内置数据管理器--Dataset 和DataLoader 类。Dataset 类为我们提供了一个有用的封装器来管理数据的加载和预处理--我们只需要提供一种方法来访问作为底层迭代器的数据("迭代器式")或通过定义已知范围的数据的索引查找("地图式")。
例如,我们可以像下面这样表示我们的弗兰肯斯坦数据集。
class FrankenDataset(torch.utils.data.Dataset):
def __init__(self, path_to_text: str):
with open(path_to_text, "r") as rf:
text = rf.read()
text = text.replace("\n", " ").strip() # compress newlines
text = re.sub(r"[^a-zA-Z\-' ", "", text) # strip undesired characters
text = re.sub(r" {2,}", " ", text) # compress whitespace runs to single space
self.words = text.split(" ")
def __len__(self) -> int:
return len(self.words)
def __getitem__(self, idx: int) -> TensorPair:
return tensorize(self.words[idx])
在这里,我们在数据集初始化时处理了所有的字符串清洗,只需要提供__len__ 和__getitem__ 方法来支持地图式访问。这个类将其所有的数据加载到内存中--对于这样一个小的数据集(对于弗兰肯斯坦来说,大约7500个标记)来说,这不是一个问题,但是对于非常大的数据集来说,这就不适用了。然而,通过一些聪明的方法和磁盘缓存,我们可以(例如)使用__getitem__ 方法来代替懒惰地从磁盘加载数据,并且只需要存储一个参考位置列表。
一旦我们定义了一个Dataset ,我们就可以通过一个DataLoader ,来管理数据的洗牌和批处理(在这里是微不足道的,因为我们使用单样本迷你批来简化对可变长度序列的处理)。
frank = FrankenDataset(path_to_text)
franken_loader = torch.utils.data.DataLoader(frank, batch_size=1, shuffle=True)
为了将数据送入我们的模型,我们只需在franken_loader 对象上循环,它将在每次迭代中产生洗牌、随机化的批次(在我们的例子中是单样本)。(用户应该注意,DataLoader 会在Dataset 发出的张量前面增加一个batch 的维度,长度为batch_size )。
像我们在FrankenDataset 中使用的地图式数据集需要我们知道数据集的整个范围,并且能够直接通过索引访问样本(然后DataLoader 使用它来生成随机的批次)。不过在某些情况下,直接支持对数据本身的迭代可能更简单(例如,当从流式系统中消耗数据时)。对于这些使用情况,较新的(1.2以上版本)PyTorch支持一个IterableDataset 类型,它只需要定义一个返回Python可迭代的__iter__ 方法--然后DataLoader 将简单地按顺序访问这个迭代器,而不是通过随机选择的索引来构造批次。
对于我们的Faker 生成的真实姓名,我们的数据已经有了很好的随机化程度,所以这应该是很简单的。我们甚至可以从多个国家的本地化中生成名字,尽管我们需要注意确保我们符合我们所选择的字符集--这意味着将unicode字符折叠成ASCII等价物,并跳过那些不容易被ASCII翻译的提供者(尽管Faker 本身在提供非拉丁字母的数据方面没有问题!)。在这种情况下,我们将把芬兰语、西班牙语、德语和挪威语的名字与我们常见的英语名字一起撒进这个组合。我们可以生成这些名字,清除ASCII字符并强制执行最小长度,并随机地将它们转化为连字符或大写字母(因为这两者都可以出现在我们的Enforcer句柄中),然后在由__iter__ 方法返回的生成器中发出,如下所示。
class FakerNameDataset(torch.utils.data.IterableDataset):
def __init__(self, n_samples=5000):
self.n_samples = n_samples
self.namegen = faker.Faker( # draw from multiple language providers
OrderedDict([
("en", 5),
("fi_FI", 1),
("es_ES", 1),
("de_DE", 1),
("no_NO", 1)
])
)
def __iter__(self) -> Iterable[TensorPair]:
return (tensorizer(self.generate_name()) for _ in range(self.n_samples))
def generate_name(self) -> str:
name = self.namegen.name()
# fold unicode characters to nearest ascii
name = "".join(
char for char in unicodedata.normalize("NFKD", name)
if not unicodedata.combining(char)
)
# clean further characters
name = re.sub("[^a-zA-Z\-' ]", "", name)
# randomly map to hyphenated or CapCased
if random.uniform(0, 1) < 0.5:
return name.replace(" ", "")
else:
return name.replace(" ", "-")
这与PyTorch的DataLoader ,我们甚至不需要设置批处理或洗牌的参数,就可以开箱即用。
names = FakerNameDataset(n_samples=30000)
name_loader = torch.utils.data.DataLoader(names)
最后,我们的Enforcer数据集很简单,因为句柄已经被很好地格式化了,所以这将被结构化为一个EnforcerHandleDataset ,与FrankenDataset 相同。
建立我们的网络
原则上,我们可以只用PyTorch的张量操作(毕竟,神经网络只是一大堆线性代数)和激活函数来构建我们的RNN--但这对于复杂的组件(如LSTM)来说是很繁琐和过分困难的。相反,我们将使用PyTorch的直接构建模块来定义我们的网络。
为此,我们将RNN定义为torch.nn.Module 的子类,它封装了网络的结构和操作,并且开箱即有状态跟踪、梯度计算等所需的所有设置。我们只需要将网络中的组件(这些组件本身就是Module 子类)定义为__init__ 中的属性,以及一个forward 方法,该方法规定了流经网络的数据的 "前向传递"(输入-预测)的计算过程。
class CharLSTM(torch.nn.Module):
def __init__(
self,
charset_size: int,
hidden_size: int,
embedding_dim: int = 8,
num_layers: int = 2
):
super(CharLSTM, self).__init__()
self.charset_size = charset_size
self.hidden_size = hidden_size
self.embedding_dim = embedding_dim
self.num_layers = num_layers
self.embedding = torch.nn.Embedding(charset_size, embedding_dim)
self.lstm = torch.nn.LSTM(
embedding_dim,
hidden_size,
batch_first=True,
num_layers=num_layers,
dropout=0.5
)
self.decoder = torch.nn.Linear(hidden_size, charset_size)
self.dropout = torch.nn.Dropout(p=0.25)
self.softmax = torch.nn.LogSoftmax(dim=2)
def forward(self, input_tensor, hidden_state):
embedded = self.embedding(input_tensor)
output, hidden_state = self.lstm(input_tensor, hidden_state)
output = self.decoder(output)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden_state
def init_hidden(self):
return (
torch.zeros(self.num_layers, 1, self.hidden_size),
torch.zeros(self.num_layers, 1, self.hidden_size)
)
这是相当密集的,所以让我们在forward 通路中一个接一个地完成这些组件。
-
我们传入由
tensorize()产生的input_tensor和我们的DataLoader。这是一个大小为(batch_len, sequence_len)的整数张量,代表字符索引。(记住,我们在这里使用的是单样本的迷你批,所以batch_len = 1。) -
嵌入层根据输入中每个字符的索引(这只是每个字符的单热向量的稀疏表示)抓取一个
embedding_dim大小的密集向量。这就产生了一个大小为(batch_len, sequence_len, embedding_dim)的浮点数张量。原则上,我们可以跳过这一步,直接将大小为(batch_len, sequence_len, charset_size)的单热向量传递给LSTM层--因为我们的字符集 "词汇量 "很小,这不是一个可怕的稀疏表示(因为它将是单词级的表示)。不过,在实践中,将字符集向量减少到一个小的嵌入向量可以提高性能,所以我们不妨保留它。(这也意味着你可以将这种相同类型的网络结构原封不动地用于词级表示,用你的标记器的词汇量来代替charset_size)。 -
我们通过LSTM层运行这个字符表示--这也需要一组表示隐藏状态和单元状态的张量(保存在
hidden_state,并通过init_hidden(),初始化为零)。这可以一次性跟踪网络在序列中每一步的状态,所以我们不需要明确地迭代序列,对于单次采样批次来说,完全可以处理可变长度的序列。这将产生一个大小为(batch_len, sequence_len, hidden_size)的张量以及更新的隐态张量。 -
一个密集连接的线性层将LSTM输出解码回我们的字符集,产生一个大小为
(batch_len, sequence_len, charset_size)的张量。这个张量在训练过程中也被送入剔除层,它将在每次训练时概率性地忽略个别连接。 -
这将通过一个
LogSoftmax,它将张量的最后一个维度转换为每个字符的softmax概率的对数。实际上,我们在这里建立了序列模型中常见的编码器-解码器架构--我们的嵌入层和LSTM层将输入编码为学习的内部表示,而线性层和softmax将其解码为原始字符的表示。这既产生了我们的负对数似然成本函数所期望的形式,也产生了可解释的输出,因为序列中每一步的最大对数概率值表示其预测的下一个字符。 -
然后我们返回大小为
(batch_len, sequence_len, charset_size)的概率输出张量和更新的隐藏状态,以用于下一个训练或推理步骤。
我们像一个典型的Python类一样初始化模型,并可以看到我们所建立的模型。
rnn = CharLSTM(charset_size, hidden_size=128, embedding_dim=8, num_layers=2)
其中产生
>>> print(rnn)
CharLSTM(
(embedding): Embedding(55, 8)
(lstm): LSTM(8, 128, num_layers=2, batch_first=True, dropout=0.5)
(linear): Linear(in_features=128, out_features=55, bias=True)
(dropout): Dropout(p=0.25, inplace=False)
(softmax): LogSoftmax()
)
我们可以通过将种子文本转换为张量,给网络打底,并通过输入之前生成的字符连续生成输出,从中抽取样本。
def sample(
seed: str,
max_len: int = 10,
break_on_eos: bool = True,
eval_mode: bool = True
) -> str:
# optionally set evaluation mode to disable dropout
if eval_mode:
rnn.eval()
# disable gradient computation
with torch.no_grad():
input_tensor, _ = tensorize(seed)
hidden = rnn.init_hidden()
# add the length-1 batch dimension to match output from Dataset
input_tensor = input_tensor.unsqueeze(0)
output_name = seed
for _ in range(max_len):
out, hidden = rnn(input_tensor, hidden)
_, topi = out[:, -1, :].topk(1) # grab top prediction for last character
next_char = inverse_index[int(topi.squeeze())]
if break_on_eos and (next_char == "<EOS>"):
break
output_name += next_char
input_tensor = topi
# ensure training mode is (re-)enabled
rnn.train()
return output_name
这里有两个重要的特征需要注意,因为它们是PyTorch的API的一个有点不直观的方面:torch.no_grad() 上下文块,以及rnn.eval()/rnn.train() 的设置。no_grad() 上下文块禁用了自动梯度计算,防止模型在推理过程中更新其权重,并释放了不需要的内存和计算,这些内存和计算本来是用于通过网络跟踪梯度。train()/eval() 设置在 "训练 "和 "评估 "模式之间切换模型,这改变了forward 过程中某些层的行为--例如,在训练模式下,放弃调用将随机跳过某些权重,而在评估模式下,每个权重都被使用。
这在大多数推理任务中是很重要的,因为如果没有它,预测输出的可信度会降低,而且从根本上说是不确定的(因为权重是随机放弃的),建议在推理过程中使用这两种设置。然而,我们可以选择在评估模式关闭的情况下进行推理(因此,dropout开启),为我们的预测引入一些随机性,这应该与在我们的输出中使用温度有类似的效果。
训练!
当然,现在从网络中抽取样本会产生胡言乱语,因为网络仍然在使用其随机初始化的权重。
for _ in range(10):
seed = random.choice(string.ascii_lowercase)
print(f"{seed} --> {sample(seed)}")
结果是
v --> vllllllllll
d --> dllllllllll
j --> jllllllllll
z --> zllllllllll
f --> fllllllllll
d --> dllllllllll
w --> wllllllllll
e --> ellllllllll
f --> fllllllllll
q --> qllllllllll
我们需要在我们的数据集上训练该网络。在PyTorch中,这遵循一个相当典型的模式,尽管它比Keras之类的高级抽象明显更详细(在大多数情况下,你只需调用一个fit 方法),尽管裸Tensorflow遵循类似的结构。一般来说,每个训练步骤将做以下工作。
- 将存储在模型中的梯度清零
- 为训练输入计算模型的输出
- 根据预定的损失函数,计算该输出与该训练样本之间的损失。
- 通过PyTorch的自动梯度跟踪,计算模型中与该损失有关的梯度
- 采取优化措施,根据计算的梯度更新模型的权重。
在代码中,这看起来就像
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.RMSprop(rnn.parameters(), lr=0.0001)
def train_step(
input_tensor: torch.LongTensor,
target_tensor: torch.LongTensor
) -> float:
optimizer.zero_grad()
hidden = rnn.init_hidden()
out, hidden = rnn(input_tensor, hidden)
loss = criterion(output[0, :, :], target_tensor[0, :])
loss.backward() # computes gradients w.r.t. and stores gradient values on parameters
optimizer.step() # is already aware of the parameters in the model, uses those gradients
return loss.item() # grabs value of NLL loss, rather than graph tracking
其中,我们使用了一个负对数似然损失函数(NLLLoss)和一个RMSprop优化器(当然我们也可以使用torch.optim 提供的其他选项之一,如纯随机梯度下降或亚当)。我们通过对我们选择的DataLoader 对象进行迭代来传递成批的数据(在我们的例子中,是单个样本)。
losses = []
running_loss = 0.0
for epoch in range(n_epochs):
looper = tqdm.tqdm(franken_loader, desc=f"epoch {epoch + 1}")
for i, tensors in enumerate(looper):
loss = train_step(*tensors)
running_loss += loss
losses.append(loss)
if (i+1) % 50 == 0:
looper.set_postfix({"Loss": running_loss/50.})
running_loss = 0
弗兰肯斯坦预训练
经过两个历时的训练,采样器已经开始产生有意义的结果(包括收敛到一些常用词)。
seed --> output
---------------
c --> could
h --> he
g --> gare
k --> kear
t --> the
p --> prome
e --> ender
v --> ve
a --> a<EOS>
而在进一步的两个历时之后,训练损失基本稳定了。
seed --> output
---------------
n --> not
y --> you
h --> he
e --> ever
q --> quitted
z --> zhe
w --> was
d --> destreated
j --> jound
s --> so
v --> very
p --> part
l --> life
r --> rest
x --> xone
我们可以通过禁用评估模式(这意味着在采样过程中,剔除层仍然处于活动状态)看到结果的多样性。这应该会在一定程度上降低输出(因为它是随机失去连接的,它不应该再输出下一个字符的最佳可能性估计),但对于改变我们的输出是必要的。在评估模式下,对一个给定的种子的输出是确定的,所以我们对每个种子只产生一个字,扩展到对一个较长的序列进行采样是无益的,因为输出通常会在产生一个EOS字符后消失。对于我们的用例来说,能够生成一些候选词是很有用的--坦率地说,为我们生成的词引入一点无政府状态也是很酷的。
seed --> output
---------------
e --> evil
e --> endeares
e --> expented
e --> endear
e --> eves
e --> earss
e --> eart
e --> exest
e --> enter
e --> endestent
e --> ente
e --> eviled
e --> endeares
在这一点上,为我们的模型保存一个检查点是个好主意,我们可以在以后的训练步骤中迭代返回。在PyTorch中,我们可以把模型和优化器的state_dict 对象保存到一个对象中--只要我们能够实例化相同的对象类,我们就可以加载这些对象来重建模型和训练环境的快照状态。由于这与一般的Python对象序列化一起工作(虽然传统上这些保存文件被标记为.pt 或.pth ,它只是在引擎盖下使用pickle ),我们也可以将其他训练元数据捆绑进去。
torch.save(
{
"model_state_dict": rnn.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"losses": losses
},
pretrain_save_filepath
)
人名调整
我们现在准备开始微调我们的模型了。如果我们想在一个新的Python会话中重新开始,我们可以很容易地加载我们保存的检查点,如下所示。
rnn = CharLSTM(charset_size, hidden_size=128, embedding_dim=8, num_layers=2)
optimizer = torch.optim.RMSprop(rnn.parameters(), lr=0.0001)
checkpoint = torch.load(pretrain_save_filepath)
rnn.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
losses = checkpoint["losses"]
注意,我们需要创建一个新的rnn 和optimizer 对象的实例,并且模型需要与原来的结构相同--如果你在加载模型实例的状态字典时看到一个<All keys matched successfully> 消息,你就会知道它走对了。在加载了我们的模型之后,微调训练仅仅是恢复上面的训练循环,但要通过name_loader ,从Faker 生成的名字数据集中输入。
running_loss = 0.0
looper = tqdm.tqdm(name_loader, desc="name fine tuning")
for i, tensors in enumerate(looper):
loss = train_step(*tensors)
running_loss += loss
losses.append(loss)
if (i+1) % 50 == 0:
looper.set_postfix({"Loss": running_loss/50.})
running_loss = 0
由于对一般文本的预训练已经完成了很多繁重的工作,我们在这个阶段可以使用一个小得多的数据集。在3万个样本之后(只占初始阶段训练次数的10%),模型已经学会了产生类似于名字的结构(回顾一下,在我们的FakerNameDataset ,我们随机地将名字中的空格转换成连字符或大写字母)。
seed --> output
---------------
M --> Maria-lonson
B --> Bannandensen
U --> Uord-Harder
P --> Pari-Mil
P --> Panne-Marker
U --> Uondartinen
B --> Bannes-Hereng
I --> Iten-Mis
K --> Karin-Marsens
I --> Ibene-Merias
I --> Ingen-Markenen
M --> Maria-Moche
I --> Inan-Borgen
A --> Annan-Mort
Z --> Zark-Hors
L --> Lauran-Malers
G --> Gark-Harrin
I --> Ing-Sandand
I --> Ine-alland
I --> Ingen-Ming
值得注意的是,它已经掌握了某些高度结构化的模式,比如芬兰和挪威姓氏中常见的*-nen和-sen结尾。它还学会了生成明显较长的序列,从产生序列末尾标记前的平均3.5个字符跃升至约12个字符。也就是说,与初始训练阶段相比,它的训练损失明显增加了--这是可以预期的,这既是由于初始训练和微调之间数据集的转变,也是由于与弗兰肯斯坦*中更常见的词相比,从名字数据集中输入的字符序列的熵增加了。
当然,我们可以让模型在命名数据集上运行更长的时间,并可能进一步减少这种损失。现实上,这可能会导致它开始从相对有限的库存中记忆名字,Faker ,所以这可能足以满足我们的目的。
执法者处理!
最后,我们准备好了(在为我们模型的训练状态保存另一个检查点之后)进行最后一轮,直接对Enforcer手柄进行训练。由于我们处理的数据集比第一轮的一般英文文本小了好几个数量级,所以直接在Enforcer数据集上训练如此复杂的模型是完全不可行的。然而,我们还是能够利用在更一般的数据集上所做的大量工作来使我们的模型达到大部分的效果--具有讽刺意味的是,在这些数据上的短暂训练周期有效地导致它失去了一些先前的知识,尽管这符合我们生成更有趣的名字的目的
在20个历时之后(对于我们这个基本上是玩具规模的数据集来说是必要的),我们可以开始对网络进行采样以生成名字。我最喜欢的一些名字(从随机的一到三个字符的种子中抽取)。
seed --> output
---------------
a --> andelian
s --> saminthan
C --> Carili
b --> bestry
E --> EliTamit
G --> Gusty
L --> Landedbandareran
M --> Muldobban
I --> Imameson
T --> Thichy
G --> Gato
b --> boderton
K --> KardyBan
c --> cante
s --> sandestar
o --> oldarile
L --> Laulittyy
P --> Parielon
X --> Xilly
E --> Elburdelink
Be --> Beardog
Ew --> EwToon
Zz --> Zzandola
Ex --> Exi-Hard
Sp --> Spisfy
Sm --> Smandar
Yr --> Yrian
Fou --> Foush
Qwi --> Qwilly
Ixy --> IxyBardson
Abl --> Ablomalad
Ehn --> Ehnlach
Ooz --> Oozerntoon
当然很傻,但其中任何一个都可以作为一个手柄,同时又与任何一个输入的手柄不同,是可信的。网络在一定程度上记住了现有Enforcer句柄的模式,所以这些句柄偶尔会出现(特别是在评估模式下,为了获得 "最准确 "的输出),但任何接近的匹配都被排除在这里。我认为这是一个绝对的胜利!
总结
在这篇文章中,我们看到了在PyTorch中布置一个高性能的递归神经网络,并使用它来生成有趣的、流畅的、适合任何一群执法者的绰号是多么简单(大约100行直接的、可读的代码)。虽然我们只有相对较少的原始手柄--对于训练如此复杂的模型来说太少了--但我们能够利用其他的数据源(一般的英文文本,已知的个人名字)来启动我们的学习过程,从而能够在更小的数据上进行训练,并加快迭代速度(即使在CPU上也能在合理的时间范围内运行后来的训练周期)。虽然这种转移学习过程是训练深度学习模型的有力工具,但我们必须小心一点,因为我们的目标数据越是在原始训练领域之外,我们的性能就越有可能下降。
我们没有触及一些更高级的话题,比如在训练过程中使用注意力或可变教师强迫(而不是这里使用的100%强迫),或者在GPU上运行我们的代码。但我们已经看到,使用现代框架,即使是建立一个复杂的神经网络也是非常容易的。从开发的角度来看,PyTorch长期以来一直强调简洁的Pythonic代码,这使得原型设计变得很容易。由于PyTorch被设计为动态执行其图形,我们可以在变量序列上强制性地执行单个张量操作,并在交互式外壳中检查我们的输出,这对于调试来说是非常好的(尽管Tensorflow 2.0也为其图形引入了急迫执行)。
总而言之,与Tensorflow相比,PyTorch对于一个Python开发者来说,开始编写功能代码的学习曲线可能更浅,尽管仍有一些设计方面(比如编写训练循环所需的模板)我不太喜欢。无论如何,我很高兴看到很多我确实喜欢的PyTorch的设计决策被带入Tensorflow生态系统,同时保留了它的优势(比如tensorflow-serving 中的模型部署故事)。
