

在这篇文章中,我们将学习如何用GitHub Actions和AWS建立一个CI/CD管道。我把指南分为三个部分,以帮助你完成工作:
首先,我们将介绍一些重要的术语,这样你就不会迷失在一堆大的流行语中。
其次,我们将设置持续集成,以便我们能够自动运行构建和测试。
最后,我们将设置持续交付,以便我们可以自动将我们的代码部署到AWS。
好吧,那是一个很大的问题。让我们开始深入研究这些术语,以便你确切地了解我们在这里做什么。
第一部分:解密那些沉重的流行语
理解这篇文章标题的关键在于理解CI/CD管道、GitHub行动和AWS这些术语。
如果你已经很好地掌握了这些术语的含义,你可以直接跳到第二部分。
什么是CI/CD管线?
CI/CD管道是一种简单的开发实践。它试图回答这一个问题。*我们怎样才能更快地将高质量的功能运送到我们的生产环境?*换句话说,我们怎样才能在不影响质量的情况下加快功能的发布过程?
你可能会问,CI/CD管道是如何帮助我们加快功能发布过程的?
下图描述了一个有无CI/CD管道的典型功能交付周期:
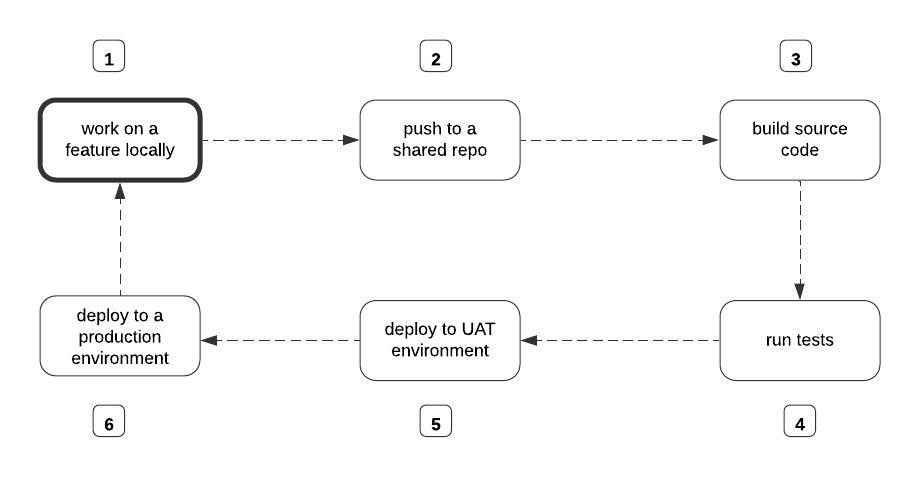
功能发布流程来源作者
如果没有CI/CD管道,上图中的每个步骤都将由开发人员手动完成。实质上,为了构建源代码,你的团队中有人必须手动运行命令来启动构建过程。运行测试和部署也是如此。
CI/CD方法是对手工做事方式的彻底转变。它完全基于这样一个前提: ,如果我们把上图中的第3-6个步骤自动化,就可以合理地加快功能发布过程。
通过CI/CD管道,我们建立了一个机制,自动启动构建过程,运行测试,部署到用户验收测试(UAT)环境,最后在每次团队成员将他们的变化推送到共享的 repo时,自动部署到生产环境。
持续集成在每次启动构建过程时发生,并在新的变化上运行测试。
持续交付发生在新集成的变化被自动部署到UAT环境,然后从那里手动部署到生产环境。
持续部署发生在UAT环境中的更新被自动部署到生产环境中作为正式版本。
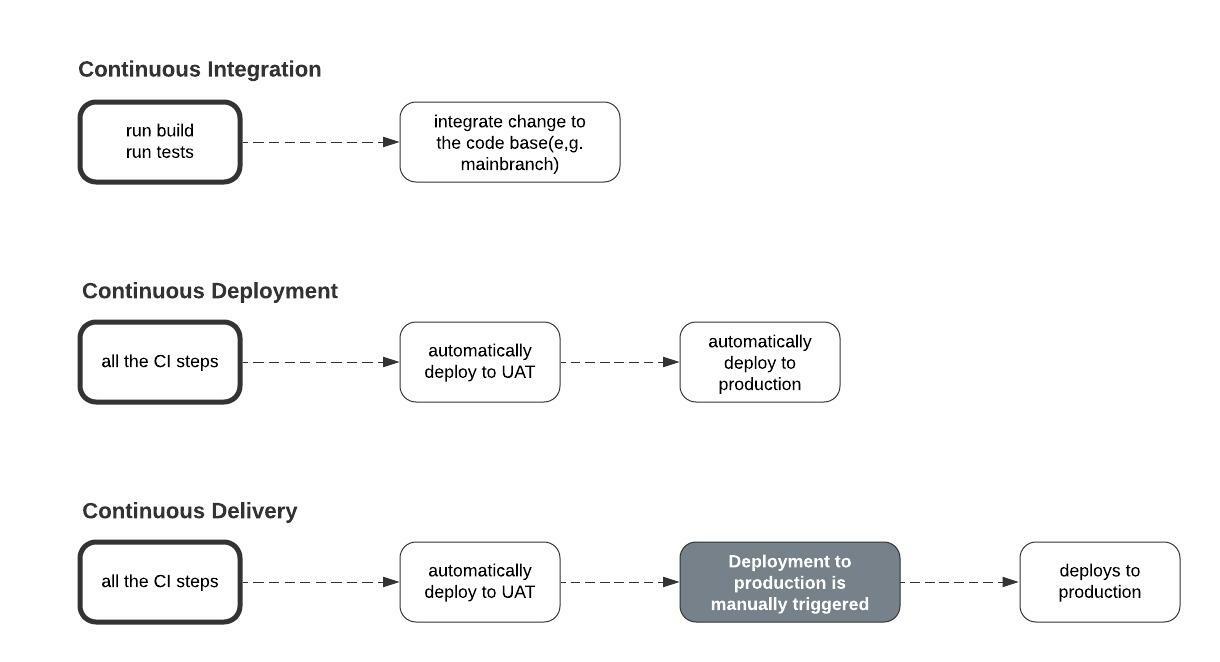
持续集成VS持续部署VS持续交付。源于此。作者
注意: 如果从UAT环境到生产环境的部署是手动启动的,那么它就是一个持续集成/持续交付的设置。否则,它就是持续集成/持续部署的设置。
然而,我们不禁要问,那个能使CI/CD管道的不同阶段自动化的实体是什么?
我们可以使用各种工具来自动化CI/CD管道中的构建、测试和部署步骤--例如,CI Circle、Travis CI、Jenkins、GitHub Actions等等。在这篇文章中,我们将重点介绍GitHub Actions。
什么是GitHub动作?
为了让GitHub Actions这个词更容易理解,我将会把它过度简化。
在 CI/CD 管线中,GitHub Actions 是将无聊的事情自动化的实体。可以把它想象成与你创建的每个GitHub仓库捆绑在一起的一些插件。
这个插件存在于你的仓库中,执行你告诉它的任何任务。通常,你会通过YAML配置文件指定该插件应该执行哪些任务。无论你在配置文件中添加什么命令,都会转化为类似这样的普通英语。
"嘿,GitHub 行动,每次在 X 分支上打开 PR 时,自动构建和测试新的修改。每次有新的改动被并入或推送到X分支,就把该改动部署到Y服务器上。"
GitHub Actions 的核心是五个概念:工作、工作流、事件、行动和运行者。
工作 是你通过 YAML 配置文件命令 GitHub Actions 执行的任务。工作可以是告诉GitHub动作来构建你的源代码,运行测试,或将已构建的代码部署到某个远程服务器。
工作流本质上是包含一个或多个逻辑上相关的工作的自动化流程。例如,你可以把构建和运行测试工作放在同一个工作流中,而把部署工作放在另一个工作流中。
还记得我们提到过,你通过配置文件告诉 GitHub Actions 要执行什么工作吗?GitHub Actions 认为你放在 repo 中某个文件夹里的每个配置文件都是一个工作流。 我们将在下一部分中进一步讨论这个文件夹。
因此,如果要为部署工作创建一个单独的工作流,然后再创建一个结合构建和测试工作的不同工作流,你就必须在你的 repo 中添加两个配置文件。但是,如果你要把所有这三项工作合并到一个工作流中,那么你只需要添加一个配置文件。
事件 ,从字面上看,就是触发GitHub Actions执行工作的事件。还记得我们提到过通过配置文件传递要执行的工作吗?在该配置文件中,你还需要指定一个作业应该在什么时候执行。
比如说,是在PR上执行到main?是在推送到main上吗?是在合并到main上吗?只有当某些事件发生时,GitHub Action 才会执行一个作业。
好吧,让我迅速纠正自己。并非一定要在某个事件发生后才可以执行作业。你也可以安排工作。
例如,在你的配置文件中,你可以安排它在每天凌晨2点发生,而不是指定触发构建和测试工作的事件,比如说。事实上,你可以既安排一个工作,又为同一个工作指定一个事件。
Actions 是可重复使用的命令,你可以在你的配置文件中重复使用。你可以编写你的自定义动作或使用现有的动作。
运行器 是 GitHub Actions 用来执行你告诉它的作业的远程计算机。
例如,当构建和测试工作基于某些事件被触发时,GitHub Actions 会将你的代码拉到该计算机上并执行该工作。
同样的事情也发生在部署工作的情况下。运行器会触发将构建的代码部署到你指定的某个远程服务器。在我们的案例中,我们将使用一个名为AWS的服务。
什么是AWS?
AWS是亚马逊网络服务的缩写。它是一个由亚马逊拥有的平台,这个平台允许你访问广泛的云计算服务。
云计算--你不是说没有大词吗?大多数时候,企业甚至个人开发者建立应用程序只是为了让其他人能够使用它们。出于这个原因,这些应用程序必须在网际网络上可用。
让一些目标用户可以使用一个应用程序,理想情况下,需要将该应用程序上传到一台特殊的计算机上,该计算机全天候运行,速度超快。
想象一下,如果是这样,在你将你的应用程序提供给其他互联网用户之前,你必须拥有并设置这样一台电脑。这是很可行的,但也有很多障碍。
例如,如果你只是想测试一下应用程序呢?你会经历所有的压力,仅仅为了测试而建立一个硬件基础设施?此外,如果你想上传1000个不同的应用程序或你的应用程序开始处理10亿个并发请求怎么办?事情就开始变得复杂了。
像AWS这样的云计算平台的存在就是为了拯救你所有的压力。这些平台已经有许多这样的特殊计算机设置并保存在称为数据中心的建筑物中。
他们允许你通过互联网将你的应用程序上传到他们预先配置的计算机上,而不是从头开始设置你自己的硬件基础设施。作为回报,你向他们支付一定的费用。
事实上,其中一些平台有免费计划,允许你测试小型应用程序。除了上传你的应用程序的代码外,其中一些平台还允许你托管你的数据库和存储你的媒体文件,以及其他功能。
在其最简单的形式中,云计算主要是在别人的计算机上存储或执行(有时两者都有)某些东西,通常,通过网络。
因此,当我说AWS提供了广泛的云计算服务时,我只是说它为企业和个人提供了一些特殊的计算机,他们可以把他们的代码、数据库和媒体文件作为一种服务上传。
好了,现在我们完全理解了我们标题的不同部分,现在我们将以目标的形式重述它。然后,这些目标将决定本文剩下的两部分将包含什么。
目标1: 如何通过GitHub Actions在推送或PR上自动构建和运行单元测试到主分支。
目标2: 如何通过GitHub Actions在推送或PR上自动部署到AWS上的主分支。
第二部分:持续集成 - 如何自动运行构建和测试
在本节中,我们将看到如何配置GitHub Actions,以便在推送或拉动请求时自动运行构建和测试到 repo 的主分支。
前提条件
- 一个本地设置的Django项目,至少有一个定义了返回某种响应的视图。
- 为你定义的视图编写一个测试案例。
我已经创建了一个演示的Django项目,你可以从这个资源库中获取:
git clone [https://github.com/Nyior/django-github-actions-aws](https://github.com/Nyior/django-github-actions-aws)
在你下载代码后,创建一个virtualenv并通过pip安装需求。
pip install -r requirements.txt
注意: 该项目已经有了所有的文件,我们将在进行中逐步添加。也许你仍然可以下载并尝试在我们进行时对文件的内容进行理解。这个项目当然不有趣。它只是为演示目的而创建的。
现在你已经在本地设置了一个 Django 项目,让我们来配置 GitHub Actions。
如何配置GitHub Actions
好了,我们已经建立了我们的项目。我们还为我们定义的视图编写了一个测试案例,但最重要的是,我们已经将我们闪亮的变化推送到了GitHub。
我们的目标是,每次在main/master上推送或打开拉动请求时,GitHub都会触发构建并运行我们的测试。我们刚刚推送了我们的改动到main,但GitHub Actions并没有触发构建或运行我们的测试。
为什么没有? 因为我们还没有定义一个工作流。请记住,工作流是我们指定希望GitHub Actions执行的工作的地方。
事实上,Nyior,你是怎么知道没有触发构建,进而没有定义工作流的?每个GitHub repo都有一个Action 标签。如果你导航到那个标签,你就会知道一个 repo 上是否定义了工作流。
怎么知道? 请看下面的图片:
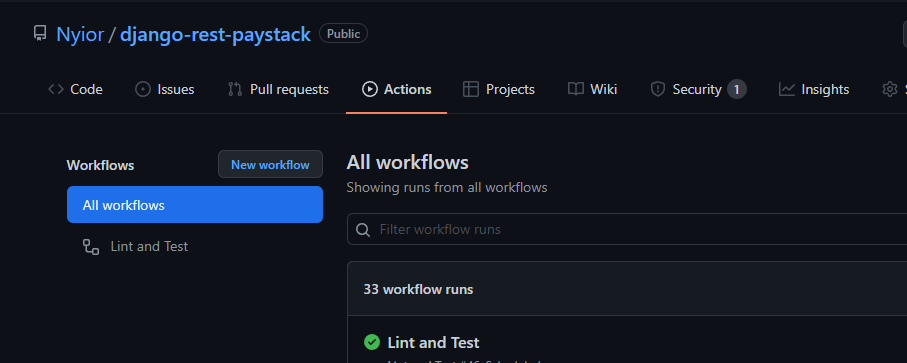
一个定义了工作流的GitHub repo
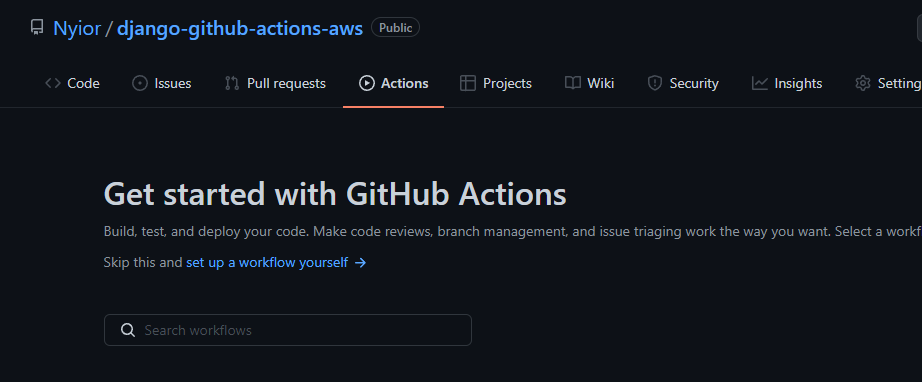
一个没有定义工作流的GitHub Repo
第一张图片中的第一个 repo 定义了一个名为 "Lint and Test "的工作流。第二张图片中的第二个 repo 没有工作流--这就是为什么你没有像第一个 repo 那样看到一个标题为 "所有工作流 "的列表。
哦,好吧,现在我明白了。那么,我如何在我的 repo 上定义一个工作流呢?
- 在你的项目根目录下创建一个名为
.github的文件夹。 - 在
.github目录中创建一个名为workflows的文件夹。这是你将创建所有YAML文件的地方。 - 让我们创建我们的第一个工作流,它将包含我们的构建和测试工作。我们通过创建一个扩展名为
.yml的文件来实现这一目标。让我们给这个文件命名build_and_test.yml - 在你刚刚创建的
yaml文件中添加以下内容:
name: Build and Test
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python Environment
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Tests
run: |
python manage.py test
让我们对上述文件中的每一行都有所了解:
name: Build and Test这是我们工作流程的名称。当你导航到行动选项卡时,你定义的每个工作流程将由你在该列表中给它的名字来识别。on:这是你指定触发我们工作流程执行的事件的地方。在我们的配置文件中,我们向它传递了两个事件。我们指定主分支为目标分支。jobs:请记住,工作流只是一个工作的集合。test:这是我们在这个工作流中定义的工作的名称。你可以给它起任何名字,真的。注意到这是唯一的工作,而构建工作并不在那里?嗯,这是Python代码,所以不需要构建步骤。这就是为什么我们没有定义构建工作。runs-onGitHub提供了Ubuntu Linux、Microsoft Windows和macOS运行器来运行你的工作流程。在这里你可以指定你想使用的运行器类型。在我们的案例中,我们使用的是Ubuntu Linux运行器。- 一个作业是由一系列
steps,通常在同一个运行器上按顺序执行。在我们上面的文件中,每个步骤都用连字符标记。name代表步骤的名称。每个步骤可以是一个正在执行的shell脚本,也可以是一个action。如果一个步骤正在执行一个action,你就用uses来定义这个步骤,如果正在执行一个shell脚本,你就用run来定义这个步骤。
现在你已经通过在指定文件夹中添加配置文件定义了一个workflow ,你可以提交并推送你的变化到你的远程 repo。
如果你浏览你的远程版本库的Actions 标签,你应该看到一个工作流程,其中列出了构建和测试(我们给它起的名字)。
第三部分:持续交付--如何将我们的代码自动部署到AWS上
在本节中,我们将看到如何让GitHub Actions在推送或拉动请求到主分支时自动将我们的代码部署到AWS。AWS 提供了广泛的服务。在本教程中,我们将使用一个名为Elastic Beanstalk的计算服务。
计算服务?弹性Beanstalk?来吧nn :(
不用担心,放松,你会明白的。记得我们提到过,云计算就是通过互联网在别人的电脑上存储和执行某些东西,对吗--某些东西?
是的。例如,我们可以存储和执行源代码,或者我们可以只存储媒体文件。亚马逊知道这一点,因此,他们的云基础设施包含了大量的服务类别。每一个服务类别都允许我们在特定的事情中做某一件事。
例如,有一个服务类别,允许上传和执行为我们的应用程序提供动力的源代码(计算服务)。有一个服务类别,允许我们持久化我们的媒体文件(存储服务)。然后是允许我们管理数据库的服务类别(数据库服务)。
每个服务类别都是由一个或多个服务组成的。一个类别中的每个服务只是为我们提供了一种解决它所属类别的问题的不同方式。
例如,计算类别中的每个服务都为我们提供了在云上部署和执行我们的应用程序代码的不同方法--一个问题,不同的方法。弹性豆茎 是计算类别中的一个服务。其他的是,但不限于,EC2和Lambda。
亚马逊S3 是存储类别中的服务之一。而亚马逊RDS是数据库类别中的一项服务。
希望你现在明白我说的 "我们将使用一个名为Elastic Beanstalk的计算服务 "是什么意思。 在所有的计算服务中,为什么是Elastic Beanstalk? 嗯,因为它是最容易操作的服务之一。
既然如此,我们来配置一下吧 <3
为了简洁起见,我们将采用持续交付的设置。此外,我们将只有一个部署环境,作为我们的UAT环境。
为了帮助你了解全局,总的来说,我们的部署设置是这样的:在向主服务器推送或拉取请求时,GitHub Actions 会测试并上传我们的源代码到 Amazon S3。然后,代码会从Amazon S3拉到我们的Elastic Beanstalk环境。想象一下这样的流程。
GitHub -> Amazon S3 -> Elastic Beanstalk
你可能会问,为什么我们不直接推送到Elastic Beanstalk?
在我们目前的设置中,唯一可以直接将代码上传到Elastic Beanstalk实例的方法,就是使用AWS Elastic Beanstalk CLI(EB CLI)。
使用EB CLI需要运行一些shell命令,然后需要我们回应一些输入。
现在,如果我们从本地机器部署到Elastic Beanstalk,当我们运行EB CLI命令时,我们就会在那里输入所需的响应。但在我们目前的设置中,这些命令将在GitHub Runners上执行。我们不会在那里提供所需的响应。对于我们的用例,EB CLI并不是最简单的部署工具。
通过我们选择的方法,我们会运行一个shell命令,将我们的代码上传到S3,然后再运行另一个命令,将上传的代码拉到我们的Elastic Beanstalk实例。这些命令在运行时,并不要求我们提交一些响应。拥有亚马逊s3步骤是最简单的方法。
为了实现我们的方法,让我们的代码部署到Elastic Beanstalk,请按照以下步骤进行。
第1步:设置一个AWS账户
创建一个IAM。为了简单起见,在添加权限时,只需为用户添加 "管理员权限"(不过这有一些安全隐患)。要完成这个任务,请按照本指南第1和第2模块的步骤进行。
最后,确保抓住并保留你的AWS秘密和访问密钥。我们将在随后的章节中需要它们。
现在我们已经正确设置了AWS账户,现在是时候设置我们的Elastic Beanstalk环境了。
第2步:设置你的Elastic Beanstalk环境
登录AWS账户后,采取以下步骤来设置Elastic Beanstalk环境。
首先,在搜索栏中搜索 "elastic beanstalk",如下图所示。然后点击Elastic Beanstalk服务。
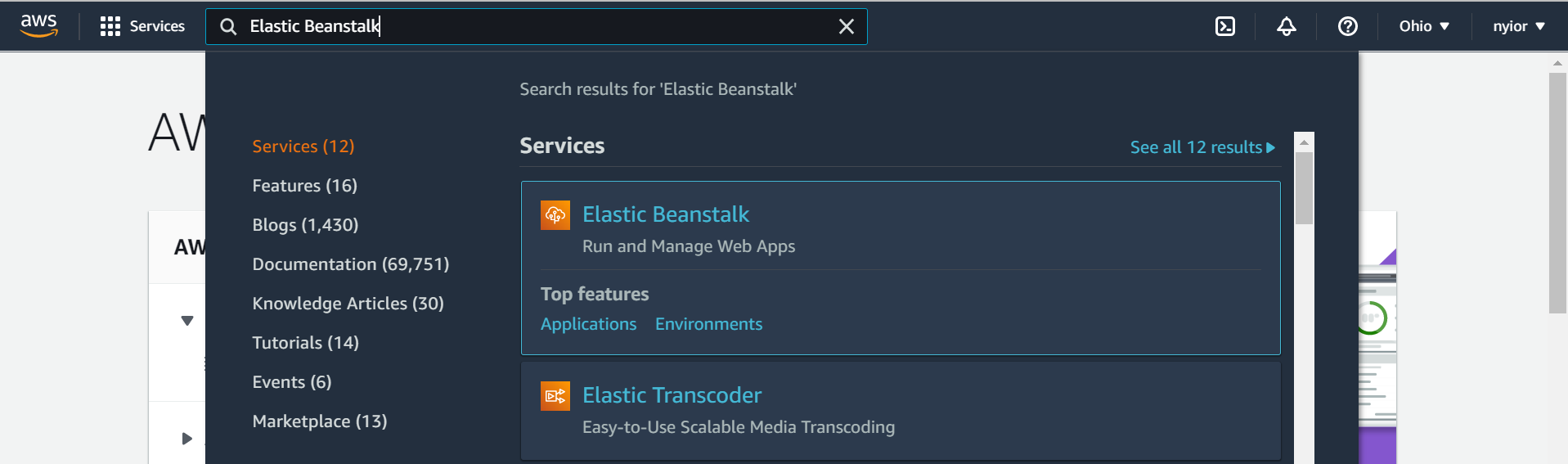
搜索elastic beanstalk。
一旦你在上一步中点击了Elastic Beanstalk服务,你就会被带到下图所示的页面。在该页面上,点击 "创建一个新环境 "的提示。确保在下一步选择 "Web服务器环境"。
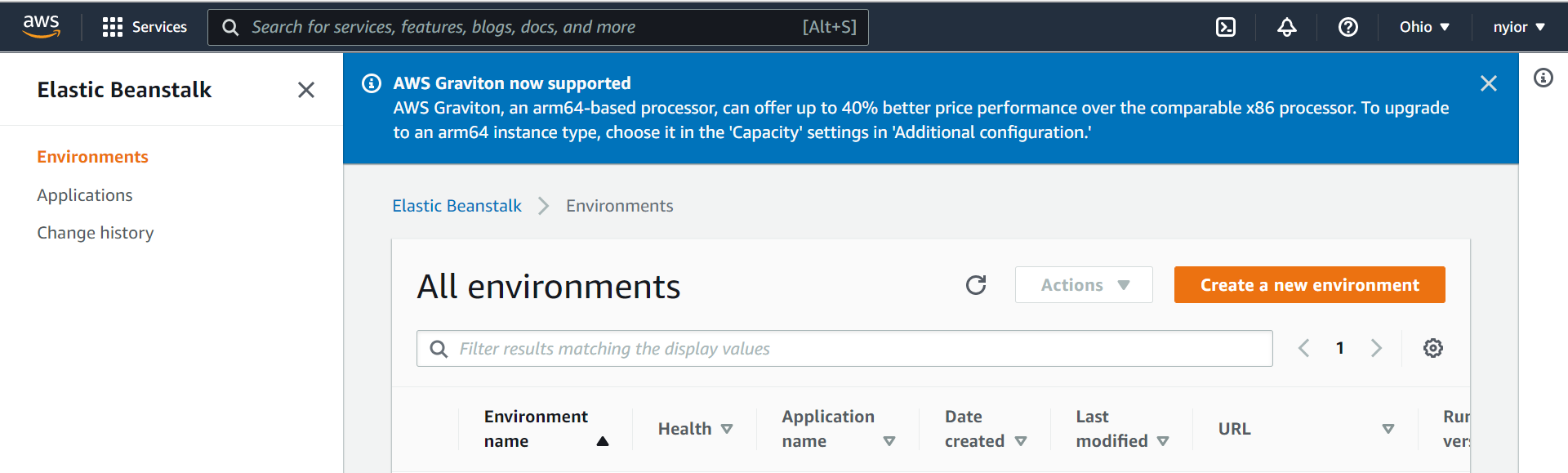
创建一个环境
在上一页选择 "Web服务器环境 "后,你将被带到下面图片所示的页面。
在该页面上,提交一个应用程序名称、一个环境名称,同时选择一个平台。在本教程中,我们将使用Python平台。
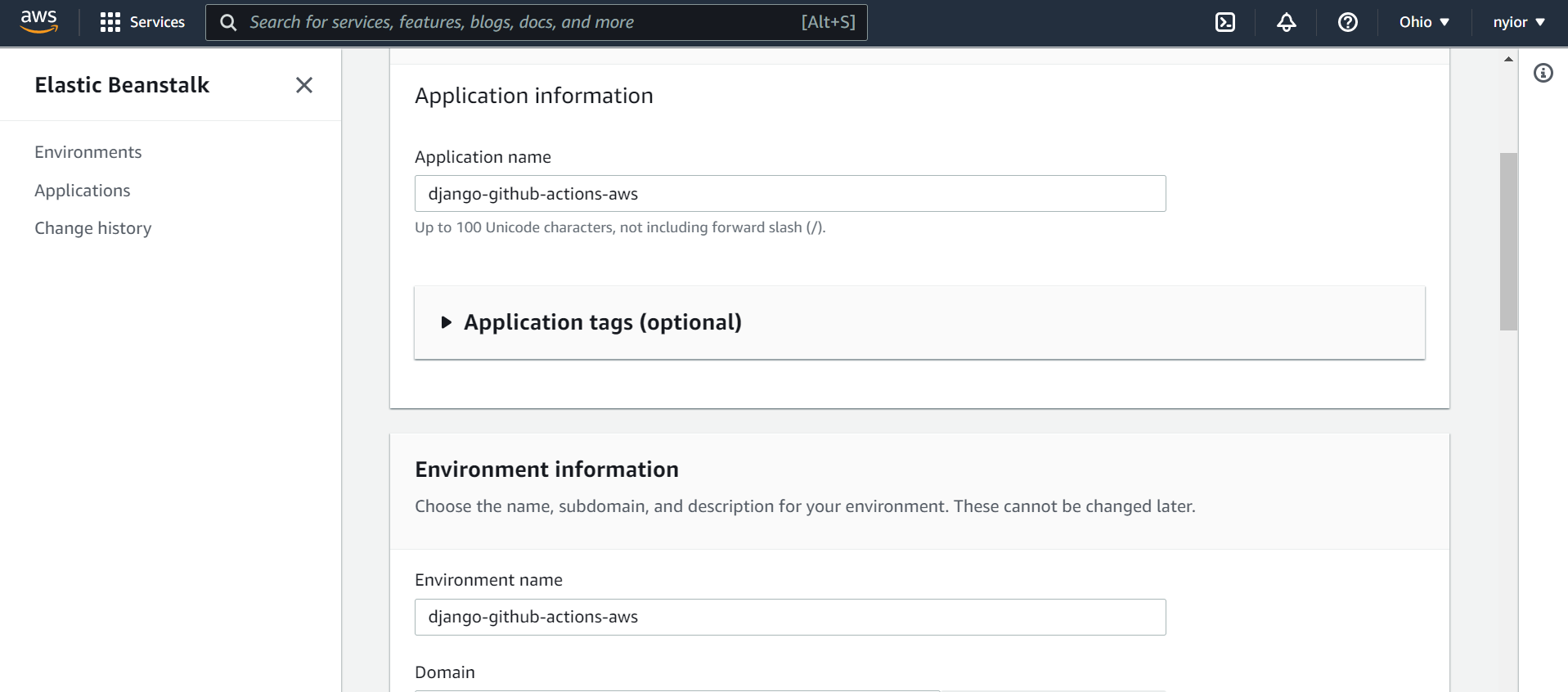
一个应用程序和一个环境名称
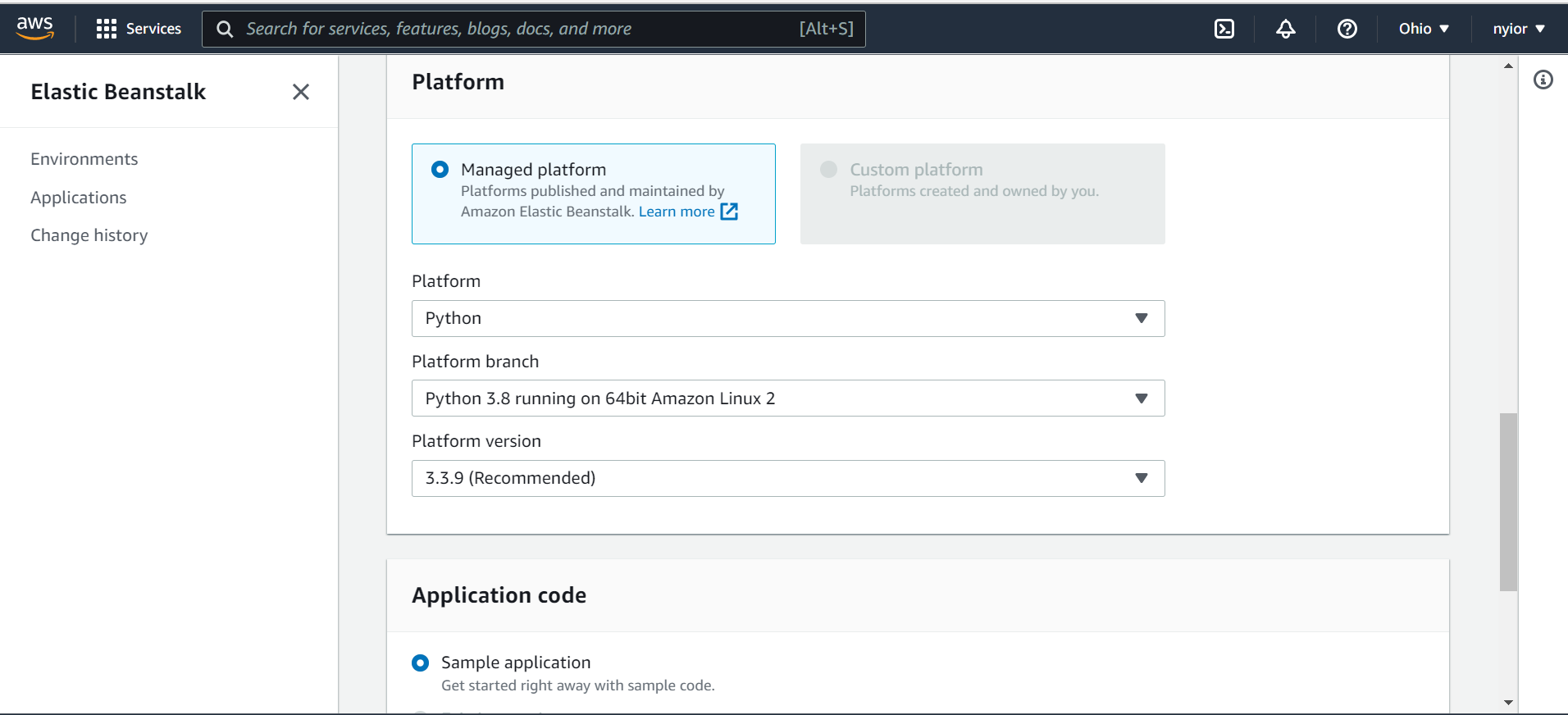
选择一个平台
一旦你提交了上一步填写的表格,过了一会儿,你的应用程序和它相关的环境就会被创建。你应该看到你提交的名字显示在左边的栏里。
抓住应用程序的名称和环境名称。我们将在随后的步骤中需要它们。
现在我们的Elastic Beanstalk环境已经完全设置好了,现在是时候配置GitHub Actions,以便在推送或拉动请求到main时触发自动部署到AWS。
第3步:为Elastic Beanstalk配置你的项目
默认情况下,Elastic Beanstalk会在我们的项目中寻找一个名为application.py 的文件。它使用这个文件来运行我们的应用程序,但我们的项目中没有这个文件。我们有吗?我们需要告诉Elastic Beanstalk使用我们项目中的wsgi.py 文件来代替运行我们的应用程序。要做到这一点,采取以下步骤。
在你的项目目录下创建一个名为.ebextensions 的文件夹。在该文件夹中创建一个配置文件。你可以把它命名为任何你想要的东西。我把我的命名为eb.config 。把下面的内容添加到你的配置文件中:
option_settings:
aws:elasticbeanstalk:container:python:
WSGIPath: django_github_actions_aws.wsgi:application
用你的项目名称替换django_github_actions_aws。
完成上述步骤后,你的项目目录现在应该类似于下面的图片:
演示项目结构
在这一部分,你需要做的最后一件事是进入你的settings.py 文件,将ALLOWED_HOSTS 的设置更新为all 。
ALLOWED_HOSTS = ['*']
注意,使用通配符有很大的安全隐患。我们在这里只是为演示目的而使用它。
现在我们已经完成了为Elastic Beanstalk配置项目的工作,现在是时候更新我们的工作流文件了。
第四步:更新你的工作流文件
完成这一步,我们需要五个重要的信息:应用程序名称、环境名称、访问密钥ID、秘密访问密钥和服务器区域(登录后,你可以从导航栏的最右边抓取区域)。
由于访问密钥ID和秘密访问密钥是敏感数据,我们将把它们隐藏在资源库的某个地方,在我们的工作流文件中访问它们。
要做到这一点,请到你的版本库的设置标签,然后点击秘密,如下图所示。在那里,你可以将你的秘密创建为键值对:
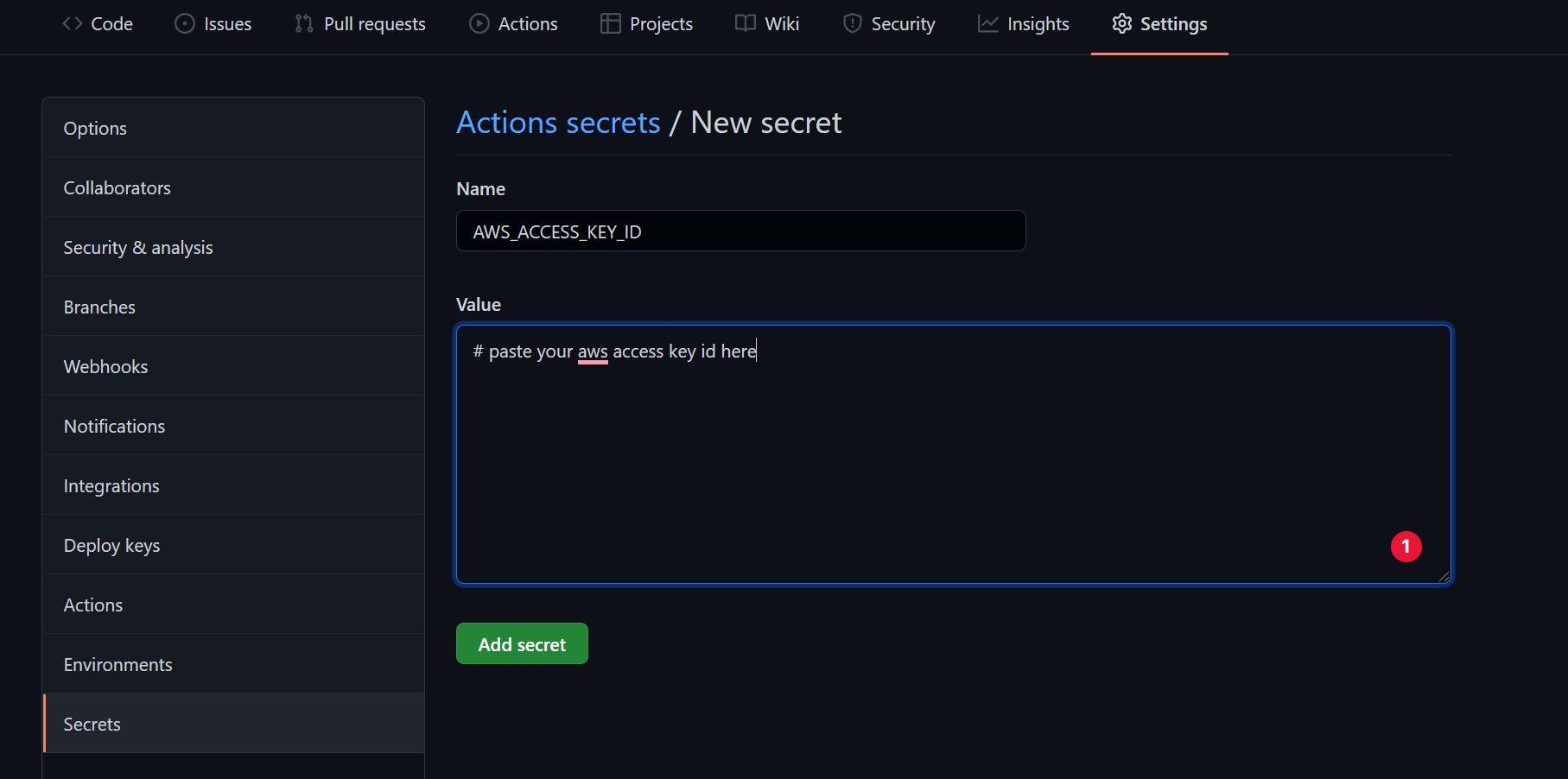
在你的 repo 中嵌入秘密数据
接下来,将部署工作添加到现有工作流程文件的末尾:
deploy:
needs: [test]
runs-on: ubuntu-latest
steps:
- name: Checkout source code
uses: actions/checkout@v2
- name: Generate deployment package
run: zip -r deploy.zip . -x '*.git*'
- name: Deploy to EB
uses: einaregilsson/beanstalk-deploy@v20
with:
// Remember the secrets we embedded? this is how we access them
aws_access_key: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws_secret_key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
// Replace the values here with your names you submitted in one of
// The previous sections
application_name: django-github-actions-aws
environment_name: django-github-actions-aws
// The version number could be anything. You can find a dynamic way
// Of doing this.
version_label: 12348
region: "us-east-2"
deployment_package: deploy.zip
部署工作
needs 简单地告诉GitHub Actions,只有在 工作完成且状态合格后才开始执行 工作。test deployment
Deploy to EB 这个步骤使用了一个现有的行动,einaregilsson/beanstalk-deploy@v20 。还记得我们说过actions 是一些可重复使用的应用程序,为我们处理一些经常重复的任务吗?einaregilsson/beanstalk-deploy@v20 就是这些行动之一。
为了加强上述内容,记得我们的部署应该经过以下步骤。GitHub -> Amazon S3 -> Elastic Beanstalk.
然而,在本教程中,我们没有做任何亚马逊s3的设置。此外,在我们的工作流程文件中,我们没有上传到s3桶,也没有从s3桶拉到我们的Elastic Beanstalk环境。
通常情况下,我们应该做这一切,但我们在这里没有做--因为在引擎盖下,einaregilsson/beanstalk-deploy@v20 行动为我们做了所有繁重的工作。你也可以创建你自己的action ,处理一些重复的任务,并通过GitHub市场提供给其他开发者。
现在你已经在本地更新了你的工作流文件,然后你可以提交并推送这一变化到你的远程。你的作业将运行,你的代码将被部署到你创建的Elastic Beanstalk实例。就这样了。我们完成了>>
收尾工作
哇!这真是个长篇大论。这是一个非常长的故事,不是吗?总的来说,我解释了GitHub Actions、CI/CD Pipeline和AWS这些术语的含义。此外,我们还看到了如何配置GitHub Actions来自动将我们的代码部署到AWS上的Elastic Beanstalk实例。
如果你喜欢这项工作,并想了解我今后要发表的文章,让我们在Twitter、Linkedin或GitHub上联系。我使用这些渠道来分享我所做的工作,在我发布这些文章后,立即分享。
