

支持向量机(SVM)是有监督的 机器学习 算法之一,可用于回归或分类建模。它是一种机器学习算法,比各种算法更受欢迎,因为它有助于产生更高和更好的准确性。SVM的操作原理是内核技巧,它最适合二进制分类任务,因为SVM在超平面附近有最小的类可以操作,而且它的收敛速度也更快。因此,在这篇文章中,让我们看看如何利用各种特征选择技术,用SVM从数据中提取最佳特征集。
目录
- SVM简介
- 使用SVM的前向特征选择
- 使用SVM的后向特征选择
- 使用SVM的递归特征选择
- 为递归技术选择的特征建立模型
- 摘要
SVM简介
支持向量机(SVM)是一种有监督的机器学习算法,可用于分类或回归。在各种监督学习算法中,SVM是一种非常稳健的算法,与其他算法相比,它有助于产生更高的模型精度。
SVM的基本原理是内核技巧,该算法将负责寻找最佳的超平面,以便在数据集中的所有特征上运行,靠近超平面的特征将被归入各自的类别。SVM算法最适用于分类问题。
现在让我们看看如何实现SVM分类器,并使用SVM在数据集中存在的各种特征中选择最佳特征。
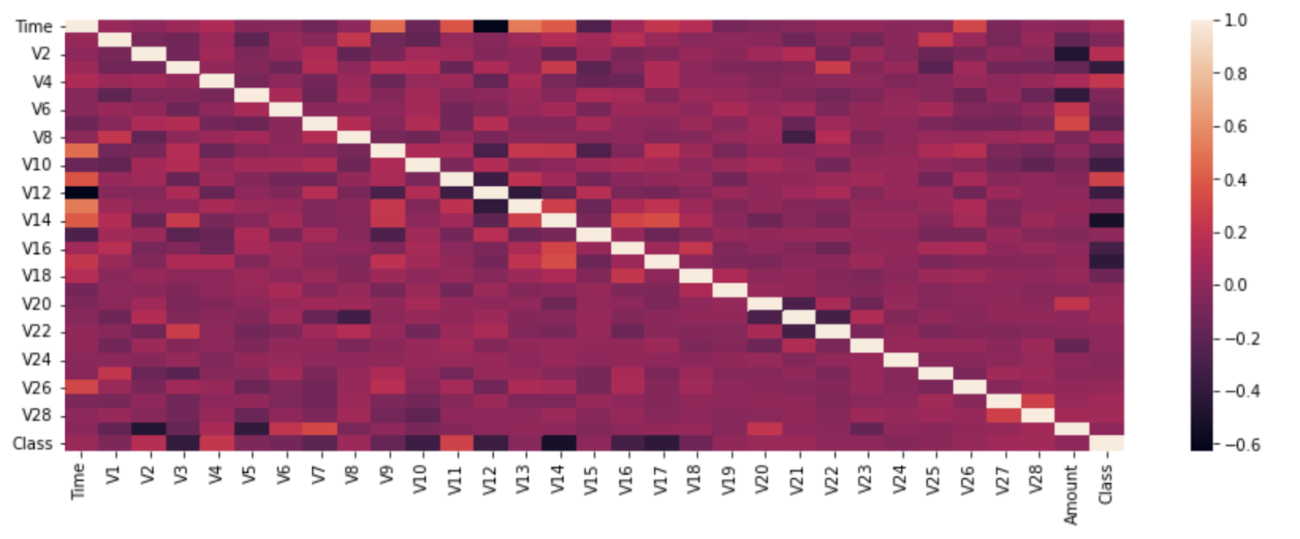
在继续进行特征选择技术之前,让我们通过热图看看我们正在处理的数据集中存在的相关性:
plt.figure(figsize=(15,5))
sns.heatmap(df.corr())
plt.show()
在实施SVM之前处理数据
对于SVM模型的建立,数据应该在一个共同的尺度上进行标准化处理。所以在这里,首先,数据被分成训练和测试,并使用Scikit Learn预处理包的StandardScaler模块对数据进行了标准化:
from sklearn.model_selection import train_test_split
X=df.drop('Class',axis=1)
y=df['Class']
X_train,X_test,Y_train,Y_test=train_test_split(X,y,test_size=0.2,random_state=42)
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
X_trains=ss.fit_transform(X_train)
X_tests=ss.fit_transform(X_test)
所以现在我们已经对数据集的依赖特征进行了标准化,让我们继续建立模型。
建立一个SVM模型
这里的主要目的是使用SVM从数据集中选择重要的特征,所以让我们看看如何导入SVM分类所需的库,并将SVM分类器模型应用于分割的数据。
from sklearn.svm import SVC
svc=SVC()
svc.fit(X_trains,Y_train)

使用SVM进行前向特征选择
前向特征选择技术的工作方式是,首先从数据集中选择一个单一的特征,然后将所有的特征添加到特征选择实例中,之后这个实例对象可以用来评估模型参数。mlxtend模块被用于特征选择,其中创建了一个用于正向特征选择的实例,随后该实例对象被用于拟合分裂的数据,随后R-squared值被用于评估正向特征选择技术选择的特征。
!pip install mlxtend
import joblib
import sys
sys.modules['sklearn.externals.joblib'] = joblib
from mlxtend.feature_selection import SequentialFeatureSelector as sfs
forward_fs_best=sfs(estimator = svc, k_features = 'best', forward = True,verbose = 1, scoring = 'r2')
sfs_forward_best=forward_fs_best.fit(X_trains,Y_train)

因此,在这里我们可以看到,特征选择技术已经遍历了数据集中存在的所有30个特征,随后该实例可以被用来评估被选择的特征所解释的变化。
print('R-Squared value:', sfs_forward.k_score_)
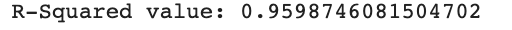
这里我们可以看到,前向特征选择技术负责解释了数据中96%的变化。以同样的方式,让我们看看如何实现后向特征选择技术。
使用SVM的后向特征选择
后向特征选择技术首先考虑数据集的所有特征,然后在每个实例中放弃数据集的一个特征,并对该实例中存在的特征进行评估,以实现最佳特征选择。现在让我们看看如何实现后向特征选择技术。
backward_fs_best=sfs(estimator = svc, k_features = 'best', forward = False,verbose =1, scoring = 'r2')
sfs_backward_best=backward_fs_best.fit(X_trains,Y_train)

print('R-Squared value:', sfs_backward_best.k_score_)

所以在这里我们可以看到,后向特征选择技术可以解释数据中88.62%的变化。这可能是由于在第一例中选择了较高的特征。所以为了更好的选择,让我们看看递归特征选择技术的能力。
使用SVM的递归特征选择
递归特征选择技术是后向选择技术的翻版,但它使用了特征排序的原理来选择最佳特征,因此可以看出这种特征选择技术比前向特征选择技术表现得更好。让我们看看如何实现这种特征选择技术:
X_trains_df=pd.DataFrame(X_trains,columns=X_train.columns)
from sklearn.feature_selection import RFE
svc_lin=SVC(kernel='linear')
svm_rfe_model=RFE(estimator=svc_lin)
svm_rfe_model_fit=svm_rfe_model.fit(X_trains_df,Y_train)
feat_index = pd.Series(data = svm_rfe_model_fit.ranking_, index = X_train.columns)
signi_feat_rfe = feat_index[feat_index==1].index
print('Significant features from RFE',signi_feat_rfe)

现在让我们比较一下数据集中的原始特征数量和被递归特征选择技术选择为最佳特征的数量:
print('Original number of features present in the dataset : {}'.format(df.shape[1]))
print()
print('Number of features selected by the Recursive feature selection technique is : {}'.format(len(signi_feat_rfe)))

所以在这里我们可以清楚地看到,与整个数据集相比,数据集中几乎只有50%的特征是有用的。所以现在让我们利用这些通过递归特征选择技术选出的特征建立一个模型。
通过递归技术选择的特征建立模型
使用递归特征技术选择的特征,让我们创建一个训练数据的子集,并创建一个新的SVM模型实例,在所选择的特征子集上进行拟合,让我们观察递归技术选择的最佳特征集的R平方值。
X_trains_new=X_train[['V1', 'V2', 'V4', 'V6', 'V9', 'V10', 'V12', 'V14', 'V17', 'V18', 'V19',
'V20', 'V25', 'V26', 'V28']]
rfe_svm=SVC(kernel='linear')
rfe_fit=rfe_svm.fit(X_trains_new, Y_train)
print('R2 squared value for RFE',rfe_fit.k_score_)

总结
这就是如何通过采用各种特征选择技术,使用SVM选择最佳特征集,并减少在高维数据下工作的担忧。这种技术减少了数据集的维度,其中最佳特征集可以作为各自模型构建的子集,并产生可靠的模型参数和性能,因为模型的运行是由特征选择技术选择的最佳特征集。
