

分布式机器学习很复杂,当与同样复杂的深度学习模型结合在一起时,它可以使任何东西都能工作成为一个研究项目。再加上设置你的GPU硬件和软件,它可能会变得难以承受。
在这里,我们展示了Hugging Face的Accelerate库消除了使用分布式设置的一些负担,同时仍然允许你保留所有的PyTorch原始代码。
当与Paperspace的多GPU硬件和他们准备好的ML运行时相结合时,加速库使用户更容易运行先进的深度学习模型,这在以前可能很难做到。新的可能性被打开了,否则可能会被忽略。
什么是加速器?
Accelerate是Hugging Face的一个库,它简化了在单台或多台机器上将单个GPU的PyTorch代码转化为多个GPU的代码。你可以在他们的GitHub仓库中阅读更多关于加速器的信息。
动机
在最先进的深度学习的前沿,我们可能并不总是能够避免真实数据或模型的复杂性,但我们可以减少在GPU上运行它们的难度,而且是同时在多个GPU上运行。
有几个库可以做到这一点,但往往它们要么提供更高层次的抽象,使用户失去细粒度的控制,要么提供另一个API接口,需要先学习才能使用。
这就是启发加速器的动机:让那些需要编写完全通用的PyTorch代码的用户能够这样做,同时减少以分布式方式运行这种代码的负担。
该库提供的另一个关键能力是,一个固定形式的代码既可以分布式运行,也可以不运行。这与传统的PyTorch分布式启动不同,它必须要改变从一个到另一个,然后再返回。
更改代码以使用加速器
如果你需要使用完全通用的PyTorch代码,那么你很可能在为模型编写自己的训练循环。
训练循环
一个典型的PyTorch训练循环是这样的。
- 导入库
- 设置设备(例如,GPU)
- 将模型指向设备
- 选择优化器(例如,Adam)。
- 使用DataLoader加载数据集(因此我们可以将批次传递给模型)
- 在循环中训练模型(每个周期一次)。
- 将源数据和目标点到设备上
- 将网络梯度归零
- 计算模型的输出
- 计算损失(如交叉熵)。
- 对梯度进行反向传播
可能还有其他步骤,如数据准备,或在测试数据上运行模型,这取决于要解决的问题。
代码修改
在加速器GitHub仓库的自述中,与普通的PyTorch相比,上述训练循环的代码变化是通过突出显示需要修改的行来说明的。

使用Accelerate与原始PyTorch的训练循环的代码变化(来自Accelerate GitHub仓库的README)
绿色表示添加的新行,红色表示删除的行。我们可以看到这些代码是如何与上面概述的训练循环步骤相对应的,以及需要的变化。
乍一看,这些变化似乎并没有将代码简化多少,但如果你想象一下红线消失了,你可以看到我们不再谈论我们在什么设备上(CPU、GPU等)。它已经被抽象掉了,同时保留了循环的其余部分。
更详细地说,代码的变化是。
- 导入加速器库
- 使用加速器作为设备,它可以是CPU或GPU
- 实例化模型,不需要指定设备
- 设置模型、优化器和数据,供加速器使用
- 我们不需要将源数据和目标指向设备
- 加速器做反向传播的步骤
多GPU
上面的代码是针对单个GPU的。
在他们的Hugging Face博客条目中,Accelerate的作者随后展示了需要如何改变PyTorch的代码,以使用传统方法实现多GPU。
它包括许多行代码。
import os
...
from torch.utils.data import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
local_rank = int(os.environ.get("LOCAL_RANK", -1))
...
device = device = torch.device("cuda", local_rank)
...
model = DistributedDataParallel(model)
...
sampler = DistributedSampler(dataset)
...
data = torch.utils.data.DataLoader(dataset, sampler=sampler)
...
sampler.set_epoch(epoch)
...
这样产生的代码就不再适用于单GPU。
相比之下,使用加速器的代码已经适用于多GPU,并继续适用于单GPU。
因此,这听起来很好,但它如何在一个完整的程序中工作,以及如何调用它?我们现在将通过Paperspace上的一个例子来展示加速器的作用。
今天就为您的机器学习工作流程增加速度和简单性吧
在Paperspace上运行加速器
加速器的GitHub仓库显示了如何通过一组记录良好的例子来运行该库。
在这里,我们展示了如何在Paperspace上运行它,并通过一些例子进行讲解。我们假设你已经登录,并且熟悉基本的笔记本使用方法。你还需要有一个付费的订阅,这样你就可以访问终端。
Paperspace允许你直接连接到GitHub仓库,并把它作为一个项目的起点。因此,你可以指向现有的加速器仓库并立即使用它。不需要安装PyTorch,也不需要先设置一个虚拟环境。
要运行,请按常规方式启动笔记本。在推荐标签下使用PyTorch运行时间,然后滚动到页面底部并切换到高级选项。然后,在高级选项下*,*将工作区的URL改为加速器资源库的位置:https://github.com/huggingface/accelerate。首先,我们使用的是单GPU,所以机器的默认选择(P4000)就足够了。我们将在本文的后面进行多GPU的操作。
这将启动笔记本,在左侧导航栏的文件标签中出现 repo 文件。
在Paperspace笔记本中使用的Hugging Face Accelerate Github资源库
因为与 Repo 一起提供的例子是.py Python 脚本,而且这些脚本在 Paperspace 的这个界面上运行良好,所以我们不打算在这里以.ipynb 笔记本的形式展示它们。虽然,如果你愿意,这个库也可以从笔记本上启动。
让我们来看看这个例子。
简单的NLP例子
Hugging Face是建立在让人们更容易获得自然语言处理(NLP)上的,所以NLP是一个合适的开始。
从左边的导航栏打开一个终端。
在Paperspace Notebook中打开终端
然后有一些简短的设置步骤
pip install accelerate
pip install datasets transformers
pip install scipy sklearn
然后我们就可以进入实例了
cd examples
python ./nlp_example.py
这个例子对著名的BERT转化器模型的基本配置进行了微调训练,使用GLUE MRPC数据集,了解一个句子是否是另一个句子的转述。
它输出了大约85%的准确率和略低于90%的F1分数(精确度和召回率的组合)。因此,性能是不错的。
如果你导航到指标标签,你可以看到确实使用了GPU。
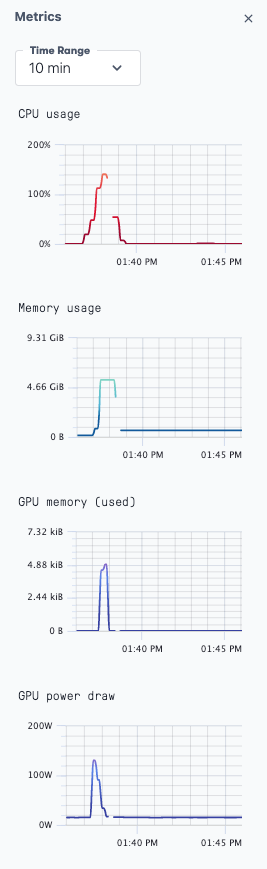
在Paperspace Notebook中运行我们的加速实例时GPU的使用情况
该脚本还可以用各种参数来改变行为。我们将在最后提到其中的一些。
多GPU
对于多GPU来说,加速库的简化能力真正开始显现,因为可以运行与上面相同的代码。
同样,在Paperspace上,要获得多GPU设置,只需将机器从我们一直使用的单GPU切换到多GPU实例。Paperspace为A4000s、A5000s、A6000s和A100s提供多GPU实例,尽管这在不同地区有所不同。
如果你已经在运行你的笔记本,你停止你当前的机器。
然后使用左侧导航栏中的下拉菜单。

来选择一个多GPU的机器,然后重新启动。
从P4000改成A4000x2在这里会很有效。
*注意:*如果你还没有运行一个单GPU的机器,按照上面单GPU情况的同样方法创建一个笔记本,但是选择一个A4000x2机器而不是P4000机器。
然后,要调用多GPU的脚本,请执行。
pip install accelerate datasets transformers scipy sklearn
并运行其简单的配置步骤,告诉它如何在这里运行。
accelerate config
In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 0
Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU): 2
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1
Do you want to use DeepSpeed? [yes/NO]: no
Do you want to use FullyShardedDataParallel? [yes/NO]: no
How many GPU(s) should be used for distributed training? [1]: 2
Do you wish to use FP16 or BF16 (mixed precision)? [NO/fp16/bf16]: no
注意,我们说的是1台机器,因为我们的2个GPU是在同一台机器上,但我们确认要使用2个GPU。
然后我们可以像以前一样运行,现在使用launch ,而不是python ,告诉加速器使用我们刚刚设置的配置。
accelerate launch ./nlp_example.py
你可以通过在终端运行nvidia-smi ,看到两个GPU都被使用了。
更多的功能
正如上面的配置文件设置所暗示的那样,我们只是触及了该库功能的表面。
它的一些其他功能包括
- 启动脚本的一系列参数:见github.com/huggingface…
- 除了多GPU之外,还有多CPU
- 多个机器上的多GPU
- 从
.ipynbJupyter笔记本启动程序 - 混合精度的浮点
- DeepSpeed集成
- 使用MPI的多CPU
计算机视觉例子
还有一个机器学习的例子,你可以运行;它类似于我们在这里运行的NLP任务,但用于计算机视觉。它在牛津-IIT宠物数据集上训练一个ResNet50网络。
在我们的笔记本上,你可以在代码单元中添加以下内容来快速运行这个例子。
pip install accelerate datasets transformers scipy sklearn
pip install timm torchvision
cd examples
wget https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
tar -xzf images.tar.gz
python ./cv_example.py --data_dir images
结论和下一步措施
我们已经展示了与传统的PyTorch相比,来自Hugging Face的Accelerate库如何简化了以分布式方式运行PyTorch深度学习模型的过程,而没有消除用户代码的完全通用性质。
同样,Paperspace通过提供一个环境,让它们随时可以使用,简化了访问多GPU + PyTorch + Accelerate的过程。
对于一些下一步的工作。
- 查看抱团取暖的原始博客文章
- 查看加速器的GitHub仓库,了解更多的例子和功能
- 在Paperspace上运行你自己的加速和分布式深度学习模型
许可
Hugging Face GitHub 仓库中的代码由他们根据 Apache 许可 2.0 提供。
今天就为您的机器学习工作流程增加速度和简单性
