


最好的ML平台通常是该平台的IDE、硬件和成本的一个函数。考虑到这些因素,我们将对Kaggle Notebooks和Paperspace的Gradient Notebooks进行比较。
在本指南中,我们的目标是展示每个平台的优势所在,并为何时使用这两种产品提出明确的论据。
Paperspace 梯度笔记本
Gradient是一个MLOps平台,旨在帮助用户扩展现实世界的机器学习应用。Gradient Notebooks具有一个由Jupyter支持的笔记本工作空间,用户可以在其中执行代码单元。笔记本对于处理和运行直接上传到工作目录的数据、上传到团队数据集卷并挂载在笔记本中的数据、或从所提供的公共数据集的挂载卷中获取的数据都很有用。
Kaggle笔记本
Kaggle是一个很受欢迎的平台,用户可以在这里寻找和发布数据集,在数据科学环境中创建和测试模型,通过社交媒体功能与其他用户合作和交流,并参加比赛来解决数据科学挑战。用户可以在基于网络的平台上运行的IPython笔记本上进行操作,并使用Kaggle笔记本执行代码和markdown单元来处理用户上传到平台的数据。如果有任何命令需要在笔记本之外运行,Kaggle笔记本还具有一个控制台窗口。
它们在整体上有什么相似之处?
梯度笔记本和Kaggle笔记本共享一些功能。熟悉Jupyter笔记本的用户在这两个环境中都会很舒服。
Kaggle和Gradient Notebook IDEs
首先,两个IDE都允许用户执行代码和markdown单元。Markdown单元格可以很容易地在笔记本中提供上下文的散文、标签、描述性语句和评论,而代码单元格可以在笔记本中执行代码。这种类似于Jupyter的行为使得这两个平台都成为探索数据或以描述性和可重复的方式进行新模型实验的理想选择。
0:00
/
1×
交互式会话允许你随意地启动和停止内核。
这两个平台的特点是可以访问在Docker容器中运行的交互式会话,并预先安装了软件包。这种容器化的会话运行允许用户用所需的包来启动会话。然而,这两个IDE在使用中的容器的定制范围有很大不同。我们将在下面更详细地介绍。
每个平台都利用了挂载版本数据源的能力,并在平台内访问它们。这使用户能够通过挂载的卷来处理上传到笔记本主机平台的文件。再一次,这里的能力范围差别很大,但两个平台都能在导入的数据上执行代码。
最后,每个平台都能让用户访问可定制的计算资源,如GPU--但Kaggle和Gradient处理GPU硬件分配和可用性的方式不同,Gradient提供更多选择和更高端的硬件。我们将在下文中详细介绍这些和其他差异。
Kaggle笔记本和Gradient笔记本的对比
硬件方面
| Kaggle | 梯度 | |
|---|---|---|
| GPU | 是的,P100 | 是,M4000,P4000,RTX4000,A4000,P5000,RTX5000,A5000,A6000,V100 - 16GB,V100 - 32GB,A100 - 40GB,A100 - 80GB |
| TPU | 有 | 没有 |
| CPU | 是 | 有 |
机器种类和能力
Kaggle笔记本可以在CPU、GPU或TPU驱动的实例中运行,而Gradient只有CPU或GPU机器的选项。如果你重视TPU,Kaggle是一个更好的选择。但是,如果你重视在CPU和GPU硬件方面有更多的选择,Gradient则是更好的选择。
Kaggle只提供P100 GPU,这是一个Pascal系列的GPU,现在已经是两代了。与Gradient提供的V100和A100实例相比,P100的功效就显得苍白无力了,尽管这些GPU除了通过Gradient的订阅外是无法获得的。
TPU是谷歌开发的一种人工智能ASIC,用于加速深度学习应用的张量计算。这主要是为了与深度学习库TensorFlow一起使用,软件和硬件的开发是为了优化彼此的使用。
0:00
/
1×
Gradient的GPU选择来自笔记本创建页面
Gradient可用的GPU的完整列表和它们的基准可以在这些链接中找到。
今天就为你的机器学习工作流程增加速度和简单性吧
机器选择
对Kaggle不利的最大因素之一是机器选择。我们都知道,在给定的时间范围内完成深度学习任务的能力取决于硬件和操作者。
在Kaggle中,没有选择不同机器类型的选项。对于平台上的大多数业余爱好者、学生和发烧友来说,这不是一个问题。P100对于许多深度学习任务来说是足够的。然而,P100没有能力处理许多较大的数据问题,这些问题随着深度学习领域的发展而变得越来越普遍。企业级用户很快就会发现P100是不够的,而Kaggle上对GPU笔记本的30小时限制只会让这种影响更加严重。
Gradient则没有这个问题。在所有Paperspace Core和Gradient实例中,用户都可以以不同的成本使用各种Maxwell、Pascal、Volta、Turing和Ampere GPU。这使得用户能够对使用多少数据以及深度学习算法在Gradient上处理这些数据的速度有更多的控制。
Gradient上的多GPU机器
此外,Gradient还有多GPU实例,可以启用Kaggle用户无法使用的整个库和并行化范式,如Arise或DeepMind。
界面
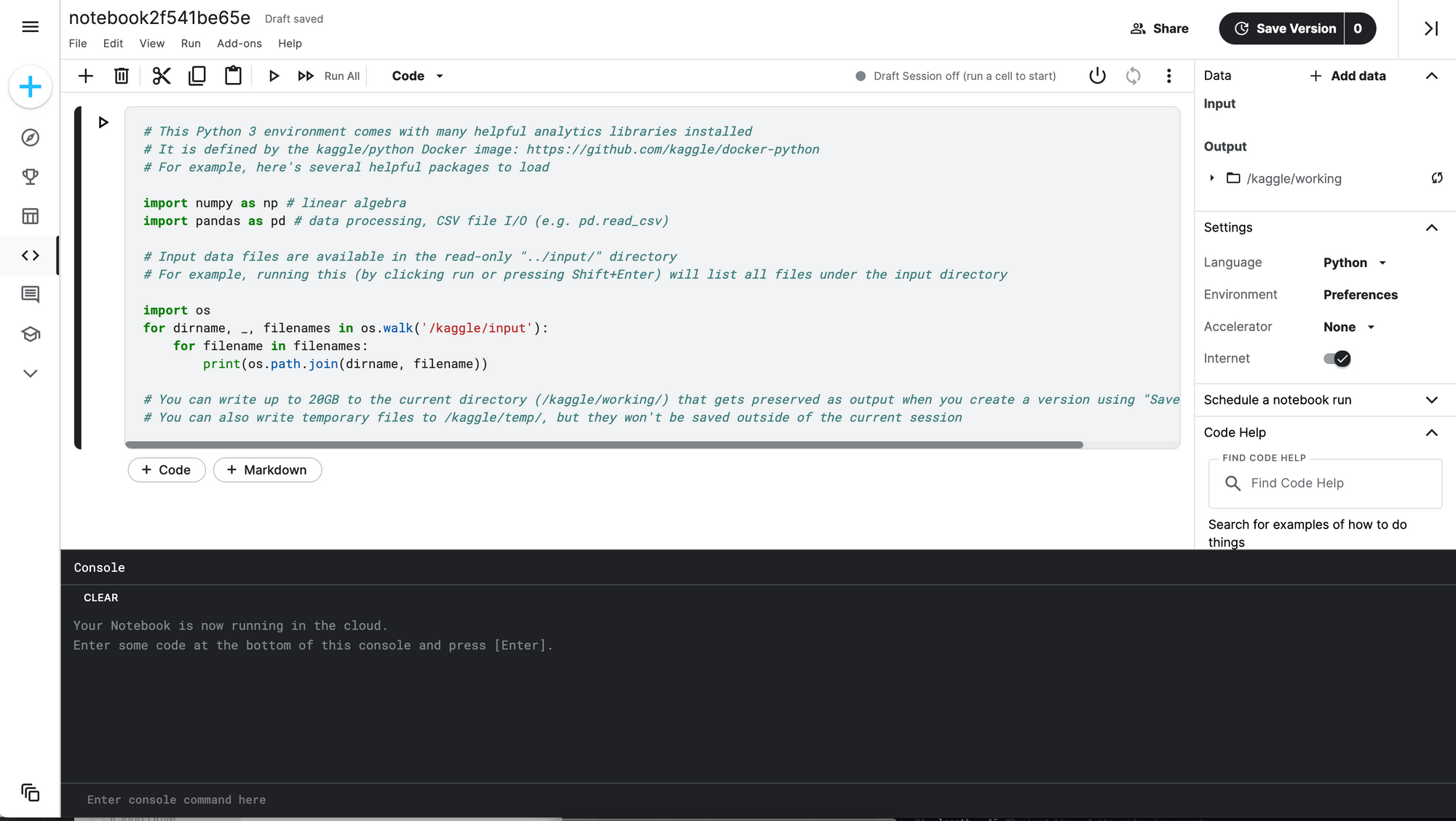
由于与Jupyter的共同遗产,Gradient Notebooks IDE和Kaggle Notebook的界面相似性大于差异性,但也有明显的区别。
这两个平台都是编译Python或R代码的优秀环境,有完整的编辑器和控制台,并且可以通过.ipynb文件和.py脚本运行代码。虽然它们都是强大的编码环境,但它们的主要区别实际上与用户的体验质量有关。这些差异即在于附加功能方面:指标、日志和定制。
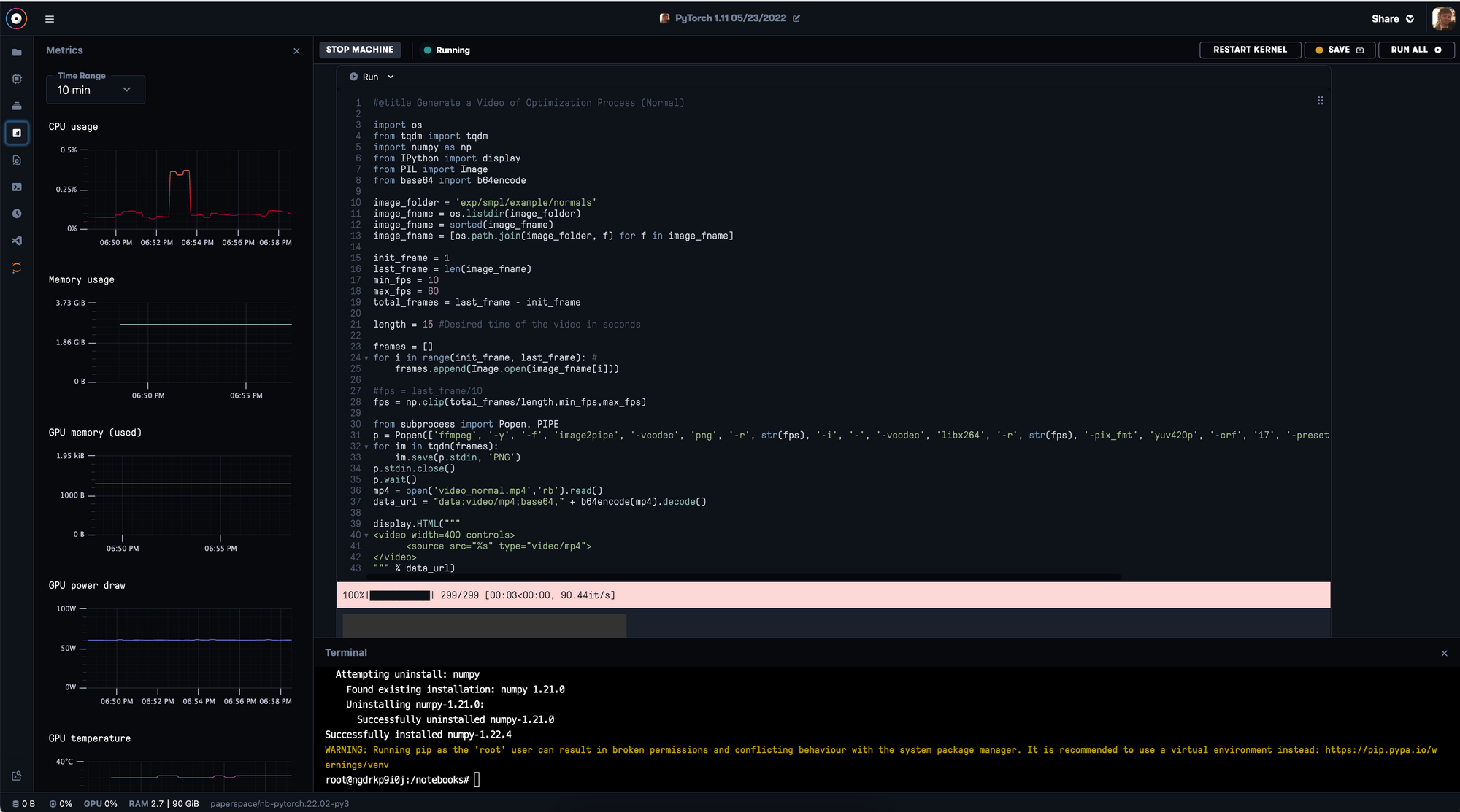
使用指标选项卡可以轻松监测你的GPU功耗或总内存使用情况
在Kaggle中,要浮现关于你的代码中发生了什么的信息可能很困难。这对于记录和获取关于你的实例的各种指标来说是一个双重问题。你需要设置你自己专有的日志应用程序来记录笔记本上正在进行的操作或查找错误代码,而且通常需要第三方应用程序来辨别机器本身的指标,如内存消耗或温度。幸运的是,有了Gradient,这些事情就变得简单了。只需使用任何笔记本左手边的按钮,就可以访问日志、指标、版本历史和更多内容。
其他功能
在这一节中,我们将看看区别于这两个平台的一些其他功能。
Github集成
虽然Kaggle有一个API和一个流行的Github动作来推送数据集内核,但它目前缺乏与Github的进一步整合。这是合理的;Kaggle笔记本主要是为在玩具数据集上进行快速实验而设计的,而不是在Github repo上进行迭代的工作空间。
然而,Gradient的特点是与Github强大的整合,以便让用户能够管理他们的笔记本工作空间,并通过工作流程更新仓库。通过整合Github Gradient账户和Github Gradient应用程序,Gradient可以在使用Gradient工作流程完成工作的同时迭代更新软件库。这实际上是让用户在应用开发过程中对代码进行版本控制,并确保任何同事和合作者都能获得最佳体验。在较低的集成层次上,Gradient还具有使用Github URL作为创建笔记本的工作空间URL的能力。通过这样做,用户可以定制他们的笔记本中可用的起始文件。
S3数据集
访问不同的存储位置和类型对ML操作平台的用户来说可能是很重要的情况。在Kaggle上,这完全是在Kaggle生态系统内处理的,这一点无法改变。但在Gradient上,用户可以选择将数据存储在Gradient Managed上或连接到S3桶。通过几个步骤的配置,任何Gradient用户都可以将S3桶直接连接到他们的账户。这将使用户能够设置自己的数据存储限制,并克服用户可能产生的超过Gradient Managed存储限制的任何限制或超额费用。对于任何希望处理大数据的用户来说,这可能是一个必要条件。
运行时间限制
Kaggle笔记本只能用于执行代码,CPU和GPU笔记本会话的执行时间为12小时,TPU笔记本会话为9小时。此外,每个用户每周允许的GPU总时间为30小时,TPU总时间为20小时的限制。这个限制是无法克服的,所有的用户都必须遵守它。
另一方面,在梯度笔记本中,唯一有设定时间限制的笔记本是免费的GPU笔记本。这些笔记本在免费层上最多只能运行6小时。然而,用户可以为Gradient笔记本的GPU使用权付费,这些笔记本的运行时间从多个小时到几天不等,也没有设定时间限制。这使得Gradient在你有计算成本高或时间长的训练任务需要完成时更受欢迎。
公共和团队数据集
Kaggle最大的特点是它提供了对用户提交和策划的大量数据集的访问。在Kaggle笔记本中,用户可以很容易地访问这些数据集的不可变版本,以用于他们的代码,而且这些数据集可以通过Kaggle API进行更新。由于这个原因,Kaggle目录也是新的数据科学家访问的一个非常常见的地方,以开始玩具项目的工作。
Gradient还允许用户访问一些公共数据集,其中包含一个不断增长的流行机器和深度学习数据集库。目前,这些数据集比Kaggle数据集要有限得多,但它们允许用户近乎即时地将数据装入笔记本,并包括流行的大型数据集,如MS-COCO。用户还可以通过团队数据集上传和使用自己的数据。
总而言之,虽然Kaggle目前是平台内快速获取数据的卓越选择,但Gradient正通过其数据集功能迅速接近用户的可行性水平。Kaggle数据集的优势也因其API而受到严重阻碍,因为在Paperspace数据中心的网速下,任何用户都可以在很短的时间内轻松下载任何Kaggle数据集。
总结
在这篇博文中,我们试图细分Kaggle和Gradient之间的差异。我们试图说明Kaggle是学生和业余爱好者的理想起点,这要归功于其简单的IDE、数据共享工具和缺乏专业术语的定制选项。同时,我们也展示了Gradient提供了许多相同的功能,并增加了企业级的可扩展性、比Jupyter更高的生活质量,以及部署能力。
基于这些原因,我们建议只有最早的职业用户和需要使用TPU的用户才可以使用Kaggle笔记本。Gradient应该是企业级用户的首选,而且作为任何寻求进行深度学习的用户的首选,也有很强的说服力。
今天就为你的机器学习工作流程增加速度和简单性吧
