

深度学习的最大承诺之一是生成媒体的出现。这主要是因为生成媒体是目前这些框架所提供的最容易赚钱的解决方案之一。生成的媒体,无论其格式是视频、音频、文本还是其他,都有可能被转化为用于大量不同目的的内容。通过利用这种创造性的力量,我们可以将相关任务的创造性过程的很大一部分自动化,而且技术已经达到了这样的程度,即这些内容有时甚至可以与真正的人类演员制作的内容无法区分。这对于NLP和计算机视觉相关的任务尤其如此。
其中一个尚未因此而发生变革的领域是动画。深度学习并不是没有触及动画,因为一些有进取心的工程师已经想出了新的方法来输入指令,使现有的3D人物变成动画,反之,其他人也创造了为静态3D模型生成新的纹理的方法。 但尽管如此,使用简单的文本提示来生成一个完全动画的3D人物的想法,直到现在还是一个未来的承诺。
承担这项任务的令人兴奋的新项目是AvatarCLIP。由洪芳洲、张明远、潘亮、蔡忠刚、杨磊和刘紫薇撰写的原始论文展示了他们创新的新方法,即生成一个粗略的SMPL(Skined Multi-Person Linear)模型人物,根据文本提示对其进行纹理和雕刻,然后仅使用文本提示将其制作成动画,进行一些运动。它通过与OpenAI的CLIP(一个更聪明的架构)的巧妙整合来做到这一点。
在这个关于AvatarCLIP的第一部分,我们将检查他们的方法,以生成最初的SMPL人物模型,并使用CLIP进行纹理。然后,我们将展示如何在梯度笔记本中使用这种技术,从他们的一个示例配置中生成一个静态模型。来自One Punch Man的Saitama。在第二部分,我们将看看如何为这个人物制作动画,以完成整个AvatarCLIP管道。
阿凡达CLIP

AvatarCLIP在一系列明确定义的步骤中工作,这些步骤共同构成了一个为小说创作提供动画的管道。正如我们在上面的样本图片中所看到的,这基本上分为三个步骤,首先创建初始人物,然后进行纹理和雕刻,以匹配提示中的描述符元素,最后,Marching Cube算法将应用输入的运动提示,将人物制成动画。我们将在本文中研究整个管道,但值得注意的是,为人物制作动画的代码正在积极开发中。因此,代码的动画部分将在发布后进行介绍。请在Twitter上关注我们的第二部分:@Paperspace。
它是如何工作的
在上面的视频中,来自项目作者,他们展示了他们专有的文本驱动的头像生成和动画的界面。按照我们上面描述的步骤,他们展示了可以建模和制作动画的各种不同的角色。让我们来分析一下这里发生了什么。
首先,AvatarCLIP生成一个粗略形状的网格,作为基线人物使用。网格是一个顶点、边缘和面的集合,描述一个三维物体的形状。CLIP模型接受形状文本提示,以确定什么基线形状应被用于该图。这个基线图是我们的起点,但它是灰色和无特征的开始。纹理和雕刻是在下一阶段根据外观和形状文本提示应用的。同时,CLIP模型解释运动文本提示,以寻找人物将遵循的运动的描述性元素。然后,它生成一系列适当的参考姿势,让模型在这些运动提示的基础上进行。然后,AvatarCLIP整合了这两个管道的功能,通过参考姿势的时间线移动现在的纹理人物,形成一个连贯的人物动画。
架构
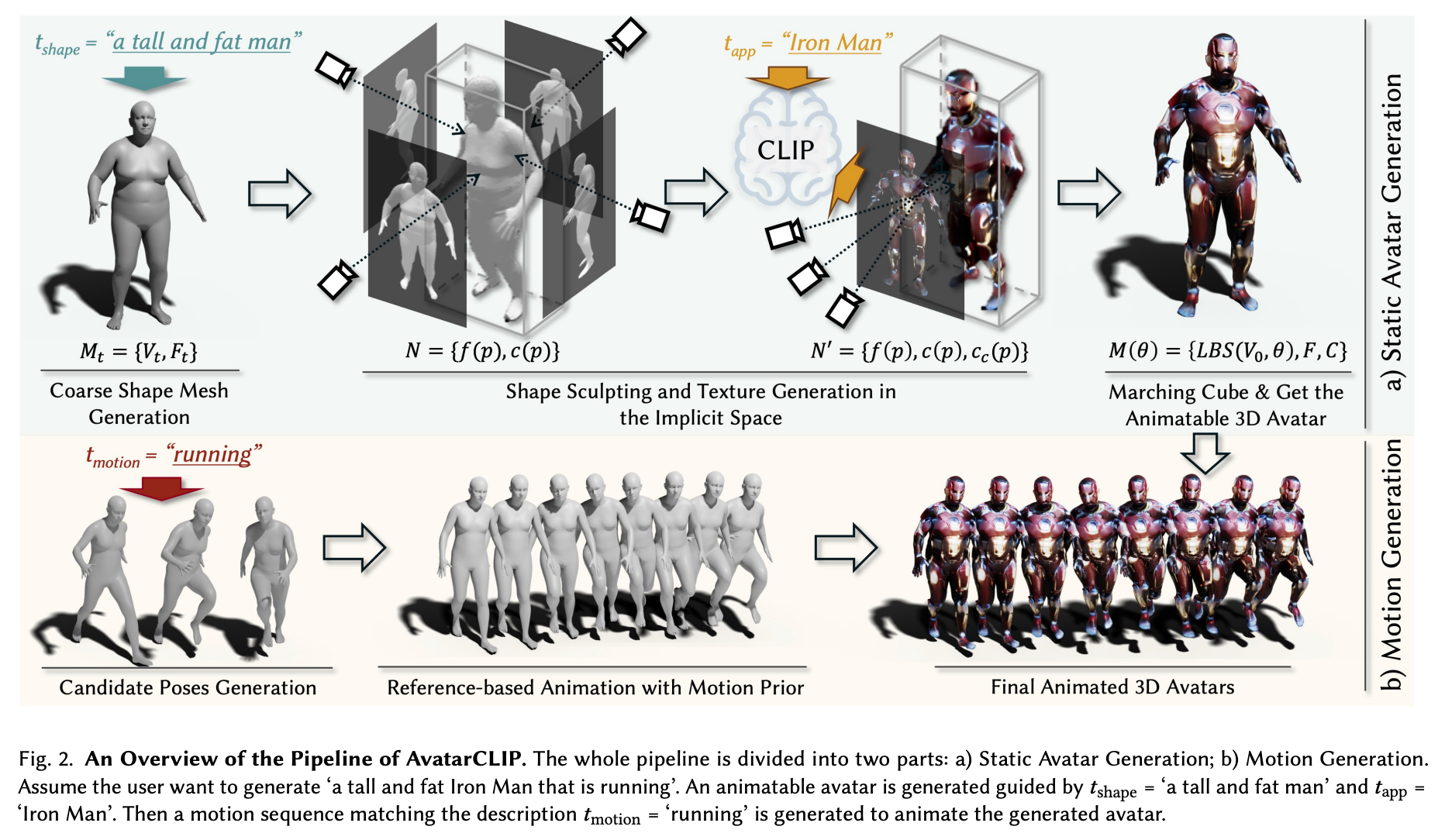
原始论文中的管道概述 -来源
现在我们明白了AvatarCLIP是怎么回事了,让我们来看看这个管道的内部结构,以便更好地了解综合模型管道是如何实现的。我们需要了解的第一件事是,这分为两个基本阶段:头像生成和运动生成。让我们稍微仔细看看每个阶段,看看每个阶段的生成是如何实现的。(在代码演示部分,我们将在本系列的第一部分介绍前者。第二部分将介绍运动生成)。
AvatarCLIP的总体目标是创建一个 "零拍摄文本驱动的3D头像生成和动画"。 换句话说,他们需要这个模型在其训练范式范围之外的提示下工作,这个模型要有足够的灵活性来处理未知术语。幸运的是,这其中的文本部分被CLIP很好地覆盖了。
为了做到这一点,他们从文本形式的自然语言输入开始,其中文本={tshape,tapp,tmotion}。这些是三个独立的文本提示,对应于我们想用于最终动画的所需的身体形状、外观和运动的描述。
粗略的头像生成
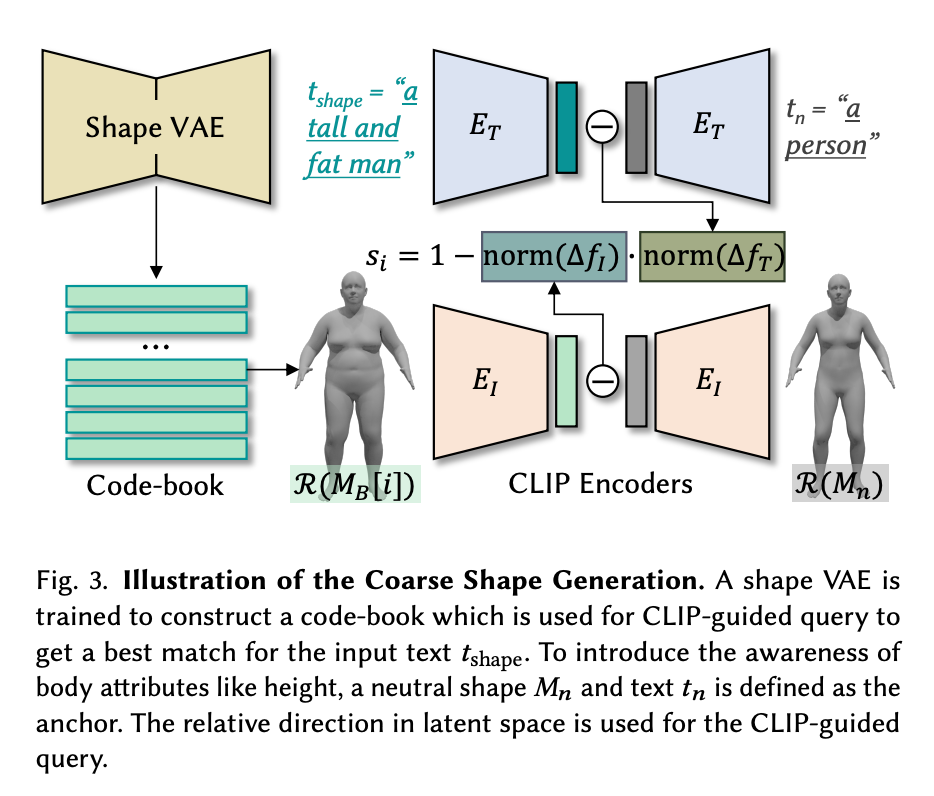
前两个提示tshape和tapp分别用于在动画前对SMPL模型进行贴图和雕刻。为了做到这一点,代码首先通过一个形状的VAE生成一个粗略的SMPL图,这个VAE被训练来构建一个用于CLIP引导的查询的代码簿,以获得与输入文本tshape的最佳匹配。现在我们有了粗略的、没有纹理的人物网格Mt,作为我们的基线。
精细的纹理和雕琢
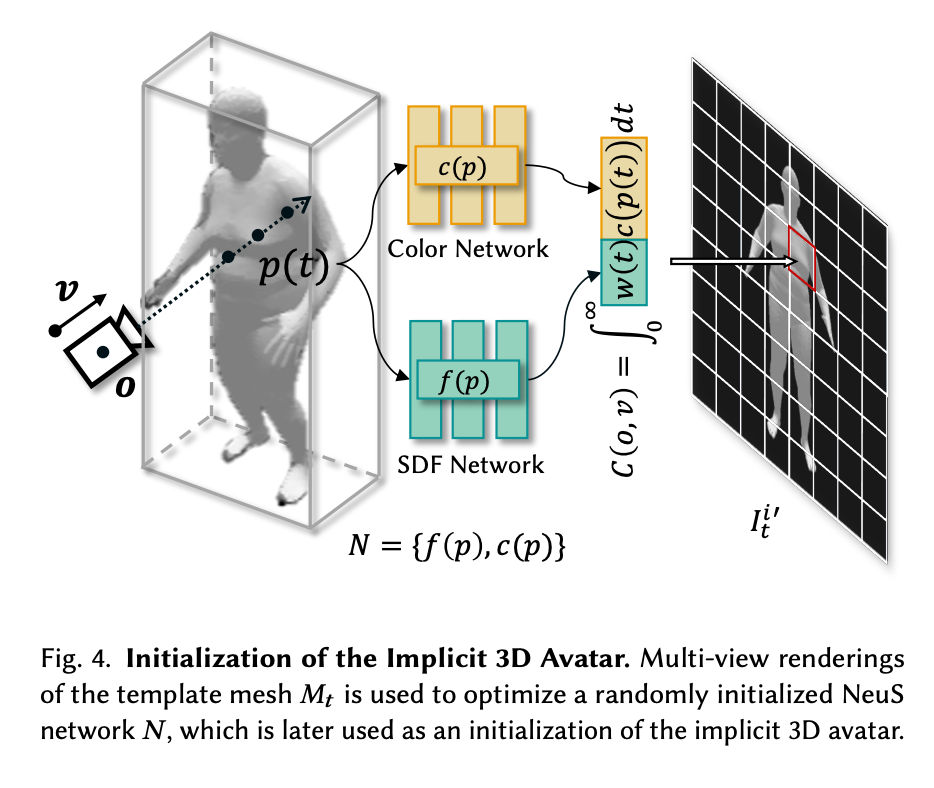
然后,作者选择将进一步着色和雕刻的步骤分离出来,分成两个阶段,以加速对人物的从粗到细的优化。首先,Mt被用来优化一个随机惯性的NeuS网络,N*。* NeuS网络由两个MLP子网络组成。"SDF网络𝑓(𝑝)将某个点𝑝作为输入,并输出到其最近表面的有符号距离。颜色网络𝑐(𝑝)将某个点𝑝作为输入,并输出该点的颜色。"(来源:)这些都是对人物进行初步的、比较小的重新着色和雕刻。
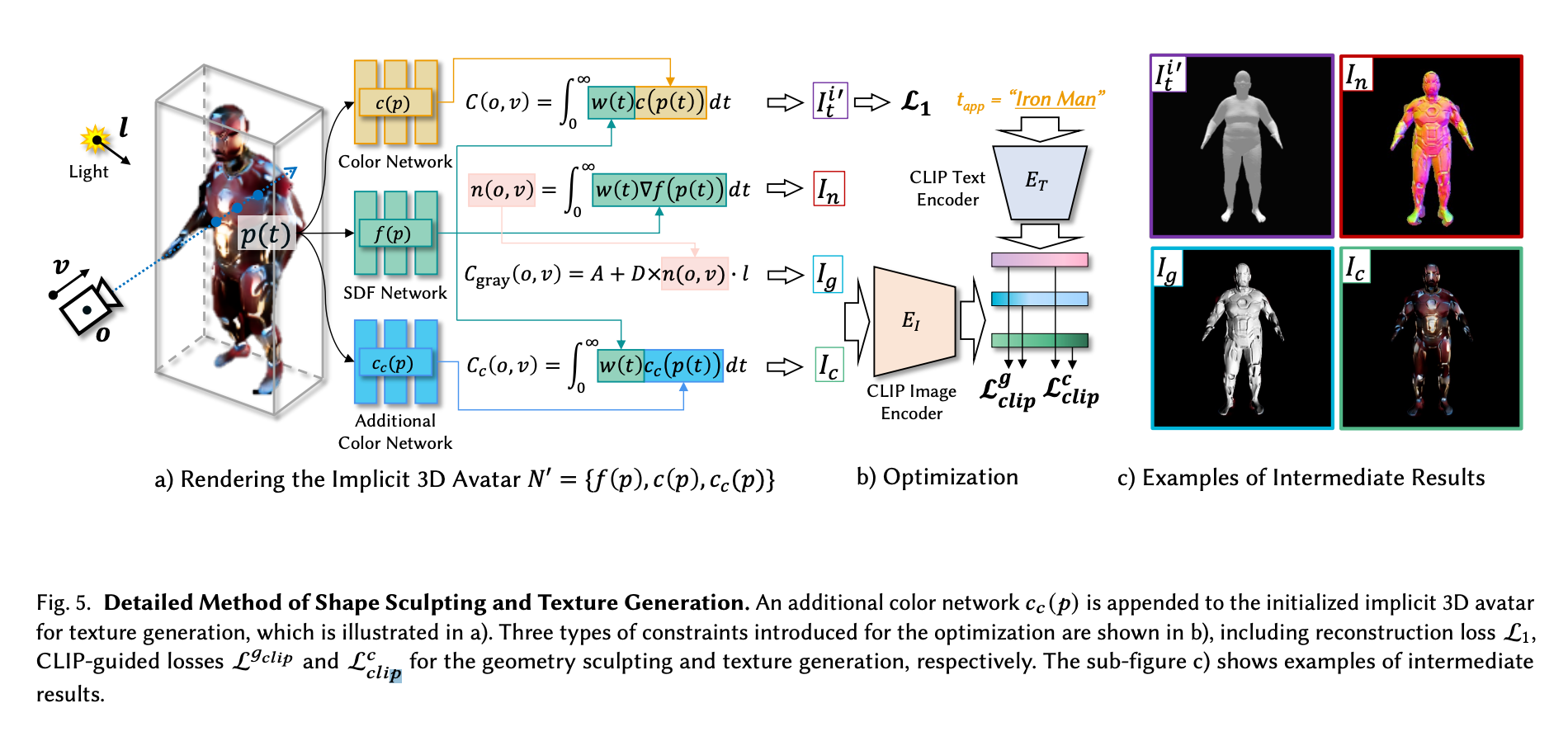
在下一个阶段,进行精细的细节处理和雕刻。为了不使着色或雕刻的能力受到任何损失,作者为初始化的隐性三维化身附加了一个额外的颜色网络,用于生成纹理(见上文)。每个颜色网络都与SDF网络同时工作,完成不同的任务:原始的c(p) 颜色网络和f(p)SDF 网络被用来重建网状Mt ,使用CLIP文本编码器的指导来匹配tapp提示,然后Cc(p)、附加网络和SDF网络f(p) 在CLIP编码图像的指导下进行更精细的层次细化。使用CLIP引导的损失,这个系统将一起产生一个精细的数字,在形状和细节方面接近输入的提示,但没有姿势。
姿势生成
为了使人物成为姿势的动画,我们需要回到生成过程的起点。在进行任何姿势或着色之前,他们首先有一个预先训练好的名为VPoser的VAE,使用AMASS数据集为提示建立一个表征的代码簿。这是为了尽可能多地收集SMPL模型身体形状的可能描述性身体类型。这本代码书然后被用来指导一系列用CLIP生成的候选姿势。这些姿势然后被用于运动序列的生成,使用以候选姿势为参考的运动先验。
该管道使用文本描述tmotion,其中每个姿势特征𝑓𝐼从代码书被用来计算与文本特征𝑓𝑇的相似度,这被用来选择Top-K条目作为候选姿势。然后,这些姿势被选为候选姿势集S,并被传递到动作动画阶段。
从一个姿势序列到动画
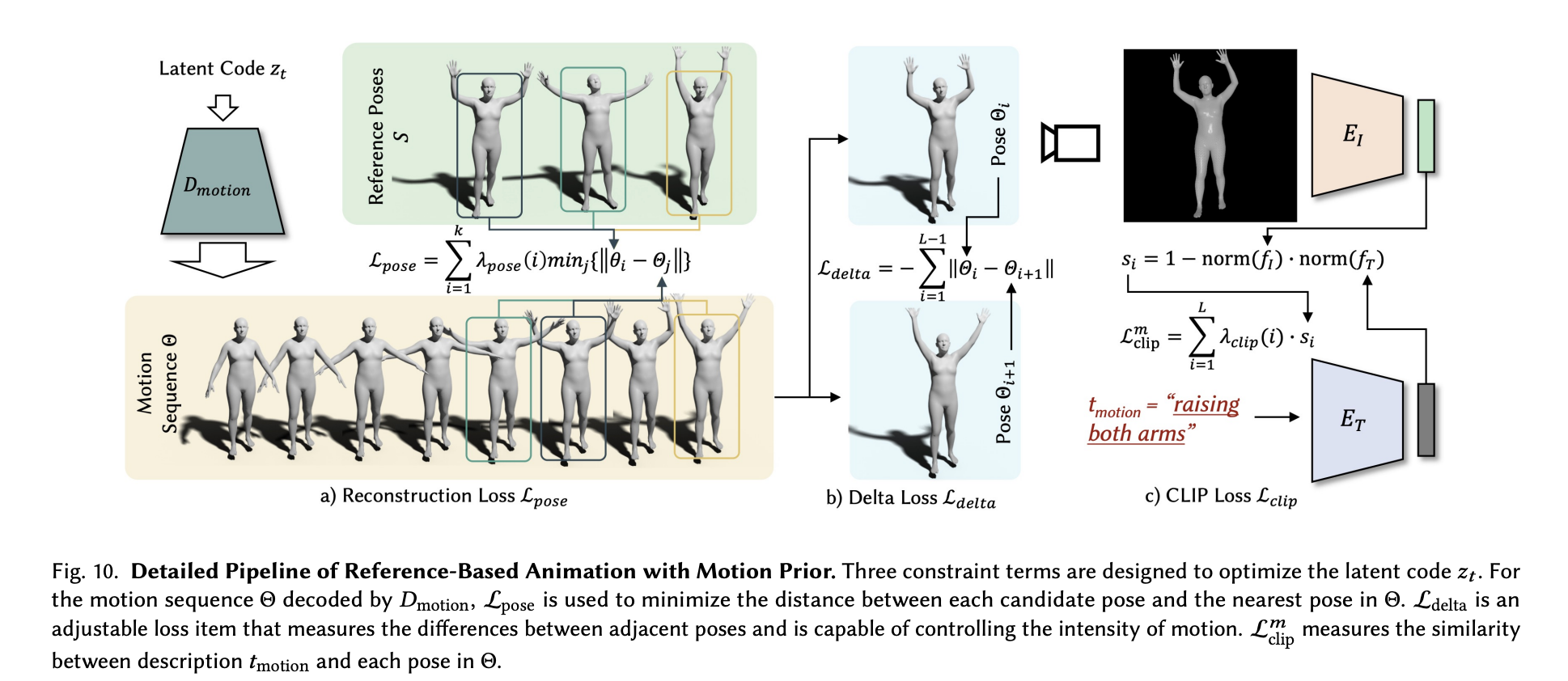
为了在一个序列中捕捉姿势,我们可以将其转移到我们的网格中,首先训练一个运动VAE来捕捉人类的运动先验。随着预训练的VAE现在能够识别SMPL模型中类似人类的运动,我们就可以使用候选姿势𝑆作为参考来优化运动VAE的潜在代码。为此,有三个损失项被用来优化我们的运动,使之更接近于提示。第一个,姿势损失,作为基线。这个损失可以单独用于重建原始姿势,但作者认为这给运动引入了一种不可思议的平滑性。为了进一步优化这个损失函数,他们引入了另外两个损失函数来调整损失姿势。Delta损失测量相邻姿势之间的差异,并用于影响运动的强度。最后,损失CLIP测量tmotion中的描述与序列中每个姿势之间的相似性。这些损失函数一起优化了姿势序列,给了我们序列Θ,它可以用来表示粗略模型姿势的动画步骤。
把它放在一起
因此,输出是由两部分组成的。首先,一个可动画化的三维化身被表示为一个网格,Mt.这在本文中被表示为𝑀={𝑉, 𝐹, 𝐶},其中𝑉是顶点,𝐹代表面,而𝐶代表顶点的颜色。然后,第二个输出是包含所需运动的姿势序列。结合起来,我们就得到了一个完整的形状和纹理的人物,它是根据tshape和tapp生成的,通过tmotion解释的姿势的时间轴来运动。
现在让我们看看在下一节中我们如何用代码获得第一个输出。
把这个项目带入生活
AvatarCLIP代码演示
要在Gradient上运行这个项目,首先在PyTorch运行时间上用你喜欢的任何GPU启动Gradient笔记本(不过值得注意的是,即使在A100-80GB上,这也将是一个漫长的训练序列)。然后,你要通过切换高级选项的切换,把这个URL作为工作区的URL,并把它粘贴到该区域。然后创建笔记本。
在这个演示中,我们将主要演示如何进行头像生成的细部设计和雕刻阶段。
设置环境
一旦你的笔记本旋转起来,打开并在终端输入以下内容,开始设置我们的环境。这在笔记本中也有描述。
# Needed repos
git clone https://github.com/gradient-ai/AvatarCLIP.git
git clone https://github.com/hongfz16/neural_renderer.git
# First set of requirements, courtesy of author team
pip install -r AvatarCLIP/requirements.txt
# additional installs for Gradient
pip install -U numpy # their requirements.txt has an outdated NumPy install you can fix instead if so desired.
pip install scikit-image
# install neural renderer as package on Gradient
pip install git+https://github.com/hongfz16/neural_renderer
# complete their set up process
%cd neural_renderer
python3 setup.py install
%cd ..
# final housekeeping and setup to display video later
apt-get update && apt-get install libgl1
apt install ffmpeg
接下来,去smpl.is.tue.mpg.de/index.html,…
unzip SMPL_python_v.1.1.1.zip
进口
接下来,我们将使用导入的软件包来运行这个演示。
# If you not here, make sure the next line is run somewhere in the notebook prior to this
# %cd /content/AvatarCLIP/AvatarGen/AppearanceGen
# imports
import os
import time
import logging
import argparse
import random
import numpy as np
import cv2 as cv
import trimesh
import torch
import torch.nn.functional as F
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from shutil import copyfile
from icecream import ic
from tqdm import tqdm
from pyhocon import ConfigFactory
from models.dataset import Dataset
from models.dataset import SMPL_Dataset
from models.fields import RenderingNetwork, SDFNetwork, SingleVarianceNetwork, NeRF
from models.renderer import NeuSRenderer
from models.utils import lookat, random_eye, random_at, render_one_batch, batch_rodrigues
from models.utils import sphere_coord, random_eye_normal, rgb2hsv, differentiable_histogram
from models.utils import my_lbs, readOBJ
import clip
from smplx import build_layer
import imageio
to8b = lambda x : (255*np.clip(x,0,1)).astype(np.uint8)
from main import Runner
输入外观描述
在下一个单元中,我们开始输入我们的提示并对粗略的模型生成进行调整。特别是,这是我们输入tapp来修改我们的粗略图的地方。目前,这被设置为对所有的输入采取中性的人物网格,然后给它们着色,以配合tapp的提示。
你可以通过编辑AppearanceDescription和conf_path变量的值来调整你在这里制作的人物的类型。它们默认设置为运行钢铁侠的配置示例。你可以在confs/examples/ 中找到更多的配置,并改变每个变量的字符串以对应变化。在这个演示中,我们将使用漫画作者One的开创性作品One Punch Man中的Saitama。
#@title Input Appearance Description (e.g. Iron Man)
AppearanceDescription = "Iron Man" #@param {type:"string"}
torch.set_default_tensor_type('torch.cuda.FloatTensor')
FORMAT = "[%(filename)s:%(lineno)s - %(funcName)20s() ] %(message)s"
logging.basicConfig(level=logging.INFO, format=FORMAT)
conf_path = 'confs/examples_small/example.conf'
f = open(conf_path)
conf_text = f.read()
f.close()
conf_text = conf_text.replace('{TOREPLACE}', AppearanceDescription)
# print(conf_text)
conf = ConfigFactory.parse_string(conf_text)
print("Prompt: {}".format(conf.get_string('clip.prompt')))
print("Face Prompt: {}".format(conf.get_string('clip.face_prompt')))
print("Back Prompt: {}".format(conf.get_string('clip.back_prompt')))
细化和雕琢粗略的网格
为了开始生成过程,我们首先将Runner对象实例化,将我们在最后一个单元中设置的变量作为参数。然后,它为我们初始化CLIP ViT-B/32模型,并带出SMPL文件以用于纹理和塑形。最后,train_clip() ,初始化并运行生成过程。
注意:如果你想改变训练的迭代次数,从默认的30000次,你需要到
/AvatarCLIP/AvatarGen/AppearanceGen/main.py,把第50行的变量改变为所需的值。
#@title Start the Generation!
runner = Runner(conf_path, 'train_clip', 'smpl', False, True, conf)
runner.init_clip()
runner.init_smpl()
runner.train_clip()
在单元格运行完毕后,你可以到/AvatarCLIP/AvatarGen/AppearanceGen/exp/smpl/examples ,以获得每张照片之间间隔100个训练步骤的模型的剧照。这可以与下面的代码单元一起使用,以创建一个漂亮的视频,显示人物在生成过程中是如何变化的。
#@title Generate a Video of Optimization Process (RGB)
import os
from tqdm import tqdm
import numpy as np
from IPython import display
from PIL import Image
from base64 import b64encode
image_folder = 'exp/smpl/examples/Saitama/validations_extra_fine'
image_fname = os.listdir(image_folder)
image_fname = sorted(image_fname)
image_fname = [os.path.join(image_folder, f) for f in image_fname]
init_frame = 1
last_frame = len(image_fname)
min_fps = 10
max_fps = 60
total_frames = last_frame - init_frame
length = 15 #Desired time of the video in seconds
frames = []
for i in range(init_frame, last_frame): #
frames.append(Image.open(image_fname[i]))
#fps = last_frame/10
fps = np.clip(total_frames/length,min_fps,max_fps)
from subprocess import Popen, PIPE
p = Popen(['ffmpeg', '-y', '-f', 'image2pipe', '-vcodec', 'png', '-r', str(fps), '-i', '-', '-vcodec', 'libx264', '-r', str(fps), '-pix_fmt', 'yuv420p', '-crf', '17', '-preset', 'veryslow', 'video.mp4'], stdin=PIPE)
for im in tqdm(frames):
im.save(p.stdin, 'PNG')
p.stdin.close()
p.wait()
mp4 = open('video.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
display.HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
当这一切完成后,你应该留下一个像下面这样的视频。这比作者使用的例子的质量要低一些,但显然以一种详细的方式捕捉到了输入的精神。
0:00
/
1×
结束思考
本系列的第一部分就到此为止。在这篇博文中,我们介绍了AvatarCLIP是如何操作的,并展示了如何使用它从所提供的、易于使用的配置中生成一个有纹理和雕刻的人物。在这一系列关于AvatarCLIP的下一部分中,我们将更深入地讨论模型的动画部分。
请务必访问AvatarCLIP的原始版本的项目页面。这是一个全新的 repo,所以预计在2022年下半年会有一些变化和改进,以进一步改善这个项目。
谢谢你的阅读。
今天就为你的机器学习工作流程增加速度和简单性吧
