

Pandas是数据科学和分析领域最受欢迎的Python库之一。我喜欢说它是 "Python的SQL"。为什么?因为Pandas可以帮助你在Python中管理二维数据表。当然,它还有很多其他的功能。(例如,很多流行的Python机器学习库都是建立在pandas之上的。)在这个pandas教程系列中,我将向你展示pandas库中最重要和最常用的功能。我将专注于你作为初级数据分析师或数据科学家必须知道的事情。这是第一集,我们将从最基本的开始
注1:这是一个实践性的教程,所以我建议和我一起做编码的部分
在我们开始之前
如果你还没有这样做,我建议先浏览一下这些文章。
如何成为一名数据科学家
(Tomi Mester的50分钟免费视频课程)
只需在这里订阅Data36新闻通讯(免费)!
我接受Data36的隐私政策。(没有垃圾邮件。只有有用的数据科学相关内容。当你订阅后,我将每周给你发几封邮件,让你了解最新的信息。你会得到文章、课程、小抄、教程和许多很酷的东西)。
现在就进入!
要遵循这个熊猫教程...
-
你将需要一个功能完备的数据服务器,上面有Python3、
numpy和pandas。
注1:如果你还没有,不用担心:通过这个教程,你也可以建立自己的数据服务器和Python3。而通过这篇文章,你也可以设置numpy和pandas,。 -
下一步:登录你的服务器并启动Jupyter。(我们已经在上一步安装了这个,对吗?) 然后在你喜欢的浏览器中打开一个新的Jupyter笔记本。(如果你不知道怎么做,我真的建议你看一下我在 "开始之前"部分链接的文章)。
注意:我也会把我的Jupyter笔记本重命名为pandas_tutorial_1。
启动Jupyter笔记本
- 而开始的最后一步:通过在单元格中运行这两行,将
numpy和pandas导入你的Jupyter笔记本。
import numpy as np
import pandas as pd

注意:传统的做法是把pandas 称为pd 。当你在import 语句的末尾加上as pd ,你的Jupyter笔记本就会明白,从这一点上看,每当你输入pd ,你实际上是指pandas 库。
好了,现在我们把一切都准备好了!
让我们开始学习这个pandas教程吧!
第一个问题是。
如何在pandas中打开数据文件
你可能把你的数据放在.csv 文件或SQL表中。也许是Excel文件。或者.tsv 文件。或者其他的东西。但在所有情况下,目标都是一样的。如果你想用pandas来分析这些数据,第一步就是把它读成一个与pandas兼容的数据结构。
Pandas数据结构
在pandas中,有两种类型的数据结构。
- 系列
- DataFrames。
熊猫系列
潘达斯系列是一个可以存储数值的一维数据结构("一维ndarray")--对于每个数值,它也持有一个唯一的索引。你可以把它看成是一个大表中的一个单列。如果你现在知道这么多关于Series的知识就足够了,我以后会再来讨论它。
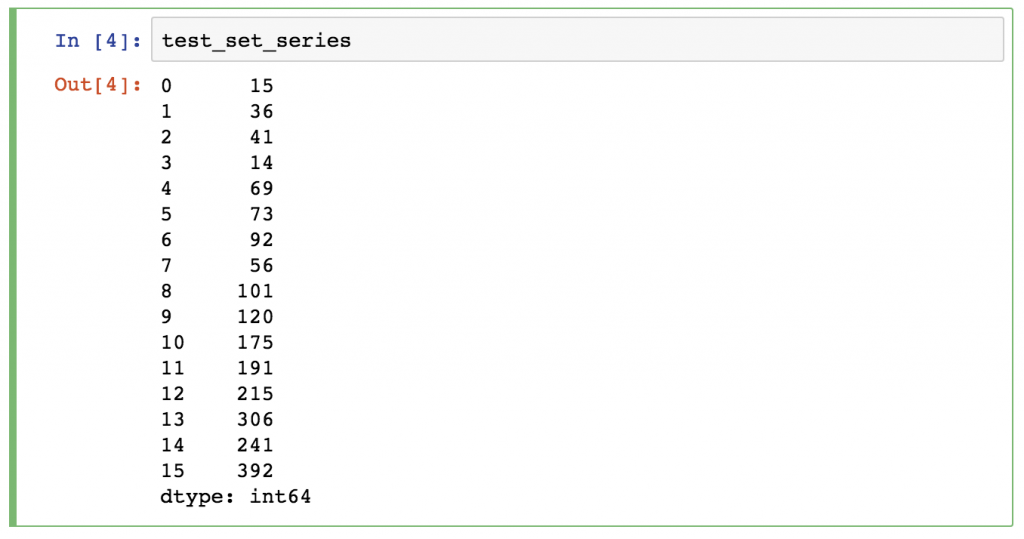
Pandas系列的例子
Pandas DataFrame
PandasDataFrame是一个二维(或多维)的数据结构--基本上是一个有行和列的表格。列有名称,行有索引。与pandas Series(只有一列有标签)相比,DataFrame实际上是整个数据表。你可以把它看成是pandas Series(列与列之间相邻)的集合。
无论是哪种方式。DataFrame是主要的pandas DataStructure!
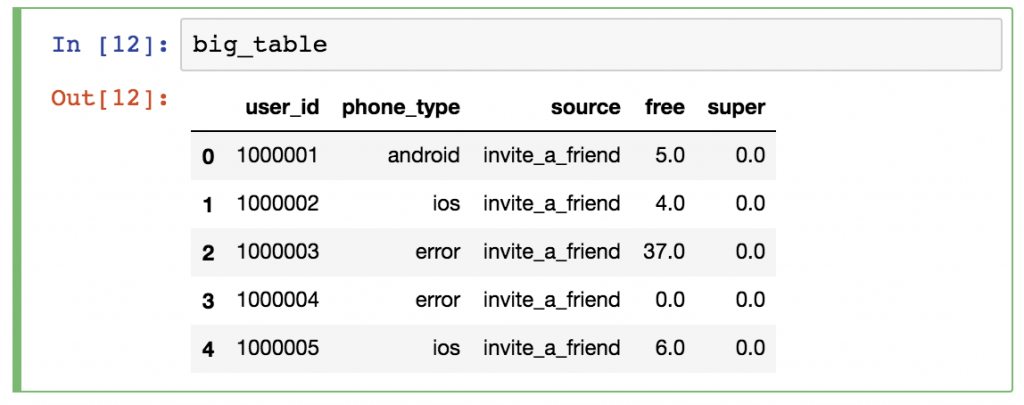
Pandas DataFrame例子
在这篇pandas教程中,我主要关注的是DataFrame,而在后面的文章中我将谈论Series。原因很简单:我将谈论的大多数分析方法在二维数据集中比在一维数组中更有意义。
将.csv文件加载到pandas DataFrame中
好了,是时候把事情付诸实践了让我们把一个.csv的数据文件加载到pandas中去吧!
这里有一个函数,叫做read_csv() 。
从一个简单的演示数据集开始,叫做zoo!这一次--为了练习--你将为自己创建一个.csv文件!这里是原始数据。
animal,uniq_id,water_need
elephant,1001,500
elephant,1002,600
elephant,1003,550
tiger,1004,300
tiger,1005,320
tiger,1006,330
tiger,1007,290
tiger,1008,310
zebra,1009,200
zebra,1010,220
zebra,1011,240
zebra,1012,230
zebra,1013,220
zebra,1014,100
zebra,1015,80
lion,1016,420
lion,1017,600
lion,1018,500
lion,1019,390
kangaroo,1020,410
kangaroo,1021,430
kangaroo,1022,410
回到你的Jupyter主页标签,创建一个新的文本文件...
...然后复制-粘贴上述动物园的数据到这个文本文件中...
...然后把这个文本文件重命名为zoo.csv!
好了,这就是我们的.csv文件!
现在,回到你的Jupyter笔记本(我命名为 pandas_tutorial_1),并在其中打开这个新创建的.csv文件!
同样,你必须使用的函数是read_csv()
在一个新的单元格中输入这个内容。
pd.read_csv('zoo.csv', delimiter = ',')
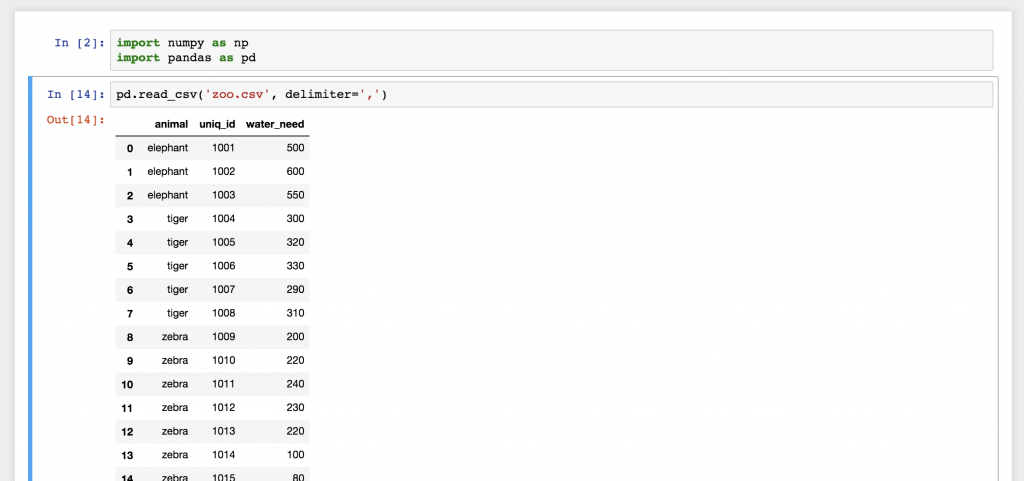
然后你就可以了!这就是zoo.csv 数据文件带来的pandas!这不是一个漂亮的2D表格吗?嗯,实际上这是一个pandas的数据框架每一行前面的数字被称为索引。而上面的列名则是从我们的zoo.csv 文件的第一行中自动提取的。
好吧,在现实生活中,你可能永远也不会像我们刚才那样为自己创建一个.csv数据文件,这里。你知道这是一个pandas教程--但在现实生活中,你将与已经存在的数据文件一起工作,你可能会从你要工作的数据工程师那里得到这些文件。重点是,你必须在这里多学一样东西:如何将.csv文件下载到你的服务器。
如果你是从《初级数据科学家的第一个月》视频课程来的,那么你已经处理过将你的.txt或.csv数据文件下载到你的数据服务器,所以你一定很熟练了......但如果你不是从课程来的(或者如果你想学习另一种方法将.csv文件下载到你的服务器并获得另一个令人兴奋的数据集),请遵循这些步骤。
第0步--我们将在这个pandas教程中使用的数据文件
我已经为你上传了一个小的样本数据集,在这里。DATASET
(直接链接--如果点击上面的链接不起作用,就把它复制粘贴到你的浏览器栏里:46.101.230.157/dilan/pandas_tutorial_read.csv)
如果你点击该链接,数据文件将被下载到你的电脑上。但你并不想把这个数据文件下载到你的电脑上,对吗?你想把它下载到你的服务器,然后把它加载到你的Jupyter笔记本。这只需要再花两个步骤。
第1步 - 将它下载到服务器上!
回到你的Jupyter笔记本,输入这个命令。
!wget 46.101.230.157/dilan/pandas_tutorial_read.csv
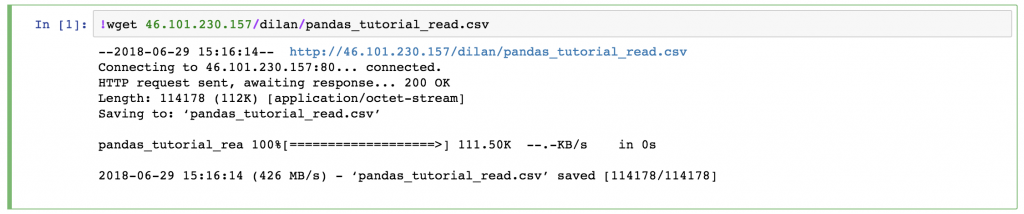
这就把pandas_tutorial_read.csv 文件下载到你的服务器上。看看就知道了。
看到了吗?它就在那里。
如果你点击它...
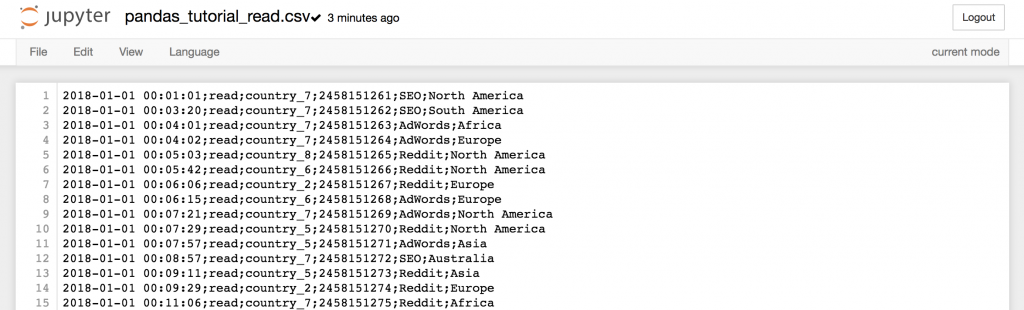
...你甚至可以检查出其中的数据。
第二步--将带有.read_csv 的.csv文件加载到一个DataFrame中
现在,再次回到你的Jupyter笔记本,使用我们之前使用过的同样的.read_csv() 函数(但不要忘记改变文件名和分隔符的值)。
pd.read_csv('pandas_tutorial_read.csv', delimiter=';')
完成了!数据被加载到一个pandas DataFrame中。
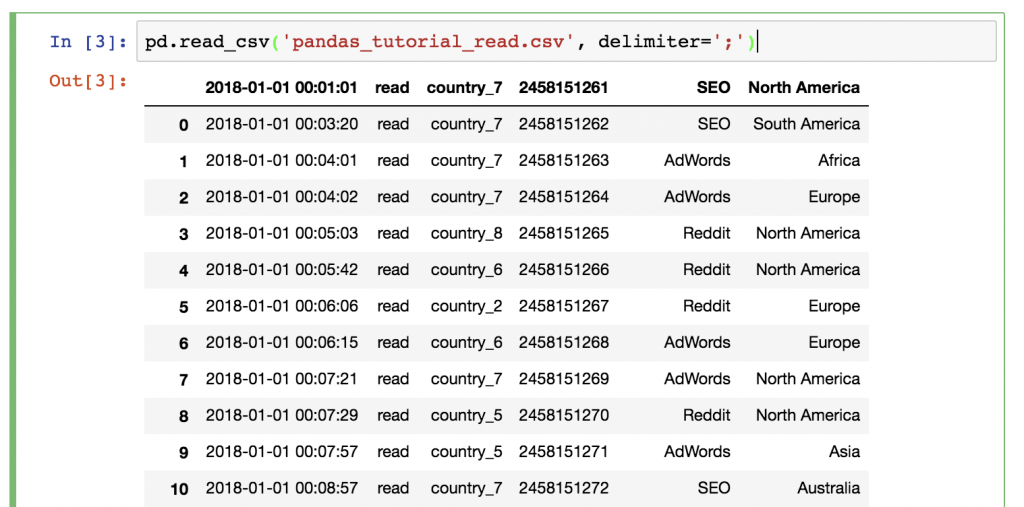
是不是感觉有些不对劲?是的,这次我们的.csv文件中没有头,所以我们必须手动定义它!将names 参数添加到你的.read_csv() 函数中。
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])
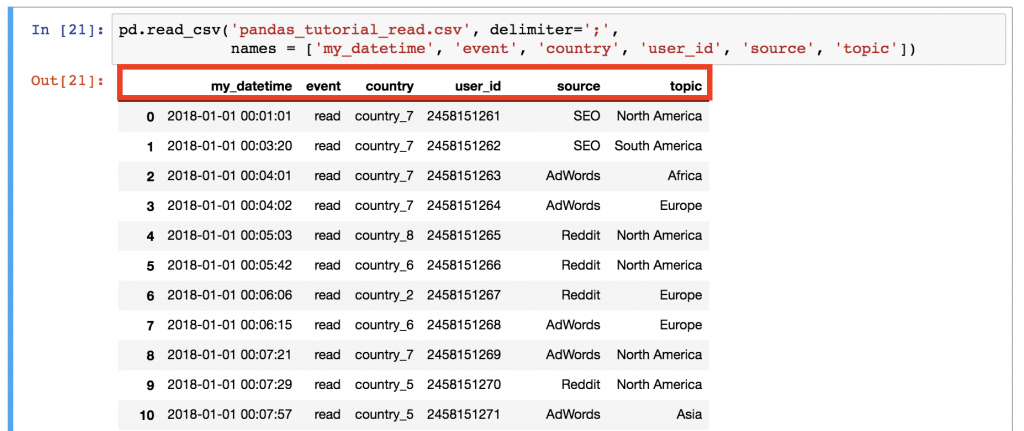
好多了!
就这样,我们终于把我们的.csv数据加载到了pandas的DataFrame中**!**
注1:只是让你知道,有一个替代方法。(你可以直接使用URL加载.csv数据。在这种情况下,数据将不会被下载到你的数据服务器。
直接从服务器上读取.csv数据(使用其URL)
注2:如果你想知道这个数据集里有什么--这是一个旅游博客的数据日志。这只是一天的日志(如果你是JDS课程的参与者,你会在课程的最后一周得到更多的这个数据集;-))。我想各栏的名字是不言自明的。
初级数据科学家的第一个月
一个100%实用的在线课程。一个为期6周的模拟在一个真实的创业公司做初级数据科学家的课程。
"解决真正的问题,获得真正的经验--就像在真正的数据科学工作中一样"。
了解更多...
在pandas中从DataFrame中选择数据
这是pandas教程系列的第一集,让我们从几个非常基本的数据选择方法开始--在接下来的几集里,我们会更深入地了解!
#1 如何打印整个DataFrame
在pandas中,你可以做的最基本的方法就是简单地将整个DataFrame打印到屏幕上。没什么特别的。
尽管在开始时掌握一个概念是很好的。
为了处理一个特定的数据集,你不需要一次又一次地运行pd.read_csv() 函数。你只需在第一次运行时将它的输出存储到一个变量中即可。例如
article_read = pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])
之后,你可以随时调用这个article_read 变量来打印你的DataFrame!
注意:我知道......如果你以前使用过Python,这并不新鲜。但是如果你有SQL背景,在Python环境中工作时,最好习惯于将你的东西存储在变量中。
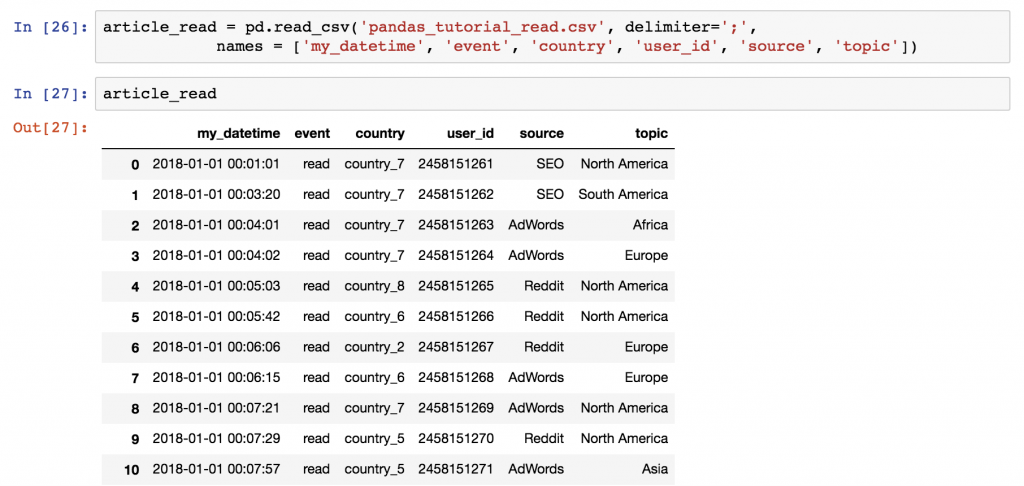
#2 如何打印你的数据框架的样本(例如前5行)
有时,不打印整个数据框架和用数据淹没你的屏幕是很方便的。当几行就够了,你可以只打印前5行--通过键入。
article_read.head()
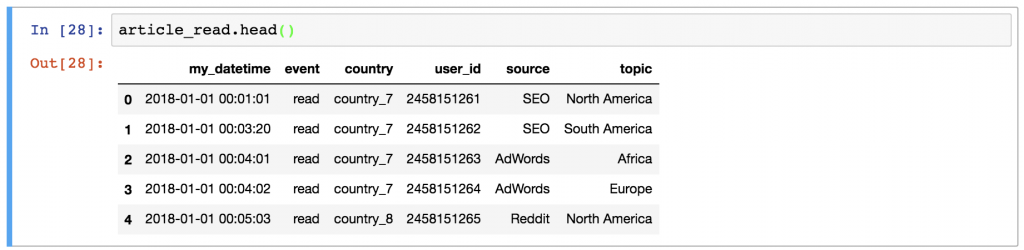
或者通过输入最后几行。
article_read.tail()
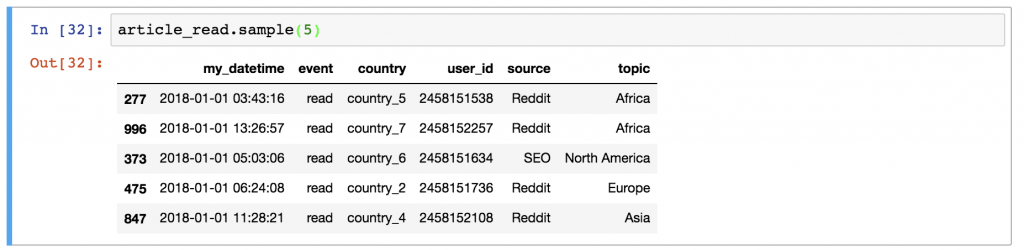
或者通过输入一些随机的行。
article_read.sample(5)
#3 如何选择DataFrame的特定列
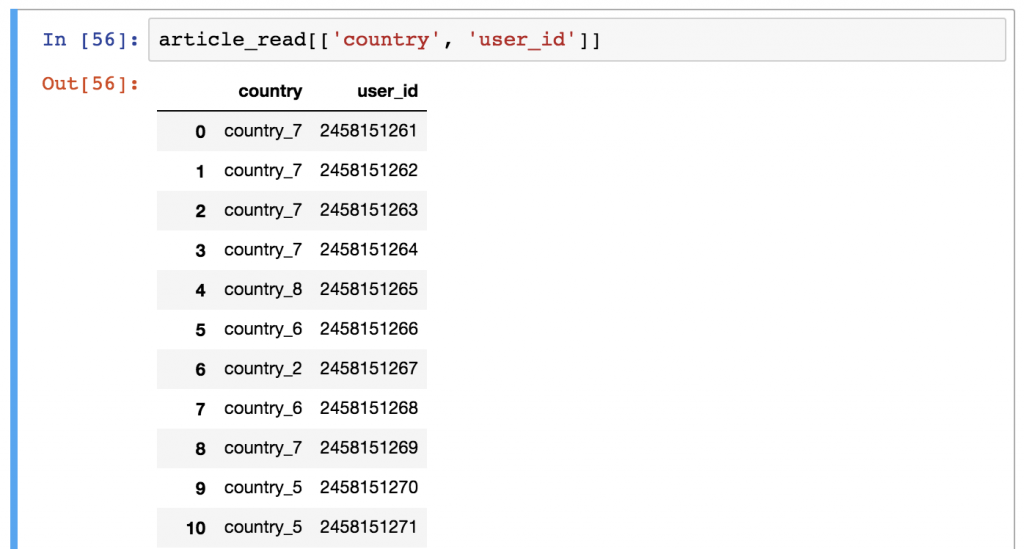
这个问题有点棘手--但是非常常用,所以最好现在就学起来!比方说,你只想打印country 和user_id 列。
你应该使用这个语法。
article_read[['country', 'user_id']]
有没有人猜到为什么我们要使用双括号框架?我承认,这似乎有点过于复杂,但这里有一个东西可以帮助你记住。外括号框架告诉 pandas 你想选择列 - 而内括号则是列名的列表。*(记得吗?Python 列表*总是在括号框架之间。)
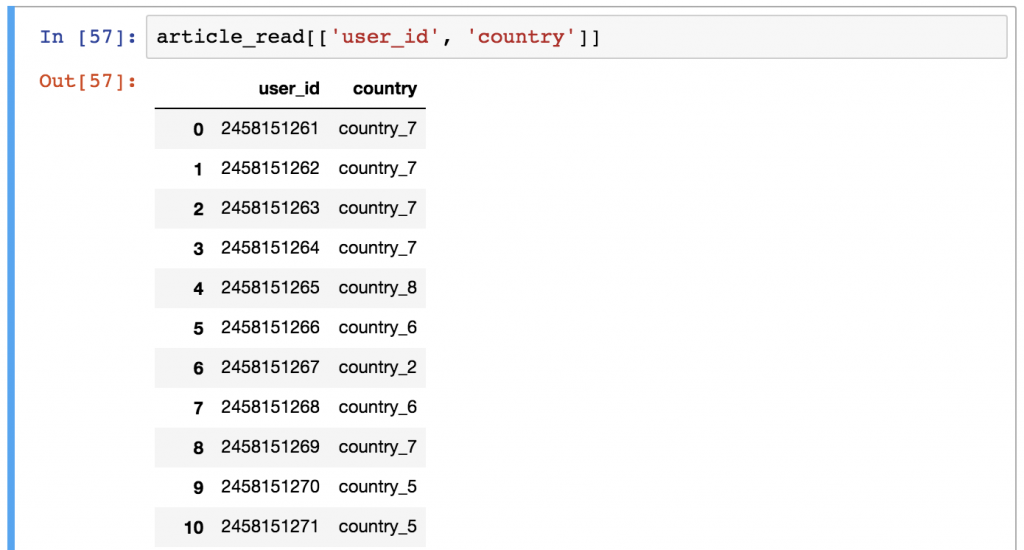
顺便说一下,如果你改变了列名的顺序,返回的列的顺序也会改变。
article_read[['user_id', 'country']]
你将得到你所选列的 DataFrame。
注意:有时候(特别是在机器学习项目中),你想获得系列对象而不是DataFrame。你可以使用这两种语法中的任何一种获得pandas Series(并且只选择一列)。
*article_read.user_id*
*article_read['user_id']*
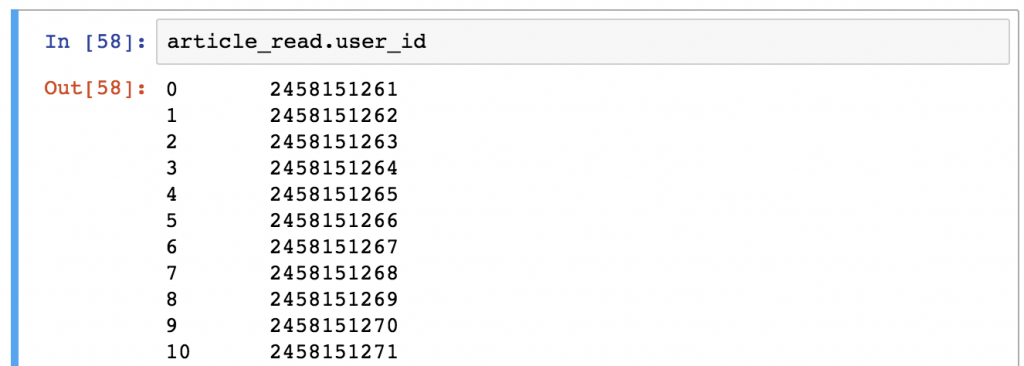
输出是一个Series对象,而不是一个DataFrame对象。
#4 如何过滤你的DataFrame中的特定值
如果说之前的列选择方法有点棘手,那么这一次就会觉得非常棘手!(但同样,你必须要有足够的时间来进行筛选。(但同样,你必须经常使用它,所以现在就学吧!)
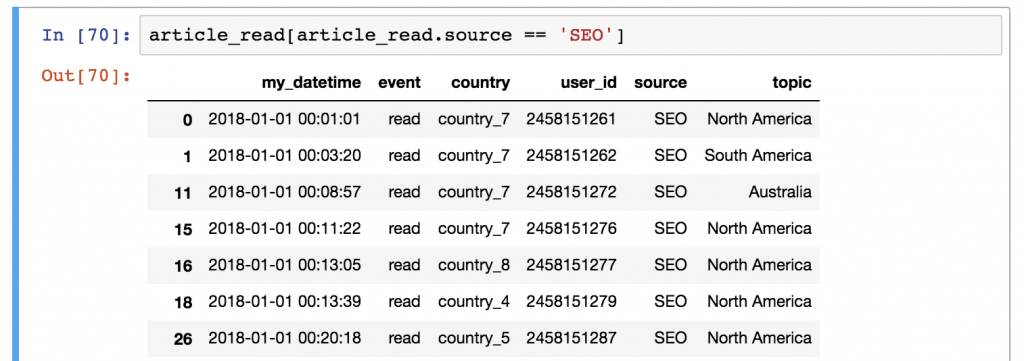
比方说,你想看到一个只有来自SEO source 的用户的列表。在这种情况下,你必须对source 列中的'SEO' 值进行过滤。这就是你在pandas中的做法。
article_read[article_read.source == 'SEO']
了解pandas对数据过滤的看法是值得的。
**步骤1)**首先,它在括号框之间运行语法。article_read.source == 'SEO'
这将评估你的DataFrame的每一行:article_read.source 列的值是否为'SEO' ?其结果是布尔值(True 或False )。
**第2步)**然后从article_read 表中,选择并打印每一行的值是True ,不打印任何值是False 的行。
感觉很曲折?也许吧。但这就是它的方式,所以让我们来学习它,因为你会经常用到它!(以后你会开始使用它。 (以后,你会开始欣赏pandas的实用主义逻辑,我保证)。
Pandas函数可以在彼此之间使用!
理解pandas的逻辑是非常线性的(与SQL相比,例如),这一点非常重要。
这种线性逻辑最好的部分是,如果你应用一个函数,你总是可以对它的结果应用另一个函数。在这种情况下,后一个函数的输入将永远是前一个函数的输出。
这里有一个例子可以帮助你理解这一点。
让我们结合这两种选择方法。
article_read.head()[['country', 'user_id']]
这个代码片断做了两件事。
.head()部分首先选择我们数据集的前5行- 然后
[['country', 'user_id']]部分只选择这前5行的country和user_id列。
你能用不同的函数链得到同样的结果吗?当然,你可以。
article_read[['country', 'user_id']].head()
在这个版本中,你先选择列,然后取前5行。结果是一样的--函数的顺序(和执行)是不同的。
还有一件事。如果你把'article_read'值替换成原始的read_csv() 函数,会发生什么。
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])[['country', 'user_id']].head()
这也会起作用--只是它很难看(而且效率低)。但是,你要明白,用pandas工作,无非是逐一应用正确的函数和方法,这真的很重要。
Pandas教程的挑战:测试自己
像往常一样,这里有一个简短的作业来测试你从这个pandas教程中所学到的知识!
解决了它,本文的内容就能更好地沉淀下来!
这是你的任务。
选择user_id,country 和topic 列中来自country_2 的用户 !只打印前五行!
好的,去解决它吧!
..
.
这就是我的解决方案!
它可以是一个单行本。
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head()
或者,为了更透明,你可以把它分成更多行。
ar_filtered = article_read[article_read.country == 'country_2']
ar_filtered_cols = ar_filtered[['user_id','topic', 'country']]
ar_filtered_cols.head()
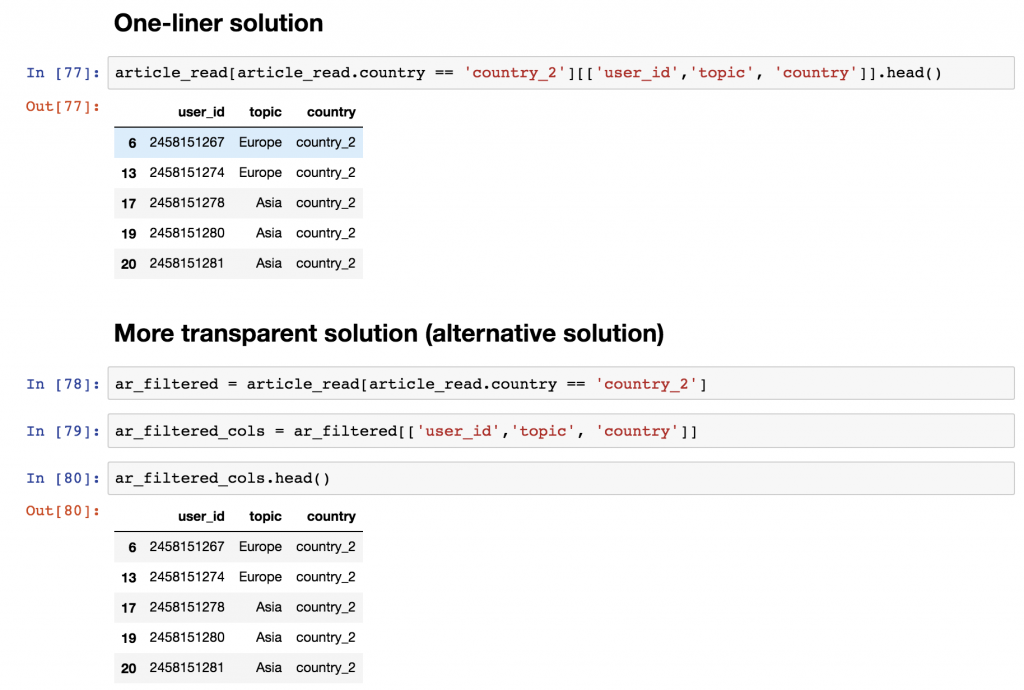
无论哪种方式,逻辑都是一样的。
- 首先,你把你的原始数据框架(
article_read)。 - 然后,你过滤掉
country值为country_2([article_read.country == 'country_2'])的行。 - 然后,你选择需要的三列 (
[['user_id','topic', 'country']]) - 最后,你只取前五行(
.head())。
熊猫教程第一集的结论
我的Pandas教程系列的第一集已经结束了!你的工作做得很好。干得好!在下一篇文章中,你会学到更多关于不同的聚合方法(例如:sum,mean,max,min )和关于分组...所以基本上是关于分割。继续努力,在这里继续。熊猫教程,第二集!
- 如果你想了解更多关于如何成为一名数据科学家,请参加我的50分钟的视频课程。如何成为一名数据科学家。(它是免费的!)
- 也可以看看我为期6周的在线课程。初级数据科学家的第一个月》视频课程。
干杯。
托米-梅斯特
The postPandas Tutorial 1: Pandas Basics (Reading Data Files, DataFrames, Data Selection)appeared first onData36.
