

简介
在本教程中,我们将看到Sklearn的两种编码方法--LabelEncoder和OnehotEcoder,用于将分类变量编码为数字变量。我们将首先了解什么是分类数据以及为什么它需要机器学习的编码。然后我们将了解和比较标签编码和一热编码的技术,最后看看它们在Sklearn中的例子。
什么是分类数据
分类数据是一种描述实体特征的数据:
- 性别:男性、女性、其他
- 教育资格:高中,本科,硕士或博士
- 城市:孟买、德里、班加罗尔或钦奈,等等。
通常情况下,分类数据在性质上是非数字性的,是文本。然而,分类数据有可能用数字表示,例如,颜色可以用数字表示,如红色=1,橙色=2,蓝色=3,等等,但它不具有任何数学意义。
- 同时阅读 - 统计学中的数据类型 - 机器学习的基本理解
为什么ML中需要分类数据编码?
大多数机器学习算法,如回归、支持向量机、神经网络、KNN等,不能处理基于文本的分类数据。因此,作为数据预处理的一部分,有必要将分类数据转换为某种数字编码,然后将其送入ML算法。
然而,应该注意的是,基于树的机器学习算法,如决策树和随机森林可以在分类数据上工作,你可能不需要做分类数据编码。
我们接下来看看分类数据编码的两种最常见的技术--i)标签编码和ii)一热编码。
标签编码
在标签编码中,特征的每个不同的值都被分配了数值,从0到N-1,其中N是不同值的总数。
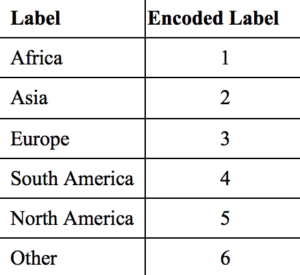
例如,如果我们有世界各大洲,如['非洲'、'亚洲'、'欧洲'、'南美洲'、'北美洲'、'其他'],使用标签编码后,这些分类值将被编码为[0,1,2,3,4,5]。
单一热编码
在这一技术中,首先,对于特征的每个不同的值,都会创建新的列。然后在这些新的列中,该值在行中的缺失用1表示,而缺失则用0表示。
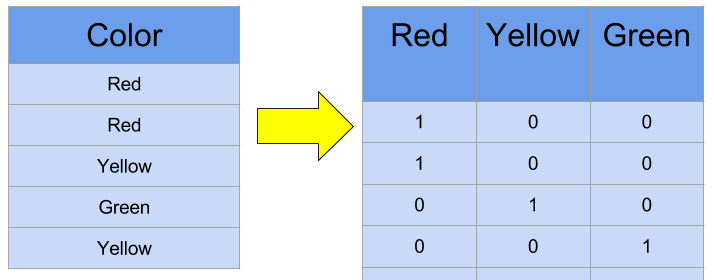
在下面的例子中,颜色这个特征有三个值:红色、黄色和绿色。正如我们所看到的,我们创建了三列,分别对应这些值。最后,每一行中的值的存在和不存在分别用1和0表示。
(来源)
标签编码与一热编码
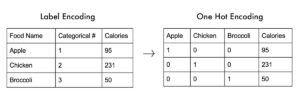
标签编码对我们人类来说可能看起来很直观,但机器学习算法会因为假设它们有一个序数排名而误解它。在下面的例子中,苹果的编码是1,而Brocolli的编码是3。但这并不意味着Brocolli比苹果高,然而它确实误导了ML算法。这就是为什么标签编码不怎么被用于机器学习的分类编码。
One Hot Encoding非常适用于克服Label Encoding的缺点,并被普遍用于机器学习算法中。然而,它也有一些缺点。当分类变量的cardinality很高时,即分类列有太多不同的值,它可能会产生一个非常大的编码,有大量的附加列,甚至可能不适合内存或产生不那么好的结果。
Sklearn中LabelEncoder的例子
我们现在将看到如何使用Sklearn的Label Encoder进行分类编码。我们将看到一个端到端的例子,使用一个数据集,通过应用标签编码创建一个ML模型。
关于数据集
这是一个关于初创企业的小数据集,由51行和5列组成。我们的目标是根据数据集的其他四个独立变量来预测利润。由于这里的一个变量 "State "是一个分类变量,我们将首先使用Sklearn LabelEncoder和OneHotEncoder将其编码为数字变量。
导入库和读取数据集
我们首先为我们的例子导入所有必要的库。接下来,我们将CSV文件中的数据集读取到Pandas数据框中。
In[1]:
#importing the necassary libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#reading the dataset
df=pd.read_csv(r"C:\Users\Veer Kumar\Downloads\MLK internship\Encoder\50_Startups.csv")
df.head(10)
Out[1]:
| 研发支出 | 行政管理 | 营销支出 | 国家 | 盈利 | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | 纽约 | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | 加州 | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | 佛罗里达州 | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | 纽约 | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | 佛罗里达州 | 166187.94 |
| 5 | 131876.90 | 99814.71 | 362861.36 | 纽约 | 156991.12 |
| 6 | 134615.46 | 147198.87 | 127716.82 | 加州 | 156122.51 |
| 7 | 130298.13 | 145530.06 | 323876.68 | 佛罗里达州 | 155752.60 |
| 8 | 120542.52 | 148718.95 | 311613.29 | 纽约 | 152211.77 |
| 9 | 123334.88 | 108679.17 | 304981.62 | 加州 | 149759.96 |
在[2]中:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50 entries, 0 to 49
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 R&D Spend 50 non-null float64
1 Administration 50 non-null float64
2 Marketing Spend 50 non-null float64
3 State 50 non-null object
4 Profit 50 non-null float64
dtypes: float64(4), object(1)
memory usage: 1.8+ KB
应用Sklearn标签编码
Sklearn预处理中有一个LabelEncoder()模块,可以用来做标签编码。在这里,我们首先创建一个LabelEncoder()的实例,然后通过传递数据帧的状态列来应用fit_transform。
在输出中,我们可以看到状态中的值被编码为0、1和2。
在[3]:
# label_encoder object
label_encoder =LabelEncoder()
# Encode labels in column.
df['State']= label_encoder.fit_transform(df['State'])
df.head(10)
Out[3]:
| 研发支出 | 行政管理 | 营销支出 | 国家 | 盈利 | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | 2 | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | 0 | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | 1 | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | 2 | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | 1 | 166187.94 |
| 5 | 131876.90 | 99814.71 | 362861.36 | 2 | 156991.12 |
| 6 | 134615.46 | 147198.87 | 127716.82 | 0 | 156122.51 |
| 7 | 130298.13 | 145530.06 | 323876.68 | 1 | 155752.60 |
| 8 | 120542.52 | 148718.95 | 311613.29 | 2 | 152211.77 |
| 9 | 123334.88 | 108679.17 | 304981.62 | 0 | 149759.96 |
训练测试分离
在这里,我们将通过把数据集分成训练集和测试集来分离特征变量和目标变量。
在[4]中:
X=df.iloc[:,[0,1,3]]
y=df.iloc[:,[2]]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.10,random_state=42)
创建和训练模型
我们现在创建一个Sklearn线性回归的对象,通过传递数据集来训练模型。
在[5]中:
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(X_train,y_train)
Out[5]:
LinearRegression()
寻找模型的准确度
在测试数据上的模型精度将告诉我们,我们的模型在训练数据上的概括性如何,基于对未见过的数据的预测值。
在[7]中:
from sklearn.metrics import r2_score
y_pred=model.predict(X_test)
score=r2_score(y_test,y_pred)
print("Accuracy for our testing dataset using LabelEncoder is : {:.3f}%".format(score*100) )
Out[7]:
Accuracy for our testing dataset using LabelEncoder is : 66.826%
Sklearn中OneHotEncoder的例子
我们现在将看到如何使用Sklearn的One Hot Encoding进行分类编码。我们将使用与上面的例子相同的数据集,因此开始的类似部分将被跳过,我们直接跳到下面的编码部分。
Sklearn中的单热编码
Sklearn预处理中有一个OneHotEncoder()模块,可以用来做一个热编码。
我们首先创建一个OneHotEncoder()的实例,然后通过传递状态列应用fit_transform。这将返回一个带有多列分类值的新数据框架。这被存储在一个中间数据框中,最后与原始数据框连接。
drop='first'参数是用来帮助我们克服由于一个热编码的虚拟变量而可能产生的多重共线性。这也被称为虚拟变量陷阱。请放心,通过放弃这一栏,不会有任何信息的损失。
在[9]:
# creating instance of one-hot-encoder
enc = OneHotEncoder(drop='first')
enc_df = pd.DataFrame(enc.fit_transform(data[['State']]).toarray())
# merge with main df bridge_df on key values
df =df.join(enc_df)
df.head()
出[9]:
| 研发支出 | 行政管理 | 营销支出 | 国家 | 盈利 | 0 | 1 | |
|---|---|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | 2 | 192261.83 | 0.0 | 1.0 |
| 1 | 162597.70 | 151377.59 | 443898.53 | 0 | 191792.06 | 0.0 | 0.0 |
| 2 | 153441.51 | 101145.55 | 407934.54 | 1 | 191050.39 | 1.0 | 0.0 |
| 3 | 144372.41 | 118671.85 | 383199.62 | 2 | 182901.99 | 0.0 | 1.0 |
| 4 | 142107.34 | 91391.77 | 366168.42 | 1 | 166187.94 | 1.0 | 0.0 |
训练测试分离
在这里,我们将把特征变量和目标变量分开,对数据集进行训练测试分割。
在[10]中:
X=df.iloc[:,[0,1,2,5,6]]
y=df.iloc[:,[4]]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.10,random_state=42)
创建和训练模型
我们现在创建一个Sklearn线性回归的对象,通过传递数据集来训练模型。
在[12]中:
model=LinearRegression()
model.fit(X_train,y_train)
Out[12]:
LinearRegression()
寻找模型的准确度
在测试数据上的模型精度将告诉我们,我们的模型在训练数据上的概括性如何,基于对未见过的数据的预测值。
在[14]中:
y_pred=model.predict(X_test)
score=r2_score(y_test,y_pred)
print("Accuracy for our testing dataset using OneHotEncoder is : {:.3f}%".format(score*100) )
Out[14]:
Accuracy for our testing dataset using OneHotEncoder is : 86.748%
比较
正如我们在上面的标签编码与一热编码部分所讨论的那样,我们在上面的例子中也可以清楚地看到标签编码的相同缺点。
在标签编码的情况下,该模型只有66.8%的准确率,但在一个热编码的情况下,该模型的准确率上升了22%,达到86.74%。
总结
我们希望你喜欢我们的教程,现在能更好地理解如何在Python中使用Sklearn(Scikit Learn)实现LabelEncoder和OneHotEncoder。在这里,我们通过使用数据集建立线性回归模型,说明了两者的端到端例子。我们还做了标签编码与一热编码的比较。
