

简介
任何计算机视觉爱好者肯定都听说过用于物体检测的YOLO模型。自从第一个YOLOv1在2015年推出以来,它在计算机视觉界获得了太多的欢迎。随后,YOLOv2、YOLOv3、YOLOv4和YOLOv5的多个版本已经发布,尽管是由不同的人发布。在这篇文章中,我们将简要介绍YOLO家族从YOLOv1到YOLOv5的所有物体检测模型的背景。
YOLO物体检测器模型的基本工作原理
对于每个基于ML的模型来说,精度和召回率对于推断和判断其准确性和稳健性非常重要。因此,YOLO的创建者一直试图建立一个能使mAP(平均精度)最大化的物体检测模型。
- 召回率是真阳性与总阳性预测(正确或不正确)的比率。
- 精度是真阳性与地面真实阳性(总的正确预测)的比率。
- 所有平均精度的平均值被称为平均平均精度(mAP)。
一级检测器(输入、骨干、颈部、密集预测),两级检测器(一级加稀疏预测)。
除此之外,所有的YOLO模型的结构都有一个类似的组件主题,概述如下
- **主干。**一个卷积神经网络,积累并产生不同形状和大小的视觉特征。分类模型如ResNet、VGG和EfficientNet被用作特征提取器。
- **颈部。**一组在将特征传递给预测层之前整合和混合特征的层。例如。特征金字塔网络(FPN)、路径聚合网络(PAN)和双FPN
- **头部:**吸收颈部的特征和边界框的预测。在特征和边界框坐标上执行分类和回归,以完成检测过程。输出4个值,一般是x、y坐标以及宽度和高度。
YOLOv1--开始
第一个YOLO模型是由Joseph Redmon等人在他们2015年发表的题为*"You Only Look Once: Unified, Real-Time Object Detection "* 的论文中介绍的*。* 在那之前,RCNN模型是最受追捧的物体检测模型。虽然RCNN系列模型很准确,但相对较慢,因为它是一个多步骤的过程,为边界框找到建议的区域,然后对这些区域进行分类,最后进行后处理以完善输出。
创建YOLO的目的是摒弃多阶段,只在单一阶段进行物体检测,从而增加推理时间。
性能
YOLOv1有一个63.4mAP,推理速度为每秒45帧(每幅图像22ms)。当时,它的速度比RCNN系列有了巨大的提高,其推理速度从143ms到20秒不等。
比较图
技术上的改进
YOLO模型的基本工作依赖于其统一的检测技术,该技术将物体检测的不同部分组合到一个单一的反馈神经网络中。
该模型将传入的图像分为许多网格,并计算出物体在该网格内的概率。这是对图像被分成的所有网格进行的。之后,该算法将附近的高价值概率网格作为一个单一物体进行分组。低价值的预测被丢弃,使用的技术称为非最大抑制(NMS)。
该模型以类似的方式进行训练,将检测到的每个物体的中心与地面实况进行比较。为了检查模型是否正确并相应地调整权重。
YOLO v1(来源)
YOLOv2 - 更好、更快、更强
YOLOv2是由Joseph Redmon和Ali Farhadi在2016年发布的论文,题为*"YOLO9000:更好、更快、更强"。* 9000标志着YOLOv2能够检测超过9000个类别的物体。这个版本比以前的版本YOLOV1有各种改进。
性能方面
YOLOv2在VOC 2012数据集上注册了78.6 mAP。我们可以从下表中看到,与其他物体检测模型相比,它在VOC 2012数据集上的表现非常好。
准确率比较。最先进的精确度,推断率提高2-10倍(来源)
技术改进
YOLOv2版本引入了锚定盒的概念。锚定框只不过是图像的预定义区域,说明了要检测的物体的理想化位置。我们计算预测的边界盒和预定义的锚定盒的重叠率(IoU)。IoU值作为一个阈值,决定检测到的物体的概率是否足以进行预测。
交叉大于联合(IoU)度量的图形说明(来源)。
但在YOLO的情况下,锚定框不是随机计算的。相反,YOLO算法检查训练数据并对其进行聚类(维度聚类)。所有这些都是为了确保所使用的锚箱代表了我们将要训练的模型的数据。这对提高准确率有很大帮助。
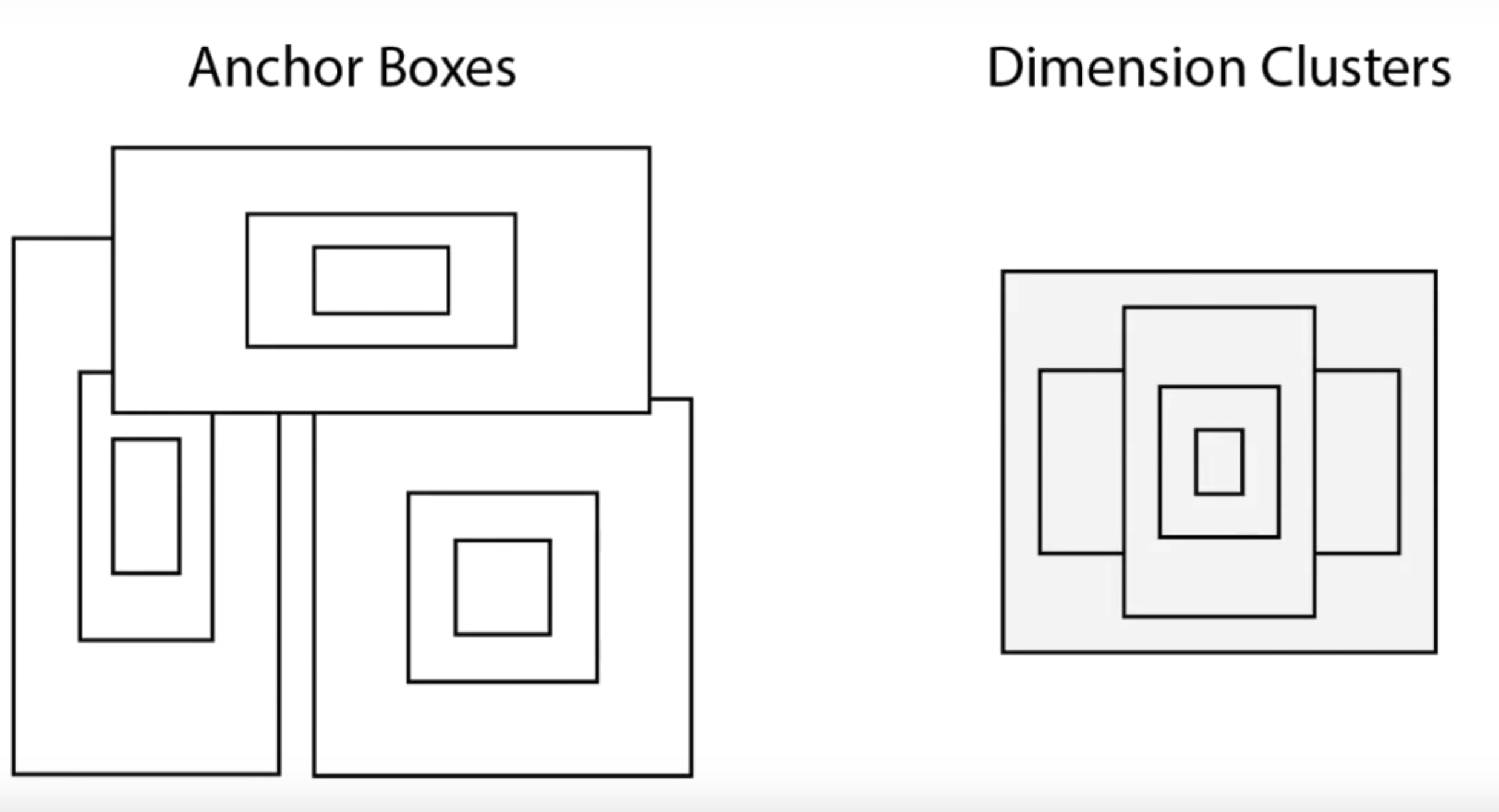
锚箱转换为维度聚类
额外的改进
- 为了适应不同的长宽比,YOLOv2模型在整个训练过程中会随机调整大小(这被称为多尺度训练)。
- 为了使模型具有鲁棒性,YOLOv2模型在COCO数据集(80个带边界框的类)和ImageNet数据集(22k个不带边界框的类)的组合上进行训练。当模型处理带有标签的图像时,会计算出检测和分类误差。而当模型看到一个无标签的图像时,它只反向传播分类误差。这种结构被称为WordTree。
- 使用名为darknet19的分类网络架构(YOLO的骨干),推理速度高达200 FPS,mAP为75.3。
暗网19架构
YOLOv3:一个渐进的改进
2018年,约瑟夫-雷德蒙和阿里-法哈迪在他们的论文 *《YOLOv3:一个递增的改进》*中介绍了YOLOv3的第三个版本。这个模型比早期的模型大一点,但更准确,而且速度也足够快。
性能
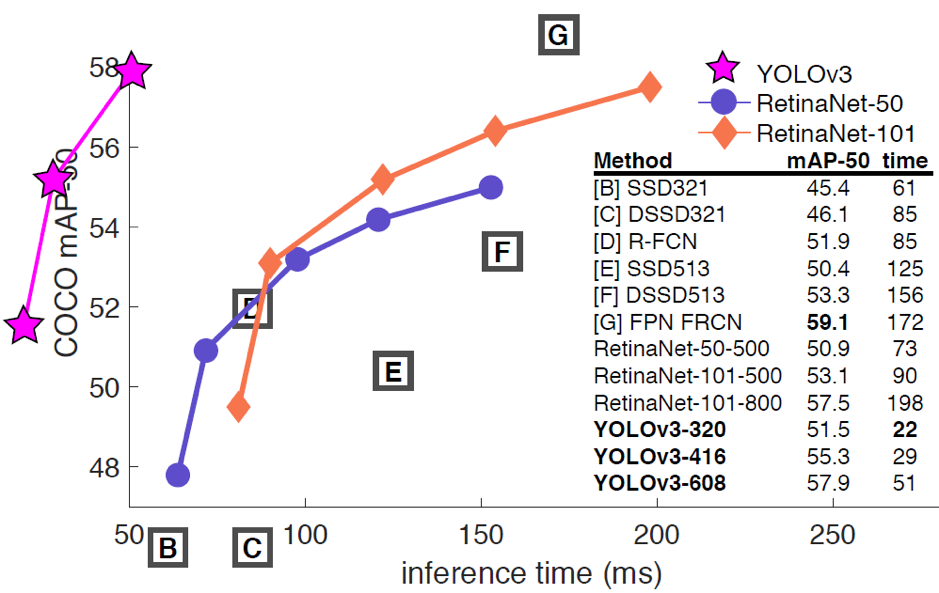
YOLOv3-320的mAP为28.2,推理时间为22毫秒。(在COCO数据集上)。这比SSD物体检测技术快3倍,但具有类似的准确性。
比较
技术改进
YOLOv3由75个卷积层组成,没有使用全连接或池化层,这大大减少了模型的大小和重量。它提供了两全其美的方法,即使用残差模型(来自ResNet模型)与特征金字塔网络(FPN)进行多特征学习,同时保持最小的推理时间。
- 特征金字塔网络是一个特征提取器,它为一张图像提取不同类型/形式/尺寸的特征。它将所有的特征连接起来,使模型能够学习局部和一般的特征。
- 通过采用逻辑分类器和激活,YOLOv3的类别预测在准确性方面超过了RetinaNet-50和101。
- 作为骨干,YOLOv3模型使用Darknet53架构。
YOLOv4--最佳的物体探测速度和准确度
YOLOV4不是由Joseph Redmon发布的,而是由Alexey Bochkovskiy等人在2020年的论文 《YOLOv4:物体检测的最佳速度和准确性》中发布的。
- 还可以阅读 - YOLOv4物体检测教程与图片和视频。初学者指南
性能
YOLOv4模型站在其他检测模型如efficientDet和ResNext50的顶端。它有Darknet53主干(与YOLOv3相同)。
模型比较
技术上的改进
YOLOv4引入了免费包(在不增加推理成本的情况下带来模型性能提升的技术)和特殊包(在增加计算成本的情况下提高准确性的技术)的概念。
它的速度为每秒62帧,在COCO数据集上的mAP为43.5%。
特产袋(BOF)
- 数据扩增技术。Cutmix(剪切并混合含有我们想要检测的物体的多张图像),Mixup(图像的随机混合),Cutout,Mosaic数据增量。
- 边界盒回归损失。对不同类型的边界盒回归类型进行实验。例子。MSE, IoU, CIoU, DIoU.
- 正则化。不同类型的正则化技术,如Dropout, DropPath, Spatial dropout, DropBlock。
- 正则化。引入了交叉小批归一化,这已被证明可以提高准确性。还有迭代批处理规范化和GPU规范化等技术。
特殊袋 BOS
- 空间注意模块(SAM)。通过利用空间间的特征关系生成特征图。有助于提高准确性,但会增加训练时间。
- 非最大抑制(NMS):在物体被分组的情况下,我们得到多个边界框作为预测。非最大限度的抑制减少了错误/多余的方框。
- 非线性激活函数。在YOLOv4模型中测试了不同类型的激活函数。例如ReLU, SELU, Leaky, Swish, Mish。
- 跳过连接,如加权剩余连接(WRC)或跨阶段部分连接(CSP)。
YOLOv5:最新的YOLO?
YOLOv5据说是YOLO家族的下一个成员,由Ultranytics公司在YOLOv4之后几天于2020年发布。目前还没有发布任何文件,社区里有一场争论,它是否有理由使用YOLO的品牌,因为它只是YOLOv3的PyTorch实现。
- 另请阅读 - YOLOv5物体检测简介及教程
- 另请阅读 - 教程 - YOLOv5在Colab中的自定义对象检测
性能
性能的真实性无法保证,因为目前还没有正式的论文。它实现了与其他YOLO模型相同甚至更好的准确性(mAP为55.6),同时耗费较少的计算能力。
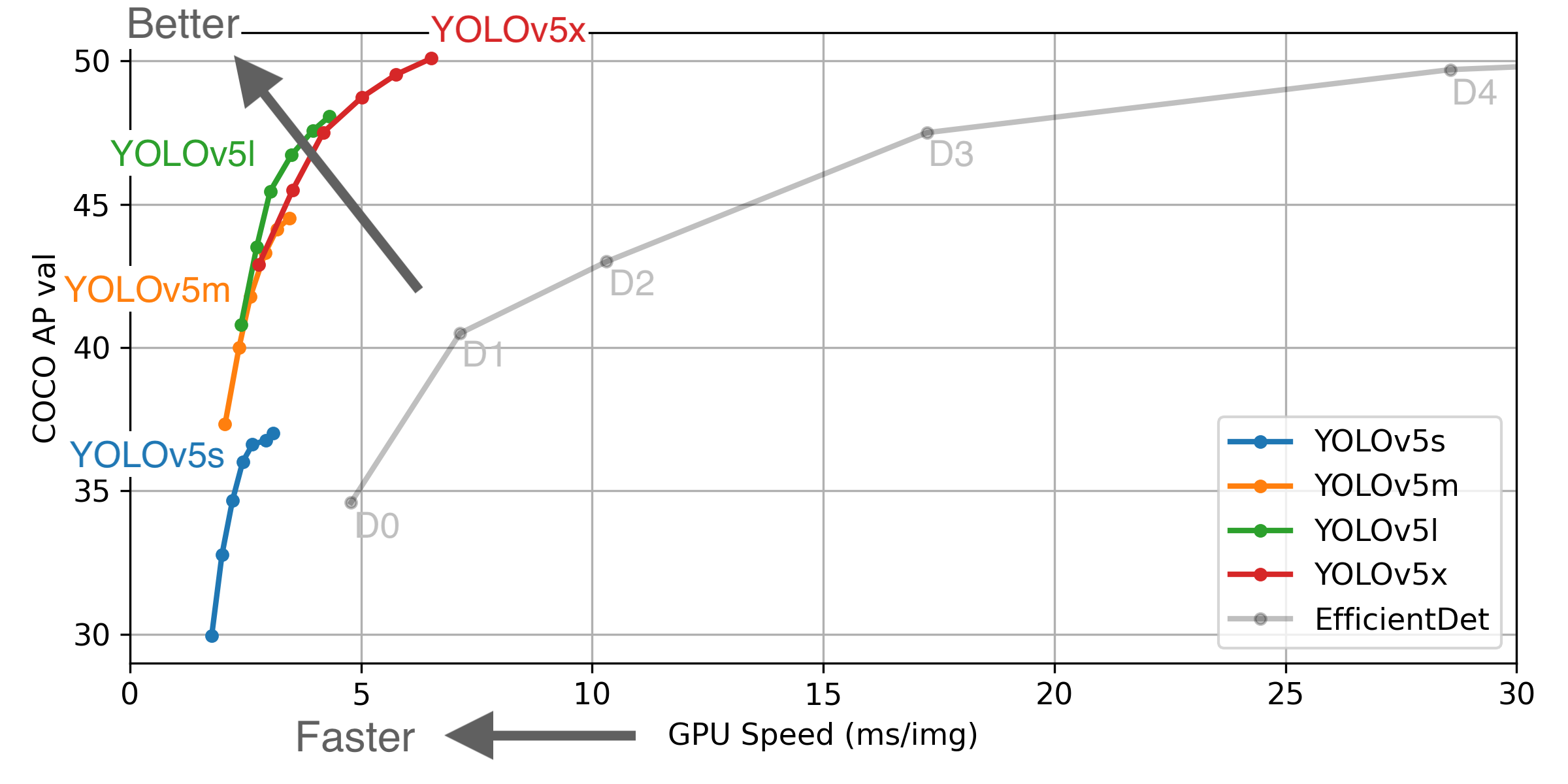
不同模型的准确度比较
技术上的改进
- 更好的数据增强和损失计算(现在模型的基础已经从C语言转向PyTorch)。
- 自动学习锚箱(现在不需要手动添加锚箱了)
- 在骨干网中使用跨阶段部分连接(CSP)。
- 在模型的颈部使用路径聚合(PAN)网络
- 更容易训练和测试的框架(PyTorch)。
- 易于使用和安装。
- 新版本支持YAML文件而不是CFG文件,这大大增强了模型配置文件的布局和可读性。
The postA Brief History of YOLO Object Detection Models From YOLOv1 to YOLOv5appeared first onMLK - Machine Learning Knowledge.
