

简介:在今天的教程中,我们将看看如何使用Sklearn Simple Imputer处理数据集中的缺失值
在今天的教程中,我们将看看如何通过使用Sklearn Simple Imputer来处理数据集中的缺失值。在现实世界中,我们总是会遇到由于许多原因而导致缺失值的数据集。缺失数据本质上是一块缺失的信息,如何处理它对你的机器学习模型来说变得非常重要。有多种处理缺失数据的技术,它们可以通过使用Sklearn的SimpleImputer模块轻松实现。
我们将首先了解缺失数据到底意味着什么,它的不同类型的特征是什么。然后,我们将了解估算这种缺失数据的各种策略,然后看到Scikit Learn的Simple Imputer的例子。
什么是缺失数据
顾名思义,当一个属性的值在数据集中缺失时,就被称为缺失值。对数据科学家来说,处理这些缺失值是非常棘手的,因为对这些缺失值的任何错误处理最终都会影响到机器学习模型的准确性。
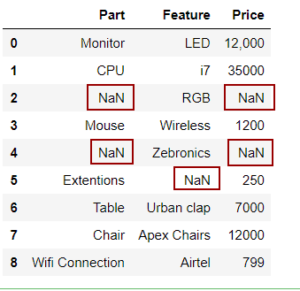
缺失数据的类型
在处理缺失数据之前,你应该首先了解缺失数据的各种特征。 缺失的数据属于以下几类之一
1.随机缺失(MAR)
在这种情况下,缺失的数据与数据集中的其他变量有某种关系。例如,在一项调查中,出于安全考虑,大多数女性可能没有填写电话号码字段。
2.完全随机缺失(MCAR)
在这种情况下,数据的缺失是随机的,与数据集中的其他变量没有关系。例如,一些数据可能由于某些技术问题或人为错误而随机丢失。
3.非随机缺失(MNAR)
在这种情况下,数据不是随机缺失的,缺失的原因是本应被采集的数据。MNAR在发现和处理上是相当棘手的。 例如,在一份调查表中,有钱人可能不会填写收入一栏,因为他们不愿意透露。
如何处理缺失的数据
有各种策略可以解决数据缺失的问题,但是哪种策略最有效取决于你的数据集。没有经验法则,所以你必须评估你的数据集并尝试各种策略。
1.丢弃缺失数据的变量
在这个策略中,包含缺失数据的行或列被完全删除。这应该谨慎使用,因为你可能最终会失去关于数据的重要信息。领域知识对于决定删除列是否是你的数据集的理想解决方案相当有用。
2.代入数据
在这一技术中,缺失的数据由一个合适的替代物来填补或估算,其背后有多种策略。
i) 用平均值替换
在这里,所有缺失的数据都被相应列的平均值所取代。它只适用于数字字段。然而,我们在这里必须谨慎,因为如果该列中的数据包含异常值,其平均值就会产生误导。
ii) 用中位数替换
在这里,缺失的数据被替换成该列的中位数,同样,它只适用于数字列。
iii) 用最频繁出现的数据替换
在这种技术中,缺失的数据用某一列中出现次数最多的数值来填补。这种方法既适用于数字列也适用于分类列。
iv) 用常数替换
在这种方法中,缺失的数据在整个过程中被一个常数取代。这种方法既可以用于数字列,也可以用于分类列。
Sklearn简单输入法
Sklearn提供了一个模块SimpleImputer,可以用来应用我们上面讨论的所有四种缺失数据的归因策略。
Sklearn Imputer vs SimpleImputer
旧版本的sklearn曾经有一个模块Imputer来做所有的归因转换。然而,Imputer模块现在已经被废弃了,在最近的Sklearn版本中已经被一个新的模块SimpleImputer取代。因此,对于所有的归纳目的,你现在应该在Sklearn中使用SimpleImputer。
Simple Imputer在Sklearn中的例子
创建玩具数据集
我们将用随机数创建一个玩具数据集,然后随机设置一些数值为空值。为了使这个数据集更适合我们的例子,我们复制了数据帧的两个单元。
In[1]:
# Create a radnom datset of 10 rows and 4 columns
df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD'))
# Randomly set some values as null
df = df.mask(np.random.random((10, 4)) < .15)
# Duplicate two cells with same values
df['B'][8] = df['B'][9]
df
Out[1]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | 钠 | 0.080238 | ǞǞǞ |
| 1 | 1.225041 | 0.505089 | -1.997088 | 钠 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | 钠 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | 无 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | 0.810893 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
i) 使用平均数的Sklearn SimpleImputer
我们首先创建一个SimpleImputer的实例,策略为 "平均"。这是默认的策略,即使没有通过它,它也将只使用平均值。最后,对数据集进行拟合和转换,我们可以看到,B列和D列的空值被各自的平均值所取代。
In[2]:
mean_imputer = SimpleImputer(strategy='mean')
result_mean_imputer = mean_imputer.fit_transform(df)
pd.DataFrame(result_mean_imputer, columns=list('ABCD'))
输出[2]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.000173 | 0.080238 | -0.153853 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -0.153853 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.000173 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -0.153853 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
ii) Sklearn SimpleImputer with Median
我们首先创建一个SimpleImputer的实例,策略为 "中位数",然后对数据集进行拟合和转换。我们可以看到,B列和D列的空值被各自列的平均值所取代。
在[3]:
median_imputer = SimpleImputer(strategy='median')
result_median_imputer = median_imputer.fit_transform(df)
pd.DataFrame(result_median_imputer, columns=list('ABCD'))
输出[3]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.213231 | 0.080238 | -0.278455 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -0.278455 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.213231 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -0.278455 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
iii) Sklearn SimpleImputer with Most Frequent
我们首先创建一个SimpleImputer的实例,策略为 "最频繁",然后对数据集进行拟合和转换。
如果没有最频繁出现的数字,Sklearn SimpleImputer将用该列上最低的整数进行归纳。
我们可以看到,B列的空值被替换为-0.343604,这是该列中最常出现的数字。在D列中,由于没有这样频繁出现的数字,空值被替换为最低的数字-1.190406。
在[4]中:
most_frequent_imputer = SimpleImputer(strategy='most_frequent')
result_most_frequent_imputer = most_frequent_imputer.fit_transform(df)
pd.DataFrame(result_most_frequent_imputer, columns=list('ABCD'))
输出[4]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.343604 | 0.080238 | -1.190406 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -1.190406 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.343604 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -1.190406 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
iv) 带有常数的Sklearn SimpleImputer
我们首先创建一个SimpleImputer的实例,策略为 "常量",fill_value为99。如果我们不提供fill_value,它将把数字列的默认值定为0。同样在数字列中,SimpleImputer不接受字符串作为默认填充。
数据集经过拟合和转换,我们可以看到所有的空值都被替换成了99。
In[5]:
constant_imputer = SimpleImputer(strategy='constant',fill_value=99)
result_constant_imputer = constant_imputer.fit_transform(df)
pd.DataFrame(result_constant_imputer, columns=list('ABCD'))
Out[5]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | 99.000000 | 0.080238 | 99.000000 |
| 1 | 1.225041 | 0.505089 | -1.997088 | 99.000000 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | 99.000000 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | 99.000000 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
