

简介
在本教程中,我们将学习并实现Python Sklearn中的DBSCAN聚类的无监督学习算法。首先,我们将简要了解DBSCAN算法是如何工作的,以及一些关键的概念如epsilon(eps)、minPts、点的类型等。然后,我们将介绍一个Sklearn中的DBSCAN的例子,在那里我们还将看到如何找到最佳的epsilon值来创建良好的聚类。
1.什么是DBSCAN聚类算法?
DBSCAN是基于密度的噪声空间聚类算法。它属于无监督学习系列的聚类算法。
说到聚类,通常K-means或Hierarchical聚类算法更受欢迎。但是,它们只有在聚类简单的情况下才能很好地工作。当聚类具有复杂的形状或结构时,它们不会产生好的结果,这就是DBSCAN算法的优势所在。
DBSCAN是一种基于密度的聚类算法,它假定聚类是空间中的密集区域,被数据点密度较低的区域所分隔。在这里,"密集分组 "的数据点被合并为一个集群。我们可以通过观察数据点的局部密度来识别大数据集中的聚类。
DBSCAN聚类的一个独特的特点是它对异常值具有鲁棒性,因此它可以在异常检测系统中找到应用。此外,它不需要输入集群的数量,不像K-Means那样,我们必须手动指定中心点的数量。
DBSCAN算法的主要特点
- 它不需要输入聚类的数量。
- 它可以在寻找聚类的同时检测出离群值。
- DBSCAN算法可以检测到复杂的或随机形状和大小的集群。
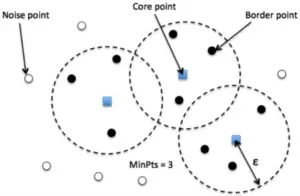
2.2.DBSCAN的先决概念DBSCAN的前提概念
i) Epsilon值(eps)
Epsilon是指围绕一个数据点的圆圈半径,这样所有落在圆圈内的其他数据点都被认为是邻居点。换句话说,如果两个点之间的距离小于或等于eps,就被认为是邻居。
如果eps值极小,那么大部分的点可能不在邻域内,将被视为离群值。这将导致糟糕的聚类,因为大多数的点不能满足创建密集区域所需的最小点数。
另一方面,如果选择了一个极高的值,那么大多数的数据点将保持在同一个簇中。这又会造成不好的聚类,由于epsilon的高值,多个聚类可能最终会合并。
理想情况下,我们必须根据数据集的距离来选择eps值(使用k-距离图),然而,通常小的eps值是首选。
ii) 最小点数 minPts
在DBSCAN中,minPts是定义聚类的区域中应该存在的最小数据点的数量。你可以根据你的领域知识来选择minPts的值。但如果你缺乏领域知识,一个好的参考点是minPts≥D+1,其中D是数据集的维度。
建议minPts的值至少保持在3,但是对于更大的数据集,应该选择更大的minPts值,尤其是当它有很多离群值的时候。
iii) DBSCAN聚类中的点的类型
基于以上两个参数,一个点可以被划分为。
-
核心点:核心点是指在其周围区域的半径eps内至少有minPts数量的点(包括该点本身)。
-
边界点:边界点是一个可以从核心点到达的点,在其周围区域内有少于minPts数量的点。
-
离群点:一个离群点既不是一个核心点,也不是可以从任何核心点到达的。
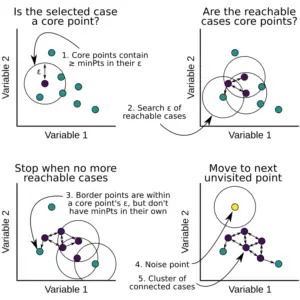
3.DBSCAN聚类算法
我们从数据点以及epsilon和minPts的值作为输入开始:
- 我们随机选择一个未被访问过的起始点。
- 用epsilon确定这个点的邻域,它基本上是一个半径。
- 如果附近的点满足minPts标准,那么这个点就被标记为核心点。聚类过程将开始,该点被标记为已被访问,否则该点被标记为噪音。
- 核心点附近的所有点也被标记为集群的一部分,上述步骤2对所有epsilon附近的点重复进行。
- 一个新的未访问的点被取来,按照上述步骤,它们要么被包括进来形成另一个集群,要么被标记为噪声。
- 上述过程一直持续到所有的点都被访问过为止。
4.Python Sklearn中的DBSCAN聚类的例子
Sklearn中的DBSCAN聚类可以通过使用sklearn.cluster模块的DBSCAN()函数轻松实现。我们将使用Sklearn的内置函数make_moons()为我们的DBSCAN例子生成一个数据集,这将在下一节解释。
导入库
首先,所需的sklearn库被导入,如下所示。
在[1]中:
import pandas as pd
import numpy as np
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score
from sklearn.metrics import v_measure_score
数据集
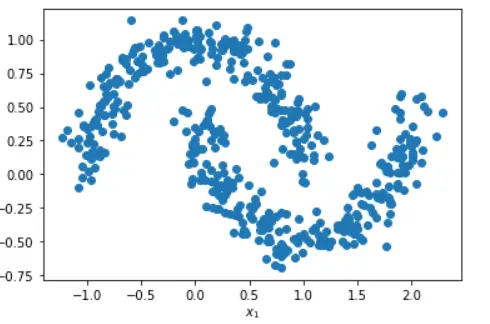
make_moons()函数用于二元分类,生成一个看起来像两个月亮的漩涡图案。生成月亮形状的噪声系数和样本数量可以在参数的帮助下进行控制。
这个生成的图案可以作为我们DBSCAN聚类例子的数据集。在下面的插图中,我们生成了一个具有适度噪声的月亮数据集。
下面,我们用make_moons()生成一个500个数据点的样本,噪声=0.1,然后用它来创建一个pandas DataFrame,看一下两列X1和X2。
In[2]:
X, y = make_moons(n_samples=500, noise=0.1)
df=pd.DataFrame(X,y)
df=df.rename(columns={0: "X1", 1:"X2"})
df.head()
Out[2]:
| X1 | X2 | |
|---|---|---|
| 1 | 2.032188 | 0.100502 |
| 0 | -0.976073 | 0.316752 |
| 1 | 2.029438 | 0.316930 |
| 0 | -0.931001 | 0.036861 |
| 0 | -0.371835 | 0.989145 |
在[3]:
plt.scatter(X[:, 0], X[:, 1], c=y, label=y)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
输出[3]:
Text(0, 0.5, '$x_2$')
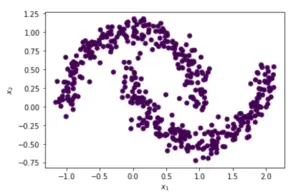
用默认参数应用Sklearn DBSCAN聚类法
在这个例子中,通过使用Sklearn DBSCAN聚类功能的默认参数,我们的算法无法找到不同的聚类,因此返回了一个零噪音点的单一聚类。
我们需要对这些参数进行微调,以创建不同的聚类。
在[4]:
dbscan_cluster1 = DBSCAN()
dbscan_cluster1.fit(X)
# Visualizing DBSCAN
plt.scatter(X[:, 0],
X[:, 1],
c=dbscan_cluster1.labels_,
label=y)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
# Number of Clusters
labels=dbscan_cluster1.labels_
N_clus=len(set(labels))-(1 if -1 in labels else 0)
print('Estimated no. of clusters: %d' % N_clus)
# Identify Noise
n_noise = list(dbscan_cluster1.labels_).count(-1)
print('Estimated no. of noise points: %d' % n_noise)
# Calculating v_measure
print('v_measure =', v_measure_score(y, labels))
输出[4]:
Estimated no. of clusters: 1
Estimated no. of noise points: 0
v_measure = 0.0
应用DBSCAN,eps = 0.1,min_samples = 8
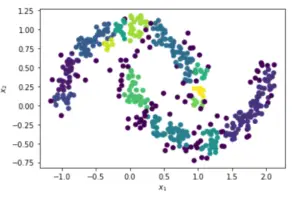
让我们任意选择DBSCAN()函数的参数值为eps=0.1和min_samples=8,可以看出这次的算法产生了太多的聚类。
它产生了14个聚类,并将88个点识别为噪声,v_measure_score为0.35。
在[7]:
dbscan_cluster = DBSCAN(eps=0.1, min_samples=8)
dbscan_cluster.fit(X)
# Visualizing DBSCAN
plt.scatter(X[:, 0],
X[:, 1],
c=dbscan_cluster.labels_,
label=y)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
# Number of Clusters
labels=dbscan_cluster.labels_
N_clus=len(set(labels))-(1 if -1 in labels else 0)
print('Estimated no. of clusters: %d' % N_clus)
# Identify Noise
n_noise = list(dbscan_cluster.labels_).count(-1)
print('Estimated no. of noise points: %d' % n_noise)
# Calculating v_measure
print('v_measure =', v_measure_score(y, labels))
Out[7]:
Estimated no. of clusters: 14
Estimated no. of noise points: 88
v_measure = 0.353411158836534
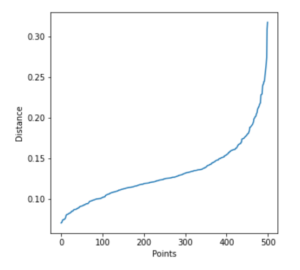
寻找Epsilon的最佳值
与其试验不同的epsilon值,我们可以使用肘点检测方法来得出一个合适的epsilon值。
在这种方法中,计算每个点和它的k个最近的邻居之间的平均距离,其中k=我们选择的MinPts。然后,我们将这些平均k距离按升序绘制在k距离图上。
epsilon的最佳值是具有最大曲率或弯曲的点,即在最大的斜率处。
让我们在下面实现这一技术并生成一个图形。
在[8]:
from sklearn.neighbors import NearestNeighbors
nearest_neighbors = NearestNeighbors(n_neighbors=11)
neighbors = nearest_neighbors.fit(df)
distances, indices = neighbors.kneighbors(df)
distances = np.sort(distances[:,10], axis=0)
fig = plt.figure(figsize=(5, 5))
plt.plot(distances)
plt.xlabel("Points")
plt.ylabel("Distance")
输出[8]:
Text(0, 0.5, 'Distance')
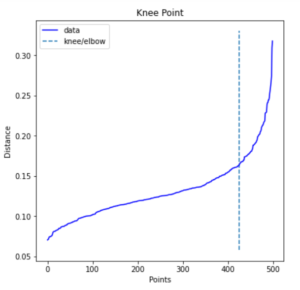
用Kneed包识别肘部点
要直观地确定最大曲率的位置是很困难的。因此,一个叫做kneed的Python包可以用来检测膝盖或肘部的点。这可以用 "*pip install kneed "*来安装。
使用下面的软件包,我们现在可以看到肘点位于0.163的值,这就是我们现在要使用的epsilon的最佳值。
In[9]:
from kneed import KneeLocator
i = np.arange(len(distances))
knee = KneeLocator(i, distances, S=1, curve='convex', direction='increasing', interp_method='polynomial')
fig = plt.figure(figsize=(5, 5))
knee.plot_knee()
plt.xlabel("Points")
plt.ylabel("Distance")
print(distances[knee.knee])
输出[9]:
0.16354673748319307
<Figure size 360x360 with 0 Axes>
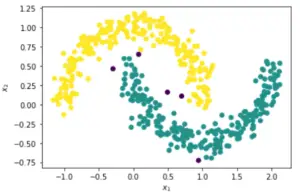
应用DBSCAN,最佳值Epsilon = 0.163
现在我们已经得出了上面的最佳ε值为0.163,让我们在下面的DBSCAN算法中使用它。
这一次很明显,DBSCAN聚类完成得很好,产生了两个聚类,只有5个噪声点。甚至v_measure_score的值也很好,达到了0.89
在[10]:
dbscan_cluster = DBSCAN(eps=0.163, min_samples=8)
dbscan_cluster.fit(X)
# Visualizing DBSCAN
plt.scatter(X[:, 0],
X[:, 1],
c=dbscan_cluster.labels_,
label=y)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
# Number of Clusters
labels=dbscan_cluster.labels_
N_clus=len(set(labels))-(1 if -1 in labels else 0)
print('Estimated no. of clusters: %d' % N_clus)
# Identify Noise
n_noise = list(dbscan_cluster.labels_).count(-1)
print('Estimated no. of noise points: %d' % n_noise)
# Calculating v_measure
print('v_measure =', v_measure_score(y, labels))
Out[10]:
Estimated no. of clusters: 2
Estimated no. of noise points: 5
v_measure = 0.8907602346423256
结论
我们希望你喜欢我们的教程,现在能更好地理解如何在Sklearn中实现DBSCAN聚类。在这里,我们展示了一个使用数据集进行聚类的端到端例子,也向你解释了如何找到最佳聚类结果的epsilon的最佳值。
参考文献:
