

SQL Server中的滞后函数是SQL Server 2012中引入的一个窗口函数。这个函数允许你按照指定的偏移值来获取前几行的数据。可以把滞后函数看作是从当前行访问前几行数据的能力。
例如,从当前行,你可以访问前一行,成为当前行,你可以访问前一行,以此类推。
在这篇文章中,我们将通过各种例子学习如何在SQL Server中使用滞后函数。
SQL Server LAG()函数
我们将该函数的语法表述为。
lag(expression, offset [,DEFAULT])
OVER (
[partition BY partition_by_expression]
order_by_clause
)
函数参数和返回值
在上面的语法中,我们有以下参数。
- Expression- 滞后函数用来进行计算的列或表达式。这是一个必要参数,表达式必须返回一个单一的值。
- Offset- 一个正整数值,定义滞后函数将检索多少行。如果没有指定,默认值被设置为1。
- Default- 如果指定的偏移值超出了分区的范围,指定了函数返回的默认值。默认情况下,该函数返回NULL。
- Partition_by_expression- 一个用于创建逻辑数据分区的表达式。SQL Server将对产生的分区集应用滞后函数。
- Order_by_clause- 一个表达式,用于定义如何对产生的分区中的行进行排序。
该函数返回标量表达式的数据类型。
SQL服务器滞后实例
让我们看一个实际的例子来更好地理解如何使用滞后函数。让我们从添加样本数据开始,如图所示。
CREATE DATABASE sampledb;
GO
USE sampledb;
CREATE TABLE lag_func(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
dbname VARCHAR(50),
paradigm VARCHAR(50),
);
INSERT INTO lag_func(dbname, paradigm)
VALUES ('MySQL', 'Relational'),
('MongoDB', 'Document'),
('Memcached', 'Key-Value Store'),
('Etcd', 'Key-Value Store'),
('Apache Cassandra', 'Wide Column'),
('CouchDB', 'Document'),
('PostgreSQL', 'Relational'),
('SQL Server', 'Relational'),
('neo4j', 'Graph'),
('Elasticsearch', 'Full-Text');
SELECT * FROM lag_func;
上面的查询集应该返回数据为。
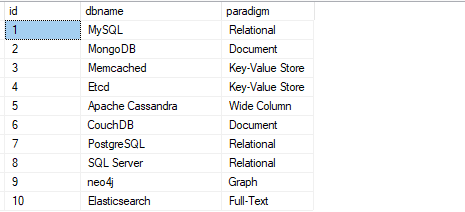
在dbname列上运行滞后函数,如下面的查询示例所示。
SELECT *, lag(dbname, 1) OVER (ORDER BY dbname) AS previous_db FROM lag_func;
上面的查询返回一个输出为。

注意,第一行包含一个空值,因为它没有前一个值。
例2:
我们可以设置一个缺省值,而不是得到一个空值,因为该行不包含以前的记录,如下面的查询示例所示。
SELECT dbname, lag(dbname, 1, 'N/A')
OVER (ORDER BY dbname) AS previous_db
FROM lag_func;
上面的查询返回与上面类似的输出。但是,我们得到的不是NULL,而是指定的字符串。

例3:自定义偏移值
我们也可以在一个自定义的偏移值上获取数值。例如,为了获取之前三条记录的值,我们可以使用这样的查询。
SELECT dbname, lag(dbname, 3, 'N/A')
OVER (ORDER BY dbname) AS previous_db
FROM lag_func;
上面的示例代码应该返回结果为。

这里,前3列是空的,因为偏移值超过了可用行的范围。
例子4:分区
我们可以使用partition by子句来创建相关数据的逻辑分区。然后我们可以对每个分区应用滞后函数。
请看下面的例子:
SELECT dbname, paradigm, lag(dbname, 1, 'N/A')
OVER (partition BY paradigm ORDER BY dbname) AS previous_db
FROM lag_func;
上面的查询返回一个示例查询集为。

该查询根据上述结果中的范式创建了6个分区。在每个分区中,滞后函数获取前一行。
总结
这篇文章教你如何使用SQL Server的滞后函数从结果集中获取前一行。
谢谢你的阅读!
