

堆栈分配是编译器的一种运行时存储管理机制,通过使用编译器中的预定义例程,在激活开始和结束时将激活记录推入和弹出到堆栈中。
目录。
- 简介。
- 激活树和记录。
- 变长数据的分配。
- 调用序列。
- 总结。
- 参考资料。
前提条件
介绍。
使用程序、函数或方法作为用户定义动作的单位的编译语言需要使用堆栈来管理它们的运行时内存。
当一个程序、函数或方法被调用时,其局部变量的空间被推到堆栈上。
激活树和记录。
一个程序可以被定义为一连串的指令,这些指令被组合成一些程序。
程序将有一个开始和结束的分隔符,程序内的一切都被称为程序的主体。
程序中的指令按顺序执行。
程序的执行被
称为
激活
,当激活发生时,会创建一个激活记录。
树。
一个激活记录将包含调用程序所需的所有信息。
激活记录中的信息
本地数据- 存储表达式的临时值和中间值,机器状态- 存储信息,如寄存器,程序计数器在程序被调用之前的状态。
控制链接- 存储调用程序的激活记录的地址。
访问链接- 存储本地范围之外的数据信息,
参数
- 存储参数,如调用程序的输入参数,为了提高效率,这些参数尽可能存储在寄存器中,
返回值
- 存储返回的程序的返回值,注意,寄存器存储是最好的效率。
控制堆栈存储已执行过程的激活记录。
当一个正在执行的过程调用另一个过程时,它的执行将被停止,直到被调用的过程完成其执行。被调用程序的激活记录也被存储在堆栈中。
程序的控制流是有顺序的,当一个过程被调用时,它的控制权被转移到被调用的过程中,而被调用的过程在执行时将控制权返回给调用者。
一个例子(quickSort)
int arr[11];
//read 9 integers into arr[1],...,arr[9]
void read(){
int i;
...
}
/* partitioning procedure - pick a pivot element v and partition arr[m,...,n] such that arr[m,...,p-1] are less that v, arr[p] = v and arr[p+1,...,n] are equal or greater than v. */
int partition(int m, int n){
return p;
}
void quickSort(int m, int n){
int i;
if(n > m){
i = partition(m, n);
quickSort(m, i-1);
quickSort(i+1, n);
}
}
main(){
read();
arr[0] = -9999;
arr[10] = 9999;
quickSort(1, 9);
}
上面的程序将九个整数读入一个数组,并使用递归的quickSort算法对它们进行排序。
主函数
。
- 调用read()。
- 设置哨兵。
- 在数组上调用快速排序算法。
为程序激活。
enter main()
enter read()
leave read()
enter quickSort(1, 9)
enter partition(1, 9)
leave partition(1, 9)
enter quickSort(1, 3)
...
leave quickSprt(1, 3)
enter quickSort(5, 9)
...
leave quickSort(5, 9)
leave quickSort(1, 9)
leave main()
对分区程序partition(1,9)的调用返回4,因此arr[1] - arr[3]将保存所有小于4的元素,arr[5]到arr[9]保存大于中枢4的元素。
程序的激活在时间上是嵌套的,也就是说,如果程序p的激活调用了程序q,那么q的激活必须在程序p的激活终止之前终止。
常见情况
- 当q的激活正常终止时,控制权在调用q的p点之后恢复。
- 对q的激活或直接或间接调用的过程q将中止,因为它变得不可能执行,因为p与q同时结束。
- 如果q不能处理一个异常,q的激活就会终止。也就是说,如果过程p处理了异常,q的激活就会终止,而p的激活不一定从对q的调用开始继续。
- 如果p不能处理异常,它的激活就会与q的激活同时终止,并且我们假定该异常将由其他开放的激活过程来处理。
这个控制流程使我们能够以树的形式来表示一系列的激活--激活树。
每个节点代表一个激活。
根节点是启动程序执行
的
主程序的激活。
节点的子节点代表被其父节点调用的激活。
激活的顺序是从左到右。
一个子节点必须在右边的激活开始之前完成。
激活树和程序行为之间的关系
- 程序调用的序列对应于激活树的前序遍历。
- 返回序列对应于后序激活树的遍历。
- 如果控制权在于节点N的一个程序的激活,那么该激活对所有相应的节点包括其祖先都是活的。这些激活被调用的顺序是沿着从根开始到N的路径出现的,它们以相反的顺序返回。
记录。
控制栈管理过程调用和返回。
每个活的激活将在控制栈上有一个激活记录/帧
。
激活树根在栈的底部,那么栈上对应于控制当前所在的树中路径的所有激活记录序列,其记录在栈的顶部。
考虑到上一节中的激活树图像,我们给出以下例子。
如果控制处于激活q(2,3),那么同样的激活记录在控制栈的顶部,下面是q(1,3)的激活记录,下面是q(1,9)的激活记录,最后是m的激活记录--代表主函数的树根。
**注意:**对于控制堆栈图像,在页面上出现的激活记录元素最低,最接近堆栈的顶部。
一个一般激活记录的例子
- 暂时的--是由表达式的评估产生的值,不能保存在寄存器中。
- 本地数据- 属于激活记录所属程序的数据。
- 其余的已经在上一节中描述过了。
当控制流经激活树时的运行时栈(quickSort)。
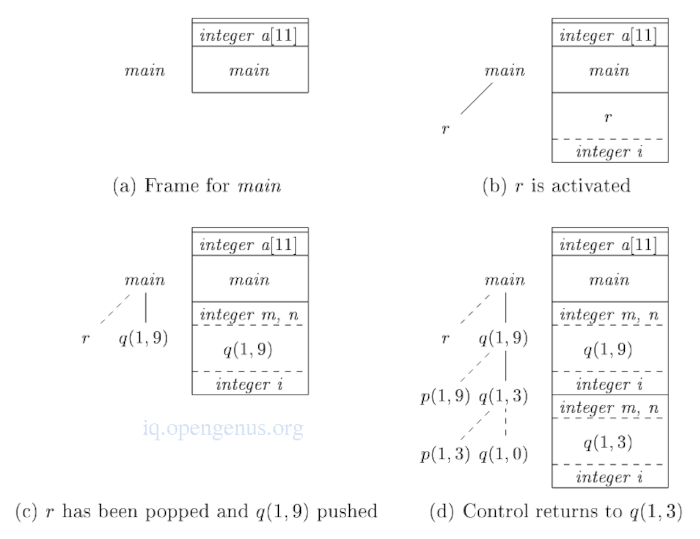
虚线代表终止的激活。
(a).数组a是全局的,因此它在执行激活程序main之前被分配了空间。
(b).当控制到达main主体的第一个调用时,过程r被激活,其激活记录被推到堆栈。
r的激活记录将包含本地变量i的空间。
当控制从r的激活中返回时,其记录被从堆栈中弹出,main的记录被留下。
控制现在在q处,实际参数为1,9,这个激活记录被放置到堆栈中。这个记录将包含参数m、n和局部变量i的空间,r调用所使用的空间在堆栈中被重新使用。
r
的
局部数据将不能
被
*q(1,9)使用。
当q(1,9)返回时,堆栈将再次拥有main的激活记录。
(d).激活p(1,3)和q(1,0)在q(1,3)的生命周期内开始和结束,这使得q(1,3)*的记录在上面。
变长数据的分配。
变长数据的一个例子是变长数组,其大小取决于被调用程序的一个或多个参数的值。
在这一节中,我们讨论如何在堆栈中分配大小未知的对象和其他结构。
这样做的原因是为了避免垃圾收集这一空间的费用。
分配可变长度的数组或任何可变长度的程序本地结构的策略。
程序p有三个局部数组,其大小在编译时无法确定。
这些数组的存储空间不是p的AR的一部分,即使它出现在堆栈中。
只有一个指向每个数组开始的指针出现在AR中,因此在p的执行过程中,这些指针与堆栈顶部指针的偏移量是已知的,目标代码能够通过这些指针(top和top_sp)访问数组元素。
top标记堆栈的顶部(下一个AR的开始)。
top_sp
找到顶部激活记录的局部固定长度域。
重置这两个指针的代码在编译时产生。
当q返回时,top_sp可以从q
的AR中保存的控制链接中恢复。
top的新值是top_sp减去机器状态、控制和访问链接、返回值和参数字段的长度。
这个长度在编译时被调用者知道,尽管它可能取决于调用者,因为参数的数量可以在对q
的
不同调用中变化。
调用序列。
调用序列由在堆栈上分配激活记录并在其字段中输入信息的代码组成。
它们被用来实现过程调用。
返回序列恢复机器的状态,这样调用序列就可以在调用后继续执行。
调用序列中的代码在调用者(调用过程)和被调用者(被调用过程)之间分配。
源语言、目标机器和操作系统可能会施加一些要求,这些要求可能有利于调用者或被调用者执行运行时任务,因此两者之间没有明确的任务划分。
也就是说,如果一个程序从n点被调用,那么分配给调用者的调用序列部分会产生n次,而被调用者序列的部分只产生一次。
最好是将大部分调用序列放到被调用者中。
调用者和被调用者之间的任务划分
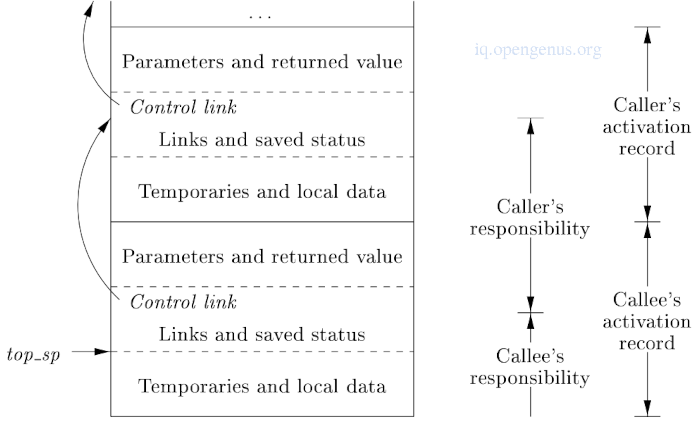
寄存器top_sp指向当前top AR中机器状态字段的末尾,由于这个位置对调用者来说是已知的,调用者负责在控制被传递给被调用者之前设置top_sp。
调用顺序和划分(调用者-被调用者)
- 调用者对参数进行评估。
- 调用者将返回地址和top_sp的旧值存储到被调用者的AR中,并增加top_sp(将它移过调用者的本地数据和临时数据以及被调用者的参数和状态域)。
- Callee保存寄存器的值和其他状态信息。
- Callee初始化其本地数据并开始执行。
相应的返回序列
- Callee将返回值放在参数旁边。
- Callee恢复top_sp和其他寄存器,然后分支到调用者放在状态字段的返回地址,所有这些都使用机器状态字段的信息。
- top_sp已经被递减,但调用者将知道返回值的位置,它是相对于top_sp的当前值而言的。
设计调用序列时要考虑的原则
-
在调用者和被调用者之间交流的值被放在被调用者激活记录的开头,以便它们尽可能地接近调用者的AR。
这是为了让调用者能够计算调用的实际参数值,并将它们放在自己的AR之上,以便不为被调用者创建新的AR。
这允许使用具有不同数量参数的程序。 -
固定长度的项目*(控制链路、访问链路、机器状态*)将被放置在中间。
理由是,如果每次调用都保存相同的机器状态组件,同样的代码可以为每个调用进行保存和恢复。
同时,这个标准允许其他程序,例如调试器在发生错误时轻松破译堆栈内容。 -
在执行前可能不知道其大小的项目,如动态数组,被放在AR的末尾,此外,临时变量所需的空间量取决于代码生成阶段在保持临时变量在寄存器中的成功。
因此,虽然临时变量所需的空间最终被编译器知道,但它可能在中间代码第一次生成时不知道。 -
我们明智地定位栈顶指针,让它指向AR中固定长度字段的末端。
固定长度的数据可以通过中间代码生成器知道的相对于栈顶指针的固定偏移量来访问。
这种方法的结果是激活记录中的可变长度字段实际上在栈顶之上。它们的偏移量需要在运行时计算,但它们也可以通过使用正偏移量从栈顶指针访问。
总结。
存储被组织成一个堆栈,也称为控制堆栈。
激活记录在激活开始时被推入堆栈,在激活结束时被弹出。
堆栈内存分配与堆内存分配相比更安全,也比后者更快。
堆栈溢出是当堆栈满时产生的错误。
参考文献.
- 编译器、原理、技术和工具,第二版 Alfred V. Aho, Monica S. Lam, Ravi Sethi, Jeffrey D. Ullman.
- 编译器设计的基础知识 Torben Ægidius Mogensen
