

在这篇文章中,我们已经解释了泡沫排序的基本原理,同时详细解释了Python在列表中实现泡沫排序的方法。
目录:
- 泡沫排序简介
- 泡沫排序的Python实现及解释
- 复杂度和运行时间
- 泡沫排序的应用
让我们开始在Python中实现列表中的泡沫排序。
泡泡排序简介
冒泡排序算法以正确的顺序对一个未排序的列表进行排序。它涉及到查看列表中两个相邻的元素,然后按正确的顺序交换它们。这个过程一直持续到列表的末尾,直到所有的元素都以正确的顺序结束。只有当相邻元素的顺序不正确时,才会发生元素的互换。在排序时,较大的数字向右冒泡,因此被称为冒泡排序。
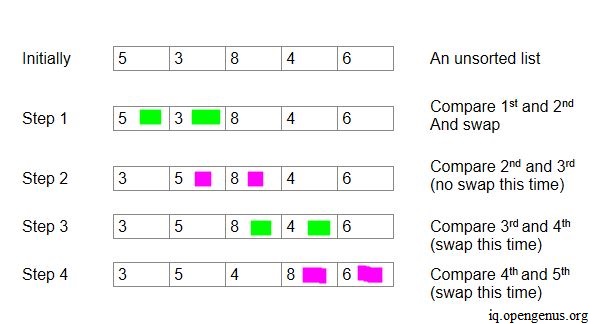
语法和流程
冒泡排序算法可以用for-loop轻松实现**。**实现需要以下步骤--
- 获取列表的长度(即列表中元素的数量)。让列表中的元素数为'n'。
- 遍历列表的'n'个次数,并创建一个变量来检查任何交换。每次都要遍历列表中的所有元素'n-i-1'次。这是因为在每次迭代中,最后一个元素总是以正确的顺序被设置。
- 当遍历所有元素时,每次都要检查当前元素是否比下一个元素大。如果是,就把它们交换。
- 如果没有发生互换,则退出循环。
- 打印最终排序的列表。
泡沫排序的Python实现及解释
下面的程序使用for-loop对一个未排序的列表进行排序,并打印出最终的输出:
# a function to sort a list using bubble sort algorithm
def bubblesort(lst):
# get the length of the list
n = len(lst)
# go through the list n number of times
for i in range(n):
# variable to keep check for any swaps
swap = False
# traverse through all adjacent elements
for j in range(0, n-i-1):
# if current element greater than next element, swap them
if lst[j]>lst[j+1]:
lst[j], lst[j+1] = lst[j+1], lst[j]
swap = True
# if no swaps, then break out of the loop
if swap == False:
break
# print the final sorted list
print(lst)
# an example unsorted list
y = [1,5,4,6,7,8,3,2,12,10,9,11]
# function call to sort list y
bubblesort(y)
-
首先,我们使用def语句创建一个名为 "bubblesort "的函数。每当我们需要在Python中为我们的程序创建一个自定义的函数时,就会用到这个语句。函数的名字可以是任何东西,但是'bubblesort'在这里是有意义的,因为重点是气泡排序算法。要创建一个函数,首先键入
def,后面是函数的首选名称。然后,在括号内,在函数定义中,我们传入参数,这是一个实际变量的别名,我们随后在函数调用中传入。把参数看作是临时变量,我们在函数中使用它来指定对实际变量进行的改变。这里的参数被命名为lst。 -
然后我们创建一个名为'n'的变量来存储列表的长度(列表中的项目数)。要在 Python 中得到一个列表的长度,键入
len并在括号内输入列表的名称。在这里,由于是一个函数定义,我们像以前一样传入临时变量,也就是名为lst的参数。 -
之后,我们使用一个for循环,对列表进行'n'次浏览。i的值范围从0到'n-1',因为范围关键字包括'n'以下的值,但不包括'n'。因此,对于'i'的所有值意味着从0开始,直到但不包括'n'的值。
-
然后我们创建一个名为
swap的变量,存储一个布尔值(即真或假)。我们以后使用这个变量来检查是否有任何交换发生。初始值被设置为False,这意味着到目前为止,还没有发生交换。 -
之后,我们创建另一个for循环,这次包含一个if语句,用于遍历所有相邻的元素,并检查当前元素是否大于下一个元素。if语句的条件
lst[j]>lst[j+1],总是返回一个布尔值(真或假),if语句中的代码只在该条件为真时运行。我们使用大于运算符>来检查这些值。当这个条件为真时,我们通过设置当前元素并将下一个元素的值赋给它来交换元素,反之亦然。由于lst是一个列表的别名,为了在列表内部查找,我们使用方括号[]。然后我们将swap变量设置为 True,意味着现在已经发生了交换。如果没有发生互换,swap变量就不会发生变化。 -
在我们走出第二个for循环后,我们检查是否有交换。为此,我们检查
swap变量。再次使用if语句和平等运算符==来检查任何交换。如果swap变量为False,这意味着没有交换,因此,我们使用break语句跳出整个主for循环。每当我们想脱离 Python 中的任何循环时,我们都会使用这个语句。 -
在走出最后的for循环后,我们使用
print()函数,并传入参数lst,以打印出最后的排序列表。同样,由于这是一个函数定义,我们使用临时变量,也就是名为lst的参数。 -
在上面的例子中,我们使用一个名为
y的列表来测试我们的 bubblesort 函数。这个列表有12个元素。为了使用该函数(或者用正式术语说,调用该函数),我们输入该函数的名称,后面是括号,在括号内,我们传入我们想要排序的列表的名称。
运行上述程序可以得到以下输出:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
复杂度和运行时间
-
大O记号:在最坏的情况下,冒泡排序算法的运行时间为n平方。这是因为,在最多的情况下,我们要对未排序的列表进行'n'次处理,并对所有元素进行'n-i-1'次的遍历。随着'n'越来越大,我们倾向于忽略常数。所以最后,算法所经历的总步数是(n)x(n),即n的平方。
-
Big-Omega符号:在最好的情况下,冒泡排序算法的运行时间为'n'。这是因为,最低限度,即使列表中的所有元素都被排序了,我们仍然要对列表进行一次检查。
气泡排序的应用
-
泡沫排序是一种算法,它可以检测出没有完全排序的数组/列表中即使是很小的错误。这在计算机图形学中得到了应用。
-
在极小的数据集上,泡沫排序算法在时间复杂度方面比选择排序更好。
问题
泡沫排序中的泡沫意味着什么?
大的数字向右排序
小数字向左冒泡
这些数字在排序时,会像气泡一样以正确的顺序排序。
小数字向右排序
大的数字在排序时向右冒泡,因此被称为气泡排序。
