

在这篇文章中,我们将学习为什么降维很重要以及5种不同类型的降维技术,如主成分分析、缺失值比率、随机森林、后向消除和前向选择。
目录:
-
简介
-
什么是维度?
-
什么是降维?
-
我们为什么需要降维?
-
降维技术的类型
5.1.主成分分析
5.2.缺失值比率
5.3.随机森林
5.4 . 后向消除
5.5.前向选择
让我们开始了解降维技术的类型。
简介
你是否曾经处理过一个包含数万个特征的数据集?想想看,用这么多的属性来创建机器学习模型会有多大的挑战,如果我们能把不需要的特征去掉,那将是多么容易的事情啊
在继续之前,让我们先回答一个问题,什么是维度?
维度是指数据集中的列、输入特征、属性和变量的数量。例如,考虑一个简单的学生数据集,有两个特征。现在,这是一个二维数据集,如果我们添加第三个特征,如身高,这将成为一个三维数据集。
基本上,简而言之,一个数据集中的特征数量被称为维度。
什么是降维?
所以,现在你已经了解了什么是维度,不需要花太多时间去猜测,维度降低是什么意思,是的,它意味着从数据集中去除特征。
减少数据集中的输入特征以简化程序被称为 "降维"。
但是,等等,从我们的数据集中删除特征不会对我们的机器学习模型产生不利的影响吗?正如我们所听到的,拥有大量的数据/输入特征有助于创建良好的预测,这难道不是真的吗?移除特征不会影响?
现在,这给我们带来了。
为什么我们需要降低维度以及它的重要性?
到目前为止,我们所学到的是降维意味着减少输入特征,但没有人告诉我们许多输入特征的问题是什么?让我们来回答这个问题:
- 机器学习算法会因为有太多的输入特征而受到影响
--太多的输入特征会占用大量的空间
--太多的输入变量会带来诅咒,也就是维度的诅咒。
那么,它的优势是什么,我们为什么需要它?
- 数据集特征的降维有助于数据的可视化
- 数据的维数越低,意味着训练时间和计算机资源越少,从而提高机器学习算法的整体性能
- 通过删除重复的特征来解决多重共线性
- 当数据中有许多特征时,模型倾向于过度拟合,降维有助于避免过度拟合的问题
现在,既然我们已经了解了什么是维度,降维是什么意思,降维的优势是什么,让我们来看看各种降维技术。
降维技术的类型
我们将介绍5种不同的降维技术:
- 主成分分析
- 缺失值比率
- 随机森林
- 后向消除
- 前向选择
1.主成分分析
主成分分析是一种从大型数据集中提取新变量的方法。通过使用正交变换,主成分分析将相关的特征观测值变成一组统计上独立的特征。这些新提取的变量/特征被称为主成分。主成分分析是一种无监督的机器学习算法,用于降维。
它总是在对称的相关或协方差矩阵上实施,这意味着矩阵应该是数字的,并且包含标准化的数据。
基本上,PCA是一种可视化和预处理高维数据的典型方法。通过保留尽可能多的方差,PCA降低了数据收集的维度(变量的数量)。
关于主成分分析的一些关键点:
- 原始变量的线性组合被称为主成分。
- 第一个主成分的提取方式是解释数据集中的最大变化。
- 第二个主成分与第一个主成分无关,试图解释数据集中的剩余变化。
- 第三个原则成分试图解释前两个主成分未能解释的变化,以此类推。
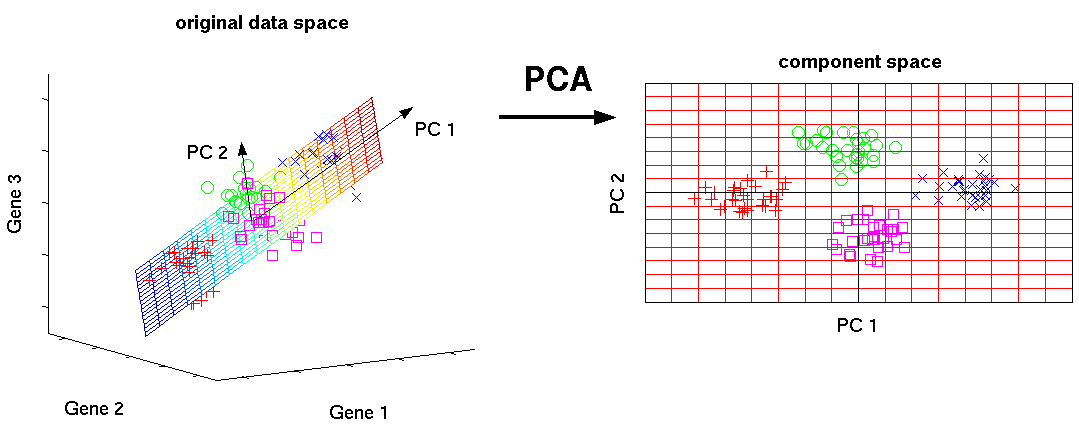
下面的图形描述了PCA如何用于将高维数据(3维)变成低维数据(2维):
2.2.缺失值比率
创建机器学习模型的第一步是分析现有数据。如果我们得到一个包含大量缺失值/数据的数据集,我们应该怎么做?我们的ML模型将受到缺失值的影响。所以,你可以放弃这一列,或者填补缺失的数据。我们应该如何确定是消除该列还是填补缺失值?嗯,这完全取决于该列的相关性,以及我们的预测是否会需要它。然而,我使用的是50%的规则,即如果超过一半的数值缺失,则放弃该项目。
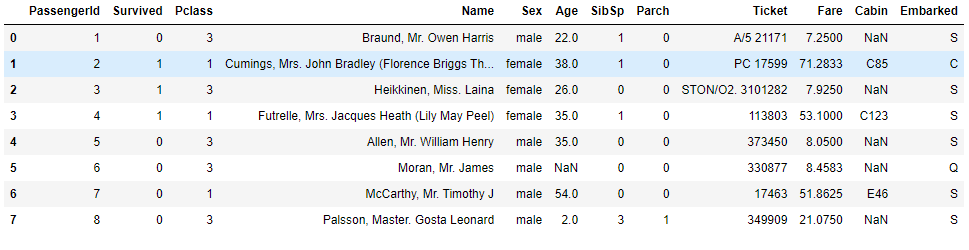
让我们通过一个例子来理解这一点,让我们采取非常著名的泰坦尼克号生存预测数据集:
Import pandas as pd
titanic_train = pd.read_csv(‘train.csv’)
titanic_train.head(8)
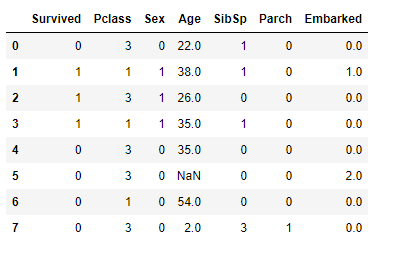
一旦我们调用上述代码,数据集就会显示出来:
我们可以看到,上述数据集有12列,现在让我们来寻找缺失的值,我们用isnull()和sum()来做:
titanic_data.isnull().sum()
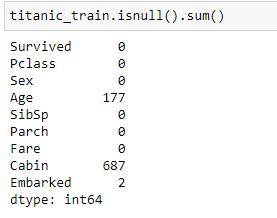
我们可以清楚地确定,年龄列有177个空值,机舱列有687个空值,登机列有2个空值。
现在,让我们想想,我们的预测需要这三列吗?年龄列很重要,但我们需要机舱列吗?它不是那么重要,而且它有687个缺失值,如果我们放弃它就完全可以了。
titanic_train.drop(‘cabin’,axis=1)
现在,让我们来处理年龄列和登机列的缺失值,我们可以做的是用年龄列的平均值来填补缺失值。这就是我们的做法:
titanic_train[‘Age’].mean()
titanic_train[‘Age’].fillna(titanic_train[‘Age’].mean(),inplace = True)
现在我们来填补Embarked列的缺失值
titanic_data['Embarked'].fillna(titanic_data['Embarked'].mode()[0], inplace=True)
我们所做的是用模式值替换 "登船 "列中的缺失值。
现在我们的数据集已经准备好了,没有缺失值。
3.随机森林
最著名和最合适的特征选择技术之一是随机森林。这是一个基于树的模型,经常被用于非线性数据回归和分类。它已经带有内置的特征重要性,所以我们不需要单独编程。然而,我们必须在这个算法中只使用数字值,因为它只接受数字值。
让我们使用泰坦尼克数据集来实现随机森林算法。
前面我们处理了缺失值,现在,让我们在转向实现随机森林之前处理一下非数字值。
让我们再看一次数据集:
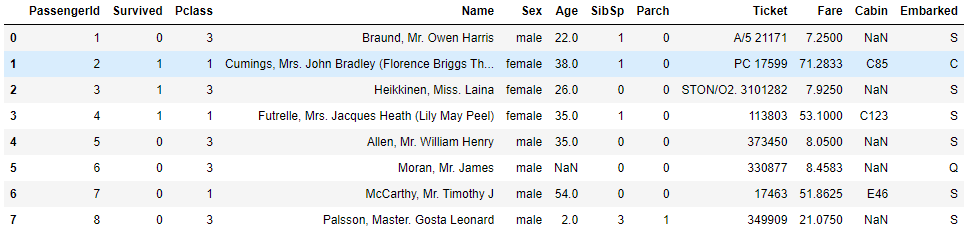
在继续之前,让我们明确一下,姓名、车票、车费、车厢这几列对我们的预测没有用处。
我们可以看到,"性别 "和 "登船 "列属于非数字类型。让我们把它们转换为数字值。我们将在性别栏中用0替换男性,用1替换女性;对于Embarked栏,我们将用0替换S,用1替换C,用2替换Q。
titanic_data.replace({'Sex':{'male':0,'female':1},
'Embarked':{'S':0,'C':1,'Q':2}}, inplace=True)
再看一下数据集,你会发现性别和Embarked列有数字值。我们也删除了那些不需要的列:
现在我们需要将数据集分成训练和测试两部分。
From sklearn.model_selection import train_test_split
X_train = titanic_train.drop("Survived", axis=1)
Y_train = titanic_train["Survived"]
随机森林模型:
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_prediction = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
4.后向特征消除
在这个技术中,我们使用递归特征消除程序来删除数据集中的特征。该方法最初尝试在数据集的初始特征集上训练模型,然后计算模型性能。然后,该方法每次删除一个因素,在剩下的特征上训练模型,并计算性能分数。
步骤:
我们从数据集中的所有n个变量开始,并利用它们来训练模型,
然后检查模型的性能,现在我们将逐一消除特征,并在计算模型的性能之前对n-1个特征训练n次。
- 我们重复这个过程,直到没有变量可以被删除。
这种技术主要用于建立线性回归或逻辑回归模型
递归特征消除的实现:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from yellowbrick.model_selection import feature_importances
iris = load_iris()
data = iris.data
target = iris.target
model = LogisticRegression(max_iter=150)
selector = RFE(model, n_features_to_select=3, step=1)
selector.fit(data, target)
X_selected = selector.transform(data)
print('Initial features')
print(pd.DataFrame(data, columns=iris.feature_names).head())
print()
print('Selected features')
print(pd.DataFrame(X_selected).head())
print()
print(feature_importances(model, data, target, stack=True,
labels=iris.feature_names, relative=False))
让我们来看看输出结果:
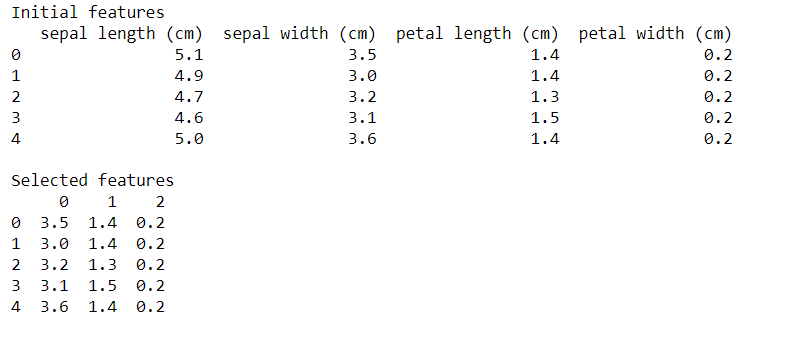
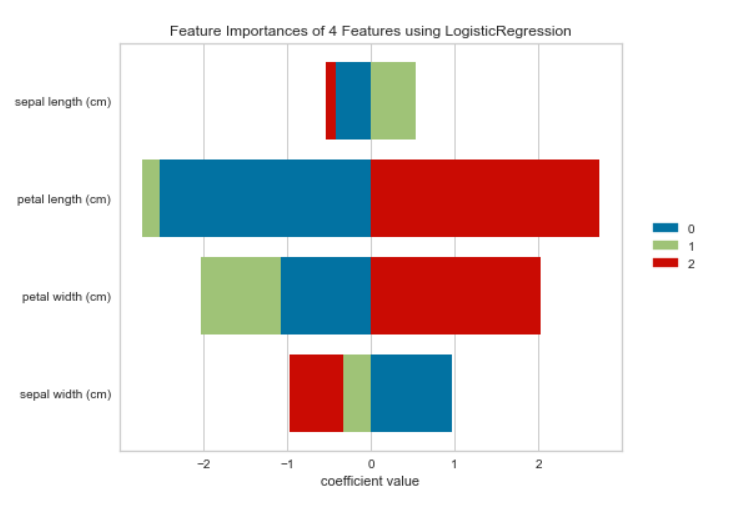
递归特征消除(RFE)技术已经从逻辑回归模型中删除了花叶长度(萼片长度),在输出中可以看到。萼片的长度是最不重要的特征/特性。
5.5.正向特征消除
前向特征消除法与后向特征消除法相反,我们寻找并找到有助于提高模型性能的最佳特征。
步骤:
- 我们从一个特征开始。实质上,我们用每个特征单独训练模型n次。
- 选择性能最好的变量作为初始变量
- 然后继续循环,每次增加一个新变量。
该方法将继续进行,直到模型的性能得到明显改善。
实施:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.feature_selection import f_classif
from sklearn.feature_selection import SelectKBest
iris = load_iris()
data = iris.data
target = iris.target
X_selected = SelectKBest(f_classif, k=3).fit_transform(data, target)
print('F-values: ', f_classif(data,target)[0])
print()
print('Initial features')
print(pd.DataFrame(data, columns=iris.feature_names).head())
print()
print('Selected features')
print(pd.DataFrame(X_selected).head())
让我们检查一下以下代码的输出:
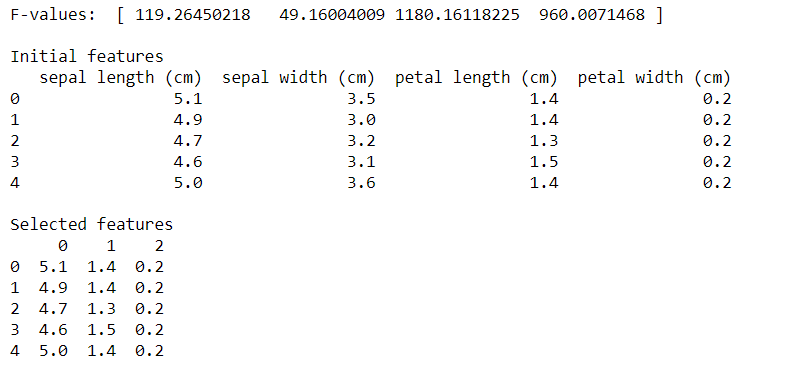
正向特征选择程序挑选了具有较高F值的萼片长度、花瓣长度和花瓣宽度,如输出中所示。
通过OpenGenus的这篇文章,你一定对降维技术的类型有了完整的了解。
