

你如何连续实时处理半兆字节的数据?这正是我们必须回答的问题。
Leadnomics是一家数字营销公司,帮助公司最大限度地提高他们的线索、注册、销售、应用安装或任何其他对发展品牌至关重要的行动。我们的组织每天筛选数以千计的线索,并根据地理、人口和心理学属性,智能地将理想的寻求者和提供者配对给代理商、运营商、广告商和出版商。为了给我们的客户提供更好的体验,我们的任务是建立Leadnomics Edge:我们的联盟和线索管理平台,该平台将跟踪线索并管理渠道内的联盟,以更好地促进我们客户的品牌增长。就像任何好的探索一样,我们被赋予了许多主要的要求,但有一个特别重要的要求:强大的报告,可以处理半兆字节的数据,尽可能的接近实时。
我们的探索从一个主要障碍开始。我们原来的技术合作伙伴,其实时SaaS营销平台应该是Leadnomics Edge的骨干,刚刚遭遇了重大的安全漏洞。因此,我们决定从头开始建立一个全新的平台,只有一个四人团队--后端工程师(我)、前端工程师、产品经理/质量管理员和我们的首席运营官。我们开始工作,建立一个具有实时报告功能的安全平台。
一个要求来统治他们所有人
一个 "请求",就Leadnomics Edge而言,基本上是代表用户是谁以及他们已经做了什么或正在做什么的会话数据。我们有两个 "版本 "的请求:一个是构成请求的每个事件的历史时间线,一个是完整的 "合并 "对象。"请求 "是最好的术语吗?可能不是。我们是否花了更多的时间去想该怎么称呼它,而不是去构建它?我永远不会知道。让我们来看看这在实践中意味着什么。
请求的 "历史 "示例:
{
"id": "abc123",
"source": 2,
"ipaddress": "123.456.1234",
"useragent": "Chrome",
"domain": "somewhere.net",
"clicks": "+1",
"impressions": "+5",
"price": 2.45
}
--- X minutes later
{
"id": "abc123",
"clicks": "+3",
"impressions": "+2"
}
--- X minutes Later
{
"id": "abc123",
"impressions": "+2",
"uptick": 4.50
}
合并 "请求的例子:
{
"id": "abc123",
"source": 2,
"created_at": FIRST_TIMESTAMP,
"updated_at": LAST_TIMESTAMP
"ipaddress": "123.456.1234",
"geo":{
...geolocationdata
}
"useragent": "Chrome",
"UA": {
...Data derived from UA parsing
},
"domain": "somewhere.net",
"clicks": 4,
"impressions": 9,
"price": 2.45,
"uptick": 4.50,
}
这是一个非常简单的例子,但它说明了请求合并中最常见的三个过程:处理某些字段的元数据(例如来自ipaddress 的地理位置),字段增量,以及对象合并。我们的目标是将这些请求流,按其ID分组,然后将它们送去合并和存储。那么,我们从哪里开始呢?
生命、自由和对数据合并的追求
我们第一次尝试使用AWS SQS、PostgreSQL数据库和Elasticsearch。我们这样做的理由主要是基于我们对这些工具的经验、熟悉程度和以前的成功。每个请求都被推入队列,在那里被一个工人拾起,储存在Postgres数据库中。之后,第二个工作者从数据库中读取,按ID对请求进行分组,并执行合并和加载到Elasticsearch。
我看到你们这些人在后面高举双手,一遍又一遍地念叨着 "规模 "这个词。把你的手放下,不要再往前跳了,虽然你是对的。
这种方法在一段时间内运作得相当好,使我们的平均报告延迟约为2分钟。不是很理想,但领先于我们的很多竞争对手!"。
哈利-波特和着火的数据库
生活是美好的,鸟儿在歌唱,天气总是清爽的70度(除了像《辛普森一家》中的那一集那样下着甜甜圈的时候)。
然后规模发生了。

源于此:"The IT Crowd"
一些更有经验的开发者在阅读这篇文章时可能已经看到了这一点(并且从上一节开始就对我大喊大叫)。这没关系。继续嚷嚷吧,我仍然爱你。我们会一起解决这个问题的。
随着我们的流量开始扩大,我们的基础设施开始瘫痪,我们的报告延迟开始增加。3分钟,5分钟,15分钟,30分钟。
我们在这里的主要痛点是数据库。随着表的增长,请求的数量也在增加,单个请求的大小也在增加,而查询时间也在不断增长。我们通过Elasticsearch获得了所有需要的信息,但它的加载速度却没有我们想要的那么快。排队的不眠之夜,我们试图扑灭数据库的火。
表的优化、查询的调整和数据库的扩展都有帮助,但也感觉像是创可贴,而且不是很酷的《星球大战》,只是普通的创可贴。我们需要一个新的解决方案,而我需要一个理由来停止在凌晨2点调整数据库配置的工作。
ksqlDB如何拯救我的睡眠时间
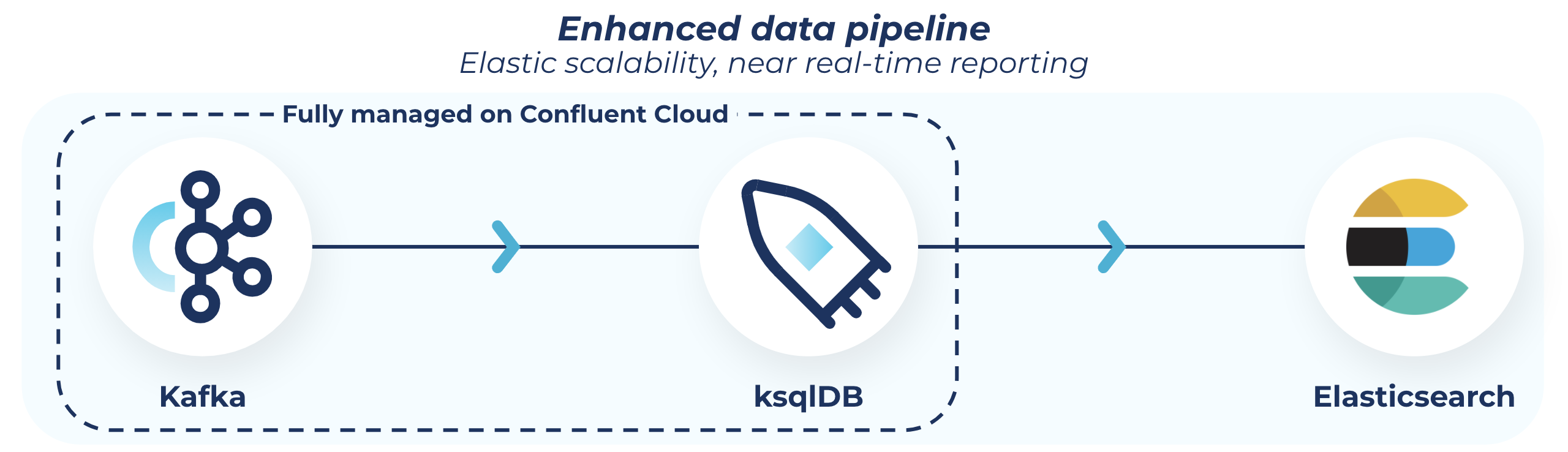
在我们的作战室(Slack频道)讨论了很久之后,我们找到了新的解决方案:我们将用Apache Kafka®和ksqlDB分别取代SQS和PostgreSQL。我们在以前的公司使用Kafka来管理我们的大部分日志,取得了很大的成功。这一点,再加上我们对ksqlDB的初步了解,推动了我们的最终决定。说实话,我们以前在Leadnomics从来没有使用过Kafka,但是我们从我们姐妹公司的一个开发人员那里听说了这个技术的好处。所以我做了一些研究,发现了Confluent Cloud,它可以让我们利用Kafka的所有功能,但没有任何运营开销。我开始玩Confluent和ksqlDB,看看它是否能做到它所宣传的那样。事实证明,它做到了
我们的队列被Confluent Cloud上的一个Kafka主题所取代。Kafka节点模块让这个交换变得非常简单。
现在,我们的请求已经流经我们的Kafka主题,我们还有两件事要做。将数据推送到存储区,并将数据推送到我们的报告中进行合并和发布。同样,请记住,这一切都在Confluent Cloud上完成,使这一过程变得非常简单。
第一步是非常简单的。我们将数据从Kafka主题推送到S3的汇中,按ID存储。
接下来,我们按ID对请求进行分组,并将其发送给我们的工作者。 ksqlDB通过一个类似于SQL的界面,让这一切变得轻而易举。(你认为这就是他们叫它ksqlDB的原因吗?聪明伶俐。)另外,你真正需要知道的是SQL,这使得学习该产品非常简单。还有一点也不坏,那里有相当多的文档。我所需要做的就是写一个查询并学习新的语法。
下面是我们使用的一个ksqlDB查询的例子:
CREATE TABLE EDGE_REQUESTS_GROUPED WITH (KAFKA_TOPIC='', PARTITIONS=, REPLICAS=) AS
SELECT
EDGE_REQUESTS.ID CLIENT_REQUEST_ID,
COLLECT_LIST(EDGE_REQUESTS.REQUESTS) REQS
FROM EDGE_REQUESTS EDGE_REQUESTS
GROUP BY EDGE_REQUESTS.ID
EMIT CHANGES;
一旦我们的查询开始运行,我们就把我们的工作者连接到我们的集群上(同样,这个模块让这一切变得很顺利),开始我们的合并,并发布到Elasticsearch。
好了,现在让我们看一下我们的报告延迟。我们是否已经回到了2分钟的基准值?
报告延迟:10秒。
那么是什么改变了呢? ksqlDB改变了我们滚动请求的方式。以前,我们使用Postgres,查询需要20-30秒。ksqlDB允许我们即时进行这些滚动。因此,有了Postgres DB,我们扔掉了一整层的硬件(我们知道这总是好的)。瞧,这就是我们的优势。独立请求和分组请求之间的延迟变成了一个非因素。如果没有ksqlDB,我们的平台可能会有10-15分钟的延迟。现在,它是真正的实时的。

结果如何?安全的平台,对。实时报告,检查。探索完成,任务完成。简而言之,ksqlDB是我们需要的魔法。
多亏了ksqlDB和Confluent Cloud,我们降低了延迟,甚至超过了我们最初的最佳预期。另外,我们在短短八个月内就推出了整个新的平台,而我们的团队只有四个人。现在,我们有快乐的客户、快乐的老板和休息良好的工程师。谢谢你,ksqlDB!我会在晚上睡觉的时候梦到你。下一个追求,是如何利用ksqlDB和Confluent Cloud来实现我们的机器学习用例。
