

在实时数据上的机器学习是一个强大的组合,因为你可以直接洞察你的数据,可以做出强有力的决策,并因此改善你的业务流程和结果。重要的是要知道如何在你的运行系统中实现统计模型,以及如何处理数据值的变化和预测结果的减少。
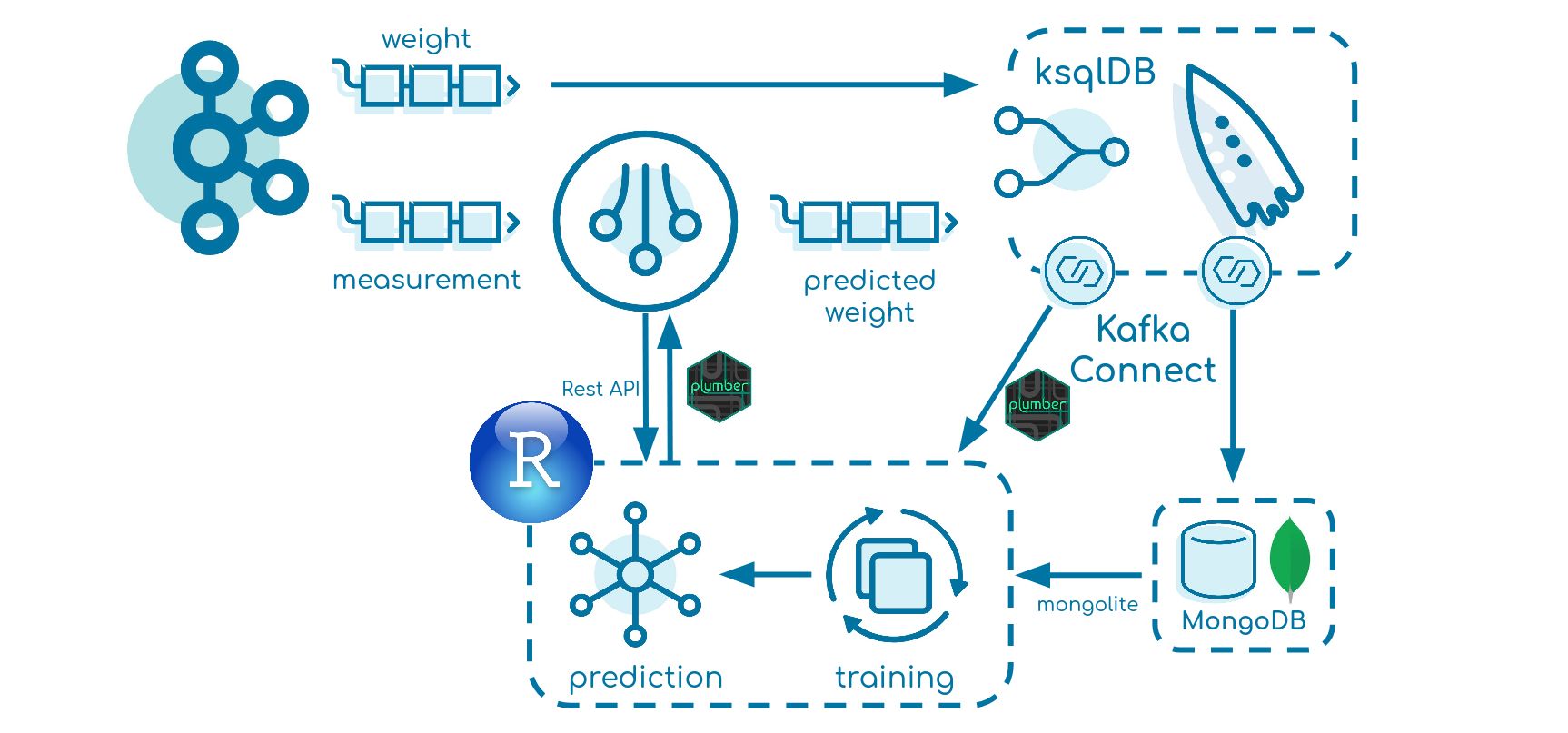
这篇博文创建了一个数据管道,其中应用了机器学习模型,一旦预测结果超过某个阈值,还会自动重新训练。模拟数据被用来强调数据流的某些关键特征。更具体地说,一个Kafka Streams应用程序(用Kotlin实现)将向模型发送HTTP请求(使用plumber包在R中实现),并将预测结果产生到一个汇流主题。最后,ksqlDB以及MongoDB连接器和HTTP Sink连接器被用来存储数据并触发再训练过程。
本教程通过构建,也谈到了测试关键的实现方式。此外,整体的管道性能扫描,以及对缺点和限制的洞察,也是对本文的补充。
注意,这篇文章并不关注数据科学本身,如选择和优化统计模型。总体目标是将模型转移到运行的系统中,注重简单性,以便将指南作为一个基础。关于优化的后续文章计划在未来发布。
本文中使用的所有代码都可以在GitHub上找到:
模拟的商业案例
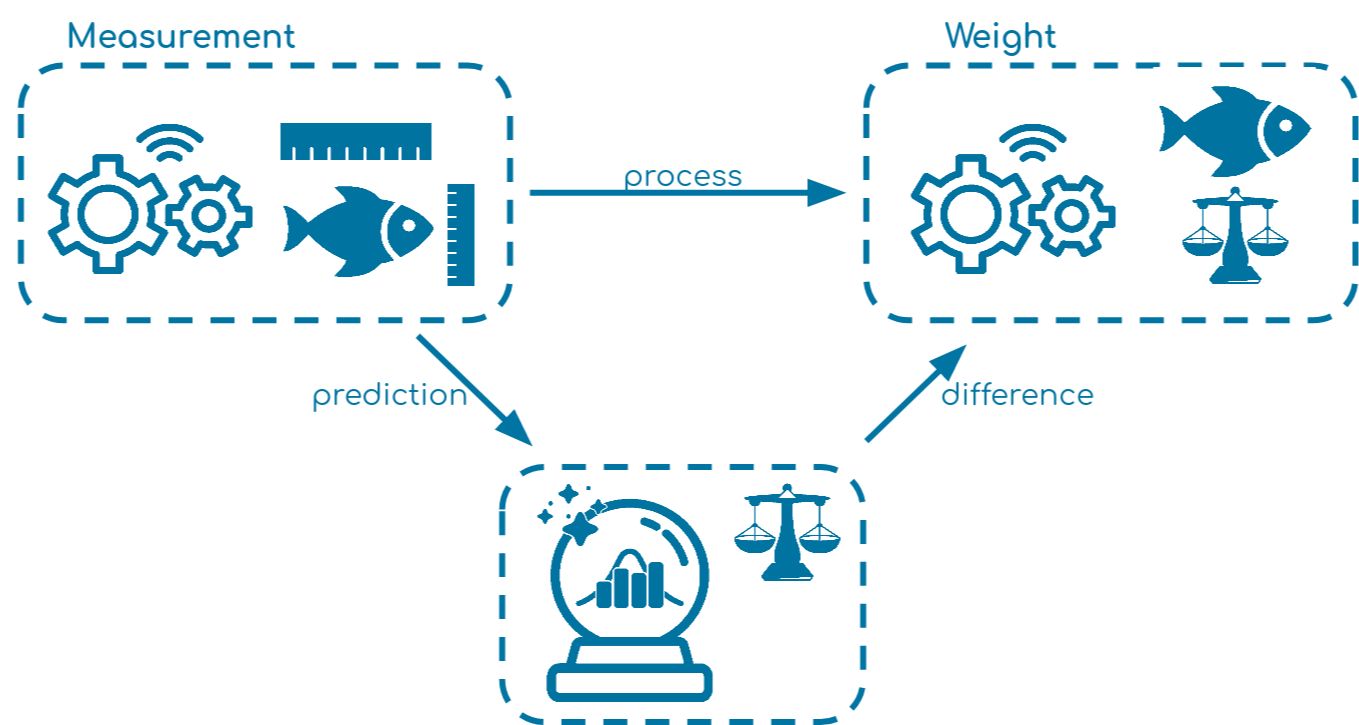
生成的例子使用了一个鱼类加工的工厂。在第一步,测量鱼的尺寸(长度和高度)。在这个过程的后期,鱼也被称重以计算肉的数量,最后确定价格。
据推测,鱼的大小可能对重量有影响--越大越重--所以直接对重量进行近似计算是非常好的,这样我们就可以提前告诉客户接下来的收费可能是什么。
Dimensions.com提供了许多物种的鱼的信息,所以我们可以模拟出一个有高度、长度和重量的100条鲑鱼的数据集。这些数据被用来训练一个简单的线性回归模型,命令是lm(weight ~ length + height, data = data) 。该模型本身是显著的,可以解释83%的数据变异。通过命令save(data = lm, file = "model.RData") ,数据被保存起来,以便以后在我们的管道中使用。分析结果可以在文件Model.R 中找到。
模拟的物联网设备
两个代表这两台机器的Kafka生产者每两秒连续向主题machine-measurement 和machine-weight 发送数据,格式为JSON 。测量和重量的事件是这样的:
{
"Species": "salmon",
"Fish_Id": "1",
"Length": 86.370,
"Height": 18.740
}
{
"Species": "salmon",
"Fish_Id": "1",
"Weight": 4.43990
}
重量生产者以10秒的延迟发送其数据,以模拟连续的过程。
模型API
RStudio被用来应用和重新训练模型。这两个功能都可以在文件Predictor.R 。为了创建一个API,我们使用plumber包,并在main.R 中定义其端口和主机:
library(plumber)
api <- plumb("/home/Predictor.R")
api$run(port=8000, host="0.0.0.0")
有几篇关于用plumber包创建API和用Docker运行它的文章,包括R can API and So Can You!和Using docker to deploy an R plumber API,由Heather Nolis和Jacqueline Nolis撰写。
预测功能
对于预测,我们定义一个GET request ,有length ,weight ,和species 作为参数:
#' @param length
#' @param height
#' @param species
#' @serializer unboxedJSON
#' @get /prediction
predictWeight <- function(length, height, species){
tryCatch(
{
length <- as.numeric(length)
height <- as.numeric(height)
species <- as.factor(species)
load("/home/model.RData")
prediction <- predict(lm, data.frame(length = length, height = height, species = species))
return(list(Weight = prediction, ModelTime = lm$time))
},
error = function(cond){
message("Prediction did not work")
return(NA)
}
)
}
我们传输输入参数,应用训练好的线性回归模型,并将预测结果作为JSON对象返回:
{
"Weight": 3.6789,
"ModelTime": "2021-06-02 07:48:52"
}
再培训功能
我们定义一个POST request 来重新训练模型。
#' @post /train
train <- function(){
library(mongolite)
library(dplyr)
tryCatch({
connection <- mongo(collection = "TrainingData",
db = "Weight",
url = "mongodb://user:password@mongo:27017")
dataAggr <- connection$aggregate('[
{"$sort": {"Timestamp": -1}},
{"$limit": 50}]')
data <- dataAggr %>% select(length = Length, height = Height, weight = ActualWeight, species = Species)
if(length(unique(data$species)) > 1){
data$species <- as.factor(data$species)
lm <- lm(weight ~ length + height + species, data = data)
} else {
lm <- lm(weight ~ length + height , data = data)
}
lm$time <- Sys.time()
save(data = lm, file = "/home/model.RData")
message("New model saved")
},
error = function(cond){
message ("Retraining did not work")
}
)
}
使用mongolite包以及dplyr包,我们首先从MongoDB中请求最后的50个数据点,然后将它们转移到我们想要的形式。在之前的文章《用Apache Kafka和RStudio创建数据分析管道》中,我们使用Kafka Connect和MongoDB从Apache Kafka®创建了一个数据管道进入R。随后,我们以物种数量为条件应用我们的模型,并保存它。
测试
为了测试API是否按预期工作,我们在目录/R/test 中运行一个docker-compose文件。这个文件启动了管道工API,一个MongoDB容器,并将数据插入数据库中。在http://127.0.0.1:8000/__docs__/,你可以找到一个交互式的Swagger页面,在上面你可以直接测试你的API。在这个运行的例子中,测试了以下行为。
GET request测试预测是否在一般情况下有效 ✔ 重新训练模型POST request重新训练模型 ✔GET request测试模型的时间是否因为重新训练而发生变化 ✔ 测试模型的时间。

即使我们在集成测试中测试我们的API,我们也需要考虑单元测试。本教程省略了这一步,但你可以参考testthat包以及André Müller的文章《R中的单元测试》,其中对R中的单元测试有很好的解释。
实时预测
对于预测,我们使用Kafka Streams2.8.0版本在Kotlin中实现了一个Kafka Streams应用程序。该应用程序具有以下属性:
BOOTSTRAP_SERVERS_CONFIG: “broker:29092”,
APPLICATION_ID_CONFIG: “streamsId”,
MODEL_URL: “http://rstudio:8000/prediction”
我们只需设置强制性的配置参数,并指定模型的URL。在这一点上,我们在这里只关注拓扑结构以及与RStudio中的模型的交互,因为这是主要的兴趣所在。对于Kafka事件的序列化和反序列化,我们使用Klaxon库实现了一个定制的FishSerde 。
拓扑结构
class StreamProcessor(properties: StreamProperties, private val predictor: Predictor) {
val streams = KafkaStreams(createTopology(), properties.configureProperties())
fun createTopology(): Topology {
val processor = StreamsBuilder()
processor
.stream(
"machine-measurement",
Consumed.with(Serdes.String(), FishSerde())
)
.filter { _, value -> value != null }
.mapValues { value -> predictor.requestWeight(value) }
.to(
"weight-prediction",
Produced.with(Serdes.String(), FishSerde())
)
return processor.build()
}
}
拓扑结构很简单:消耗主题machine-measurement ,过滤掉null 的值,在mapValues 的转换中应用预测,最后将结果返回到汇主题weight-prediction 。关于无状态和有状态转换的更多信息,请参见Kafka Streams文档。
为了发送GET request ,我们使用Ktor库:
fun request(fish: Fish, url: Url): Any? =
runBlocking {
val client = HttpClient(CIO)
try {
val response: HttpResponse = client.request(url) {
method = HttpMethod.Get
parameter("length", fish.Length)
parameter("height", fish.Height)
parameter("species", fish.Species)
}
client.close()
return@runBlocking response.readText()
} catch (e: Exception) {
logger.error("Could not receive a weight for payload: $fish to url: $url")
return@runBlocking null
}
}
}
我们设置了一个HttpClient ,并将GET request ,用附加的parameters ,发送到所需的URL。对于成功的请求,我们返回一个需要被解析为对象的JSON string ;对于失败的请求,我们返回null 。
测试
在Kotlin中测试时,我们通常使用Kotest以及Mockk来模拟对象。在这一点上,我们只专注于测试拓扑结构,尽管在文件PredictorIntTest.kt 中提供了一个API通信的集成测试。
我们使用ToplogyTestDriver来测试Kafka Streams拓扑结构。
class StreamProcessorTest : StringSpec() {
private val input = Fish("id", "salmon", 1.0, 1.0, "today", null)
private val expectedOutput = Fish("id", "salmon", 1.0, 1.0, "today", Prediction(2.0, "yesterday"))
private val properties = Properties()
init {
"Stream Processor works correctly"{
// Predictor Mock
val mockPredictor = mockkClass(Predictor::class)
every { mockPredictor.requestWeight(any()) } returns expectedOutput
// Properties Mock
properties.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
properties.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, "streamsId")
val mockProperties = mockkClass(StreamProperties::class)
every { mockProperties.configureProperties() } returns properties
// Set up Kafka Streams
val topology = StreamProcessor(mockProperties, mockPredictor).createTopology()
val testDriver = TopologyTestDriver(topology, mockProperties.configureProperties())
// Pipe into topology
val inputTopic =
testDriver.createInputTopic("machine-measurement", StringSerializer(), FishSerde())
inputTopic.pipeInput("testId", input)
// Consume output topic
val output =
testDriver.createOutputTopic("weight-prediction", StringDeserializer(), FishSerde())
// Test
output.readKeyValue() shouldBe KeyValue("testId", expectedOutput)
testDriver.close()
}
}
}
为了实例化testDriver ,我们需要创建一个拓扑结构,以及所有可以模拟的属性。接下来,我们插入一个输入和输出的Kafka主题,并向其输送一个事件。最后,我们测试拓扑结构是否如预期的那样工作。
再培训
为了比较预测值和实际权重值,我们使用ksqlDB。Kafka Connect连接器然后触发并应用再训练过程。
ksqlDB
由于我们使用confluent/cp-ksqldb-server:6.2.0 镜像,我们使用ksqlDB 0.17.0工作。
CREATE STREAM PREDICTED_WEIGHT(
"Fish_Id" VARCHAR KEY,
"Species" VARCHAR,
"Height" DOUBLE,
"Length" DOUBLE,
"Timestamp" VARCHAR,
"Prediction" STRUCT<"Weight" DOUBLE, "ModelTime" VARCHAR>
)
WITH(KAFKA_TOPIC = 'weight-prediction', VALUE_FORMAT = 'JSON');
CREATE STREAM ACTUAL_WEIGHT(
"Fish_Id" VARCHAR KEY,
"Species" VARCHAR,
"Weight" DOUBLE,
"Timestamp" VARCHAR
)
WITH(KAFKA_TOPIC = 'machine-weight', VALUE_FORMAT = 'JSON');
我们首先创建两个流。第一个显示Kafka Streams应用程序的汇主题,其中包含预测的重量。第二条包含机器测量的真实重量:
CREATE STREAM DIFF_WEIGHT
WITH(KAFKA_TOPIC = 'weight-diff', VALUE_FORMAT = 'JSON')
AS SELECT
'Key' AS "Key",
PREDICTED_WEIGHT."Fish_Id" AS "Fish_Id",
PREDICTED_WEIGHT."Species" AS "Species",
PREDICTED_WEIGHT."Length" AS "Length",
PREDICTED_WEIGHT."Height" AS "Height",
PREDICTED_WEIGHT."Prediction"->"Weight" AS "PredictedWeight",
ACTUAL_WEIGHT."Weight" AS "ActualWeight",
ROUND(ABS(PREDICTED_WEIGHT."Prediction"->"Weight" - ACTUAL_WEIGHT."Weight") / ACTUAL_WEIGHT."Weight", 3) AS "Error",
PREDICTED_WEIGHT."Prediction"->"ModelTime" AS "ModelTime",
ACTUAL_WEIGHT."Timestamp" AS "Timestamp"
FROM PREDICTED_WEIGHT
INNER JOIN ACTUAL_WEIGHT
WITHIN 1 MINUTE
ON PREDICTED_WEIGHT."Fish_Id" = ACTUAL_WEIGHT."Fish_Id";
我们根据一分钟内的Fish_Id ,将之前的两个流连接起来(这说明了过程中的时间差)。我们还计算了相对误差,即|(prediction - real)| / real 。因为我们想对所有的事件进行汇总,因此需要提供一个分组列,我们创建了一个额外的键字段,其值总是相同的Key 。关于ksqlDB中连接流和表的更多信息可以在文档中找到。
set 'ksql.suppress.enabled'='true';
CREATE TABLE RETRAIN_WEIGHT
WITH(KAFKA_TOPIC = 'weight-retrain', VALUE_FORMAT = 'JSON')
AS SELECT
"Key",
COLLECT_SET("Species") AS "Species",
EARLIEST_BY_OFFSET("Fish_Id") AS "Fish_Id_Start",
LATEST_BY_OFFSET("Fish_Id") AS "Fish_Id_End",
AVG("Error") AS "ErrorAvg"
FROM DIFF_WEIGHT
WINDOW TUMBLING (SIZE 1 MINUTE)
GROUP BY "Key"
HAVING AVG("Error") > 0.15
EMIT FINAL;
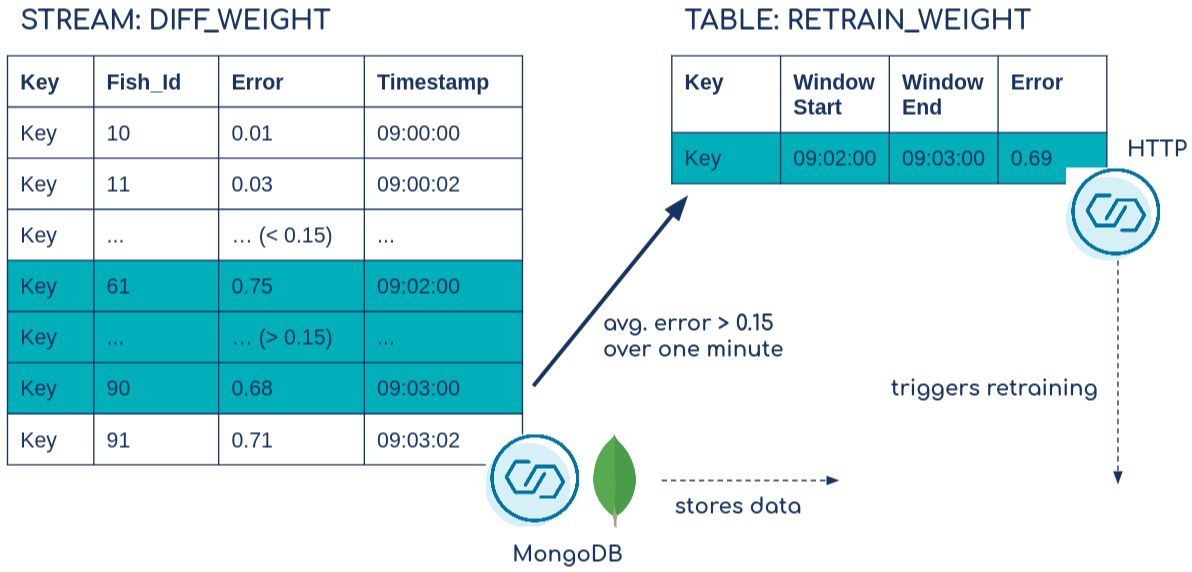
最后,基于预测错误,我们创建了一个表,作为HTTP Sink连接器的触发器。当误差在一分钟内平均大于15%的时候,它就会发出一个事件。看看‘ksql.suppress.enabled’=’true’ 和EMIT FINAL--它允许我们在窗口关闭后只发出一个事件,这是用KIP-328发布的。我们还收集一些元信息,如时间窗口的第一个和最后一个Fish_Id 。
MongoDB Sink连接器
MongoDB连接器被用来在MongoDB中存储再训练的数据:
{
"name": "WeightData",
"config": {
"name": "WeightData",
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"topics": "weight-diff",
"consumer.override.auto.offset.reset": "earliest",
"connection.uri": "mongodb://user:password@mongo:27017/admin",
"database": "Weight",
"collection": "TrainingData"
}
}
连接器消耗weight-diff Kafka主题,因为它包含用于训练的所有变量(长度、高度、实际重量、物种)。关于连接器配置的更多信息,请参阅文档或之前的博客文章《用Apache Kafka和RStudio创建数据分析管道》。
HTTP水槽连接器
HTTP水槽连接器被用来触发再训练过程:
{
"name": "RetrainTrigger",
"config": {
"name": "RetrainTrigger",
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"confluent.topic.bootstrap.servers": "broker:29092",
"confluent.topic.replication.factor": "1",
"reporter.bootstrap.servers": "broker:29092",
"reporter.result.topic.name": "success-responses",
"reporter.result.topic.replication.factor": "1",
"reporter.error.topic.name":"error-responses",
"reporter.error.topic.replication.factor":"1",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"topics": "weight-retrain",
"tasks.max": "1",
"http.api.url": "http://rstudio:8000/train",
"request.method": "POST"
}
}
它消耗weight-retrain 主题并向URL发送一个POST request 。http://rstudio:8000/train.有关其连接器配置的更多信息,请参见文档。
下面是结合Kafka Connect连接器,对加入的流DIFF_WEIGHT 和表RETRAIN_WEIGHT 行为的简化表示(不包含所有列)。
设置和运行
先决条件:Docker,Docker Compose
通过docker-compose up -d ,我们启动所有的容器:
- ZooKeeper
- Kafka broker(关于其配置的更多信息,请看文档)
KAFKA_AUTO_CREATE_TOPICS_ENABLE: “true”确保我们不需要手动创建Kafka主题,生产者在其中发送其消息- 我们还运行一个Bash命令,一旦经纪人准备好,就自动创建话题
weight-train和weight-diff(用于连接器)。
- Kafka Connect(关于其配置的更多信息,请看文档)
- 注意:MongoDB Sink连接器和HTTP Sink连接器都不是默认连接器的一部分;因此,我们从Confluent Hub下载并使用Bash命令运行它
- ksqlDB服务器和ksqlDB客户端
- MongoDB
- Kafka生产者
- 构建一个Docker镜像来执行胖子JAR,该JAR持续产生假数据到两个主题:
machine-measurement和 。machine-weight
- 构建一个Docker镜像来执行胖子JAR,该JAR持续产生假数据到两个主题:
- Kafka流
- 构建一个Docker镜像来执行胖子JAR,该JAR可以预测实时数据的重量
- RStudio
- 一个Docker镜像,用于提供预测功能和再训练功能的API。
我们需要等待一些时间,直到Kafka代理完全启动和运行。然后,我们用命令启动两个连接器。
curl -X POST -H "Content-Type: application/json" --data @MongoDBConnector.json http://localhost:8083/connectors | jq
curl -X POST -H "Content-Type: application/json" --data @HTTPConnector.json http://localhost:8083/connectors | jq
我们还用命令运行ksqlDB客户端:
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
然后我们创建流和表,用命令看一下数据流:
SELECT * FROM DIFF_WEIGHT EMIT CHANGES;
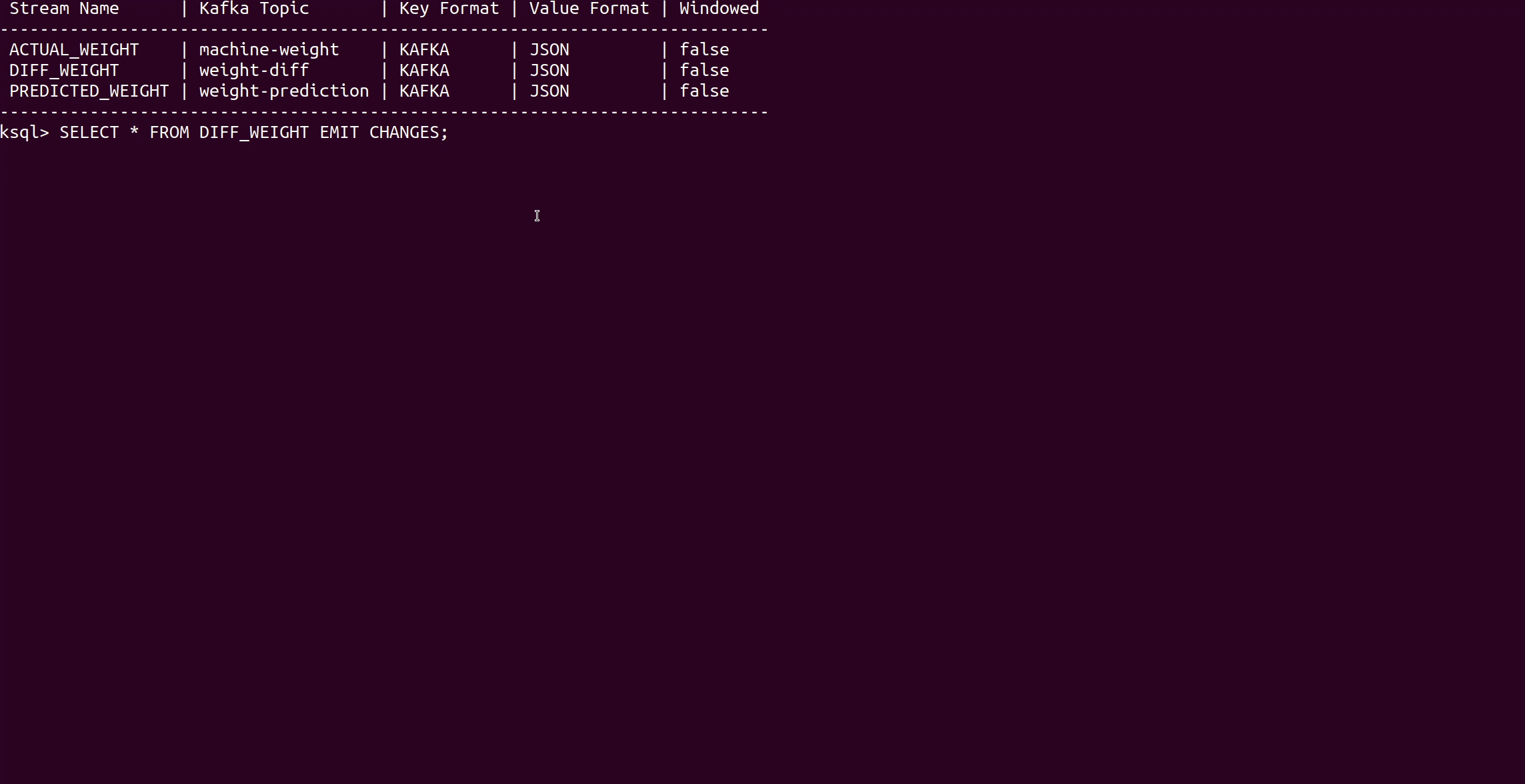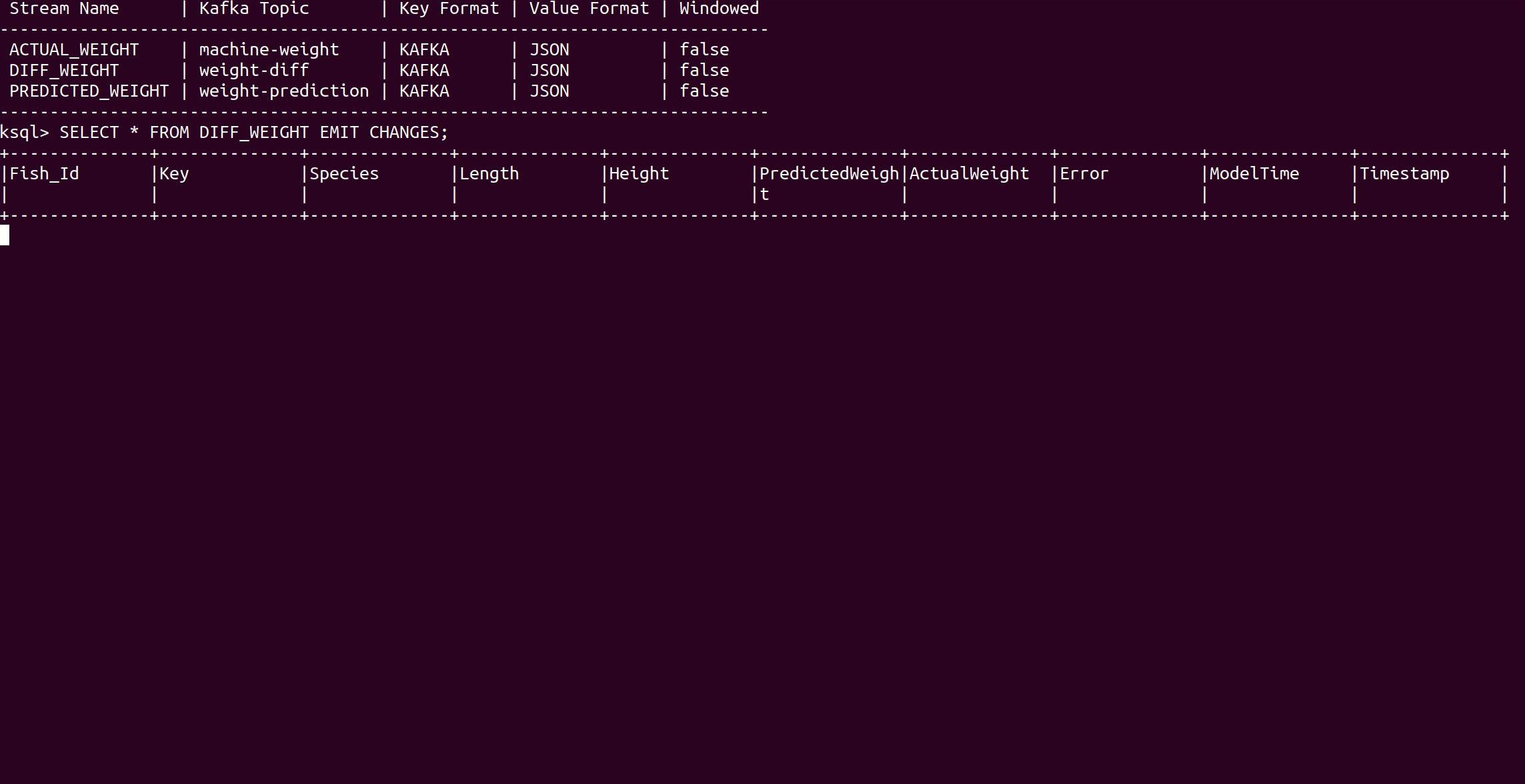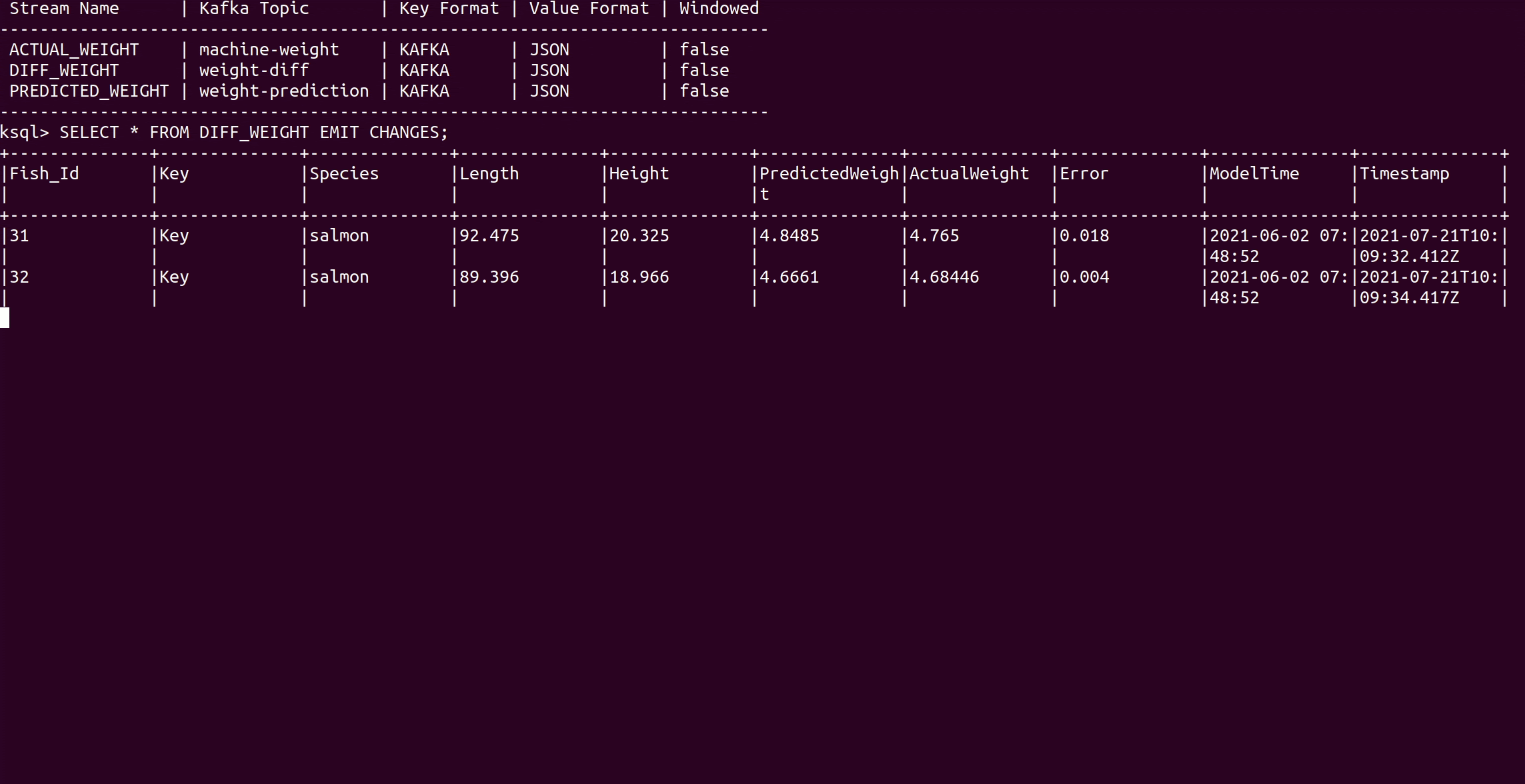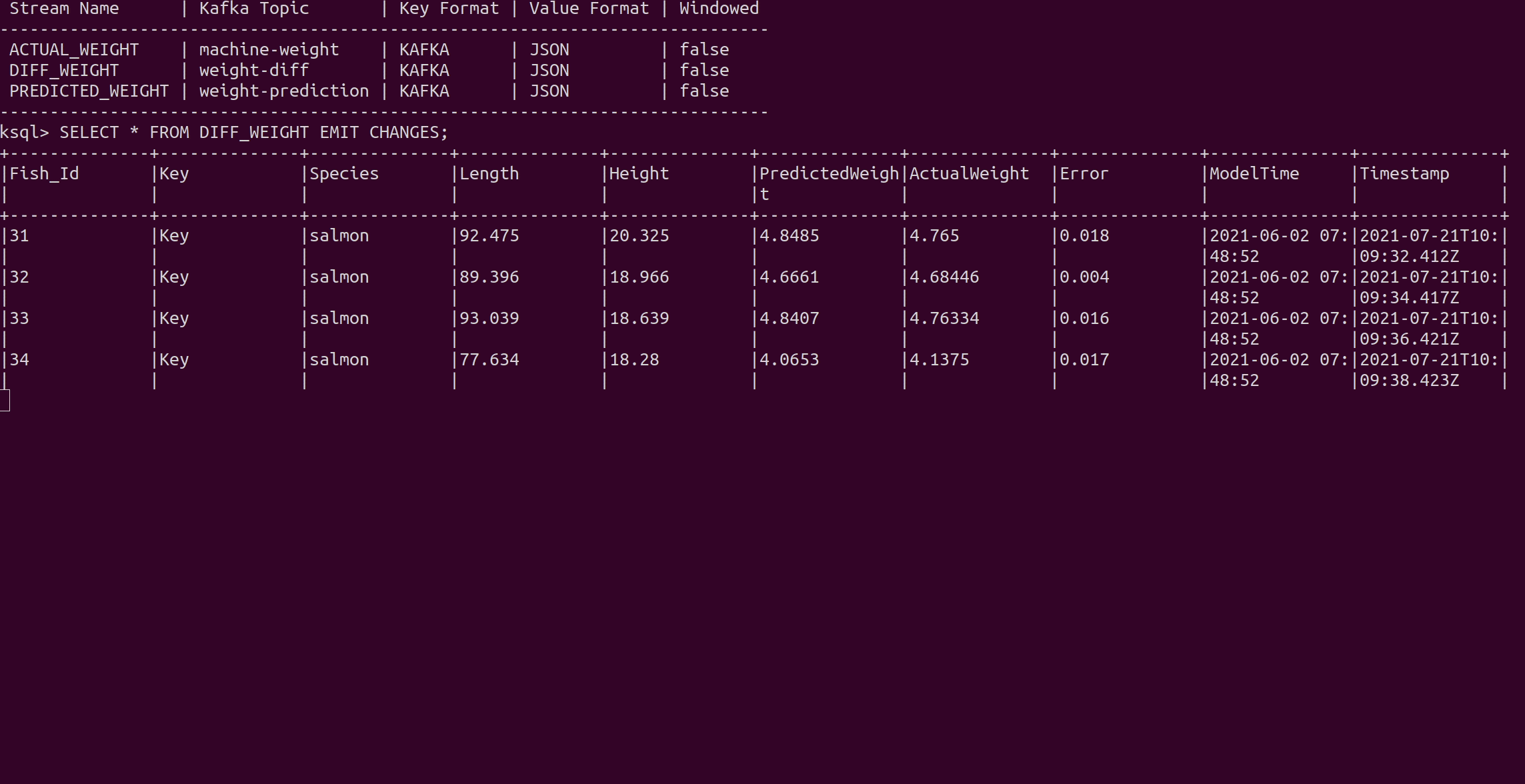
Error 列显示预测误差。对于前60条鱼(鲑鱼的种类),误差非常小,所以模型对鱼的重量预测非常好。之后,过程发生了变化,从Fish_Id 61 开始,处理了一个新的物种--马利鱼。由于模型只用鲑鱼来训练,而马勒鱼的大小和重量之间的关系不同,所以模型的预测结果急剧下降。

我们继续观察水流,发现一段时间后,预测结果再次增加,模型时间(模型训练的时间)也发生了变化。这就是应用重新训练过程的时刻,现在一个新的模型正在实时数据上运行。
在60条瓦力鱼之后,又产生了鲑鱼。然而,模型在重新训练时考虑到了物种,所以新模型可以处理两个物种,预测结果仍然准确。
最后,我们希望对重新训练的触发因素有更多的了解:
SET 'auto.offset.reset'='earliest';
SELECT * FROM RETRAIN_WEIGHT EMIT CHANGES;

一分钟的平均误差约为41%。这个错误发出了事件,触发了HTTP水槽连接器,并因此开始了再训练过程。
注意,在执行本教程时,由于时间窗口的起点和终点不同,数值可能会发生变化。
数据管道的洞察力
为了了解管道的表现,我们检查了事件的误差(预测权重与实际权重):
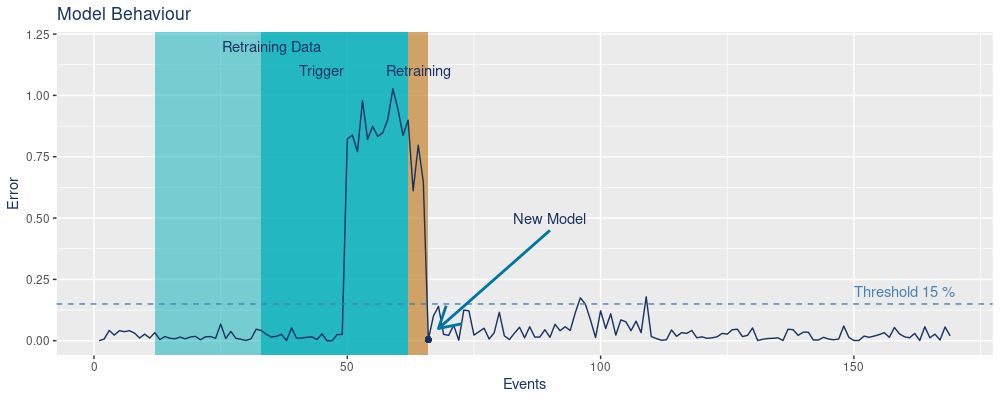
我们在X轴上看到的是事件的数量,在Y轴上看到的是误差。首先,鲑鱼被处理,误差保持在低水平(低于15%的阈值)。一旦大马哈鱼出现,误差就会增加,因为该模型没有经过训练。Trigger 期间定义了误差在一分钟内平均超过阈值的时间范围。我们用最后50个数据点开始重新训练过程(蓝色Retraining Data 框)。这个时期包括马利鱼以及鲑鱼。实际重新训练所需的时间显示在橙色的Retraining 框中。在这一时期,数据被要求,模型被重新训练,并最终被保存。
一旦新的模型被应用,我们看到预测误差再次下降。
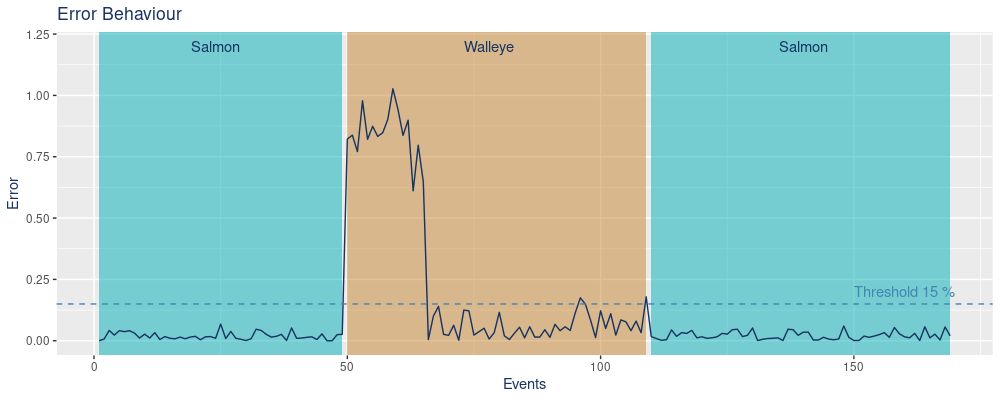
在这里,我们再次强调有关鱼类物种的误差。正如前面所解释的,一旦处理了马利鱼,该模型就表现不佳。然而,重新训练的模型对这两个物种的表现都很好,这在再次处理鲑鱼时可以观察到,但误差仍然很低。
即使该管道如预期般工作,也有一些必须考虑的限制。
首先,这个例子中的所有Kafka主题只有一个分区,这显然不是一个普遍的假设。多分区的主题是Kafka的一个常见特征,因为它们确保了可扩展性,在这种情况下,Kafka流会自动将工作负载并行化为几个任务。更多关于Kafka Streams的架构可以在文档中找到。不幸的是,R,以及随之而来的plumber,是单线程的,这意味着它不能处理并行请求。有一些解决方案可以处理这个问题,包括Jean-Baptiste Pleynet的文章《如何做一个高效的R API?在即将发表的一篇博文中,重点将放在数据管道的性能上,特别是高数据吞吐量及其带来的限制,并将包括可能的解决方案。
最后,安全是一个重要的功能。在本教程中,Kafka和所有相关服务都是在没有认证的情况下运行的(除了MongoDB),因为这个管道只是作为一个例子。对于生产用例,在创建这样一个管道时,值得考虑认证问题。你可以在Kafka的文档中找到更多关于认证的信息。
总结
在本教程中,我们使用Apache Kafka和R实现了一个用于实时预测和再训练的数据管道,主要使用Kafka Streams、ksqlDB、Kafka Connect和plumber包。
如果你在执行本教程时遇到问题或有任何疑问,请随时在社区论坛或Slack中联系我们。
