

现在,开发者似乎比以往任何时候都更多地被术语的海洋所包围,但这一切到底意味着什么?在这里,我们将把一些经常听到的术语--有些被认为只是流行语--告诉你它们如何不仅仅是 "营销术语"。相反,理解它们具有真正的力量,可以帮助你更快地实现你的开发目标,并将开发和基础设施管理降到最低。
在这篇博文中,我将定义什么是 "无服务器流处理"。这两个词的串联你很可能听过,但你不可能看到它们被应用到实际中。但这篇文章不仅仅是关于概念和实现。它描述了可以说是使用ksqlDB构建事件流应用的最重要模式。在这个模式中,我们将有状态的数据操作与无状态的业务逻辑分开。这种模式在传统的系统设计中很常见,但在流式系统中却没有很好的记录。不过这种模式很强大,你会看到。
但在我们深入探讨用事件流处理器混合无服务器功能实现高度并行工作负载的细节之前,让我们先定义以下术语:无状态和有状态处理、功能即服务(FaaS)和无服务器。
无状态和有状态处理
虽然这两个术语肯定不新鲜,但在决定如何解决某个问题时,理解它们之间的区别比以往任何时候都重要。无状态处理更简单,更容易推理,例如,考虑Java中的Predicate 接口。
调用方法Predicate.test(String value) ,根据给定的条件返回true 或false ,如value.equals(“success”) 。用相同的参数多次调用这个方法总是会产生相同的结果;换句话说,它是同位素的。但是这种类型的功能缺乏上下文,所以你真的只能把它用于诸如从流中过滤出事件的任务。你不能使用这种类型的处理方式来根据之前的事件为当前的事件做出决定。对于这种类型的处理,你需要状态。
有状态的处理是比较复杂的,因为它涉及到保持事件流的状态。有状态处理的一个基本例子是聚合。对于每一种类型的事件,你需要跟踪到目前为止看到的总数,例如,失败的登录尝试。一旦一个给定的用户ID积累了足够多的失败登录尝试,你会希望事件流应用程序执行某种行动。你只能通过保持以前事件的状态在你的应用程序中执行这种类型的行动。此外,你需要状态来执行丰富的内容,例如,在事件流中用客户ID字段填充客户的详细信息。
有状态处理的复杂性增加了,因为你需要有某种数据存储,可能是一个键值存储,最好是事件流应用程序的本地存储,以减少存储和检索的延迟。此外,你还需要有一个容错计划,以确保在本地存储被破坏的情况下能够迅速恢复状态。虽然有一些解决方案可以满足这些需求,但ksqlDB仍然是我们的首选,它提供了所有这些功能和更多开箱即用的功能。
功能即服务(FaaS)
功能即服务(或FaaS),定义宽泛,是指有一个离散的代码块可用于响应某些事件而运行的能力。FaaS允许开发者专注于一个特定的用例,并编写针对解决该特定问题的代码。此外,目标问题不是一个持续的事情,而是可能发生或零星发生的事情。
这个想法是,你上传代码并将其附加到一个触发事件上,你的代码只在需要的时候执行。否则,它就处于休眠状态,等待行动,但是,也许更重要的是,在停机期间,你不会产生任何费用,你只需为函数调用和执行时间付费。以下是今天定义FaaS的一些关键参数:
- 完全管理(在一个容器池中运行)
- 为执行时间付费(而不是使用的资源)
- 随负载自动扩展
- 0-1,000多个并发函数
- 无状态(大部分)
- 寿命短(限制在5-15分钟)
- 秩序保证不力
- 冷启动可能(非常)慢:100ms-45s(AWS 250ms-7s)
虽然无服务器这个词并不新鲜,但它的含义在开发者心中可能仍不明确。这个术语并不意味着你可以在没有服务器的情况下运行一个应用程序,而是意味着你的关注点集中在应用程序和应用程序上。开发者对基础设施没有任何关注,一旦他/她建立了应用程序,它就会被部署在一个适合处理预期负载的环境中。这种方法对企业也有巨大的好处,因为它可以专注于核心问题,而不是在自我托管应用程序时需要的 "仪式"。
这些术语可能仍然感觉有点抽象,所以让我们来探讨一些更具体的例子,这些例子在本博客的后面会有帮助。
ksqlDB
ksqlDB是一个专门为流式应用而设计的数据库,它允许你开发一个能够立即响应流向Apache Kafka®集群的事件的应用。相反,你使用的是各种背景的开发人员都熟悉的东西。SQL。例如,你可以做无状态的事件流处理。
CREATE STREAM locations AS
SELECT rideId, latitude, longitude,
GEO_DISTANCE(latitude, longitude,
dstLatitude, dstLongitude, ‘km’
) AS kmToDst
FROM geoEvents
ksqlDB也允许你做有状态的处理。例如,如果你采取上面的流,你可以创建一个有状态的流来跟踪超过十公里的较长的火车旅程:
CREATE TABLE RIDES_OVER_10K AS
SELECT rideId,
COUNT(*) AS LONG_RIDES
FROM LOCATIONS
WHERE kmToDst > 10
GROUP BY rideId
虽然这些查询写起来很简单,但它们却屏蔽了很多处理能力。在封面之下,有一个ksqlDB集群,与Kafka集群进行通信。两者都可以扩大规模,以处理几乎所有数量的传入事件。这样一来,ksqlDB就是无状态和有状态处理以及无服务器处理的好例子。
AWS Lambda
AWS Lambda是一种无服务器的计算服务,让你无需配置或管理服务器即可运行代码,是FaaS的经典定义。它也是AWS无服务器应用程序模型(AWS SAM)的一个组成部分,这是一个你可以用来构建无服务器应用程序的框架,其中包括其他组件,正如你很快就会看到。使用AWS Lambda,你只需上传打包成zip文件的代码(或容器镜像,但我们不打算在本博客中介绍),并创建一个Lambda函数定义,包括运行代码和触发机制。Lambda服务负责其他一切,比如在负载较高时扩展活动实例的数量,确定你的代码完成工作所需的最佳计算能力。
ksqlDB和AWS Lambda都实现了无服务器应用程序的承诺。通过这两种技术,你可以严格专注于实现特定的业务相关目标,而不必担心需要多少计算能力,或如何处理可用性。
分工
虽然ksqlDB和AWS Lambda都是无服务器计算服务的典范,但两者对有状态和无状态的不同类型的工作负载的适用性并不一样。ksqlDB能够同时做到这两点,但其优势在于有状态处理,以回答复杂的问题。
另一方面,由于其瞬时处理的性质,AWS Lambda更适合于无状态处理任务。
鉴于这两种技术的优势,将两者结合起来解决一个特定的问题呢?虽然Confluent云上的ksqlDB带有丰富的内置功能,但没有一个工具可以永远解决任何问题。有时你需要与外部服务打交道,一个能对Kafka主题中发现的事件做出反应的服务。进入AWS Lambda,因为它完全适合这项任务。
想象一下,你有一个ksqlDB流应用程序,它检查购买的事件流中的异常情况。当应用程序确定它发现了一个可疑的事件时,它会将该事件写到一个主题中。你想把这个可疑的活动通知给有关的客户。为此,你需要从AWS Lambda Java API中创建一个RequestHandler<I, O> (AWS Lambda支持多种运行时,但为了本博客的目的,我们将使用Java)的实例。
鉴于大多数用户的活动应该属于预期的使用模式,有点不经常需要通知用户的情况也发挥了AWS Lambda的优势,因为只有当它被使用时才会产生费用。AWS Lambda也很容易支持记录数量的激增和持续增加。现在你可能已经理解了无服务器的概念,所以让我们来看看一个更具体的例子。
一个有效的无服务器场景
为了巩固到目前为止所讨论的概念,GitHub仓库中提供了一个完整的例子。该仓库包含了一个完整的端到端示例,将ksqlDB应用与AWS Lambda整合起来进行双向通信;ksqlDB执行一些工作并将结果写入Kafka主题。Lambda函数对结果进行一些处理,并将新的结果写回Confluent Cloud上的一个主题。ksqlDB有额外的长期运行的查询来分析Lambda输出的结果。
这个项目的整体思路体现在这个图上:
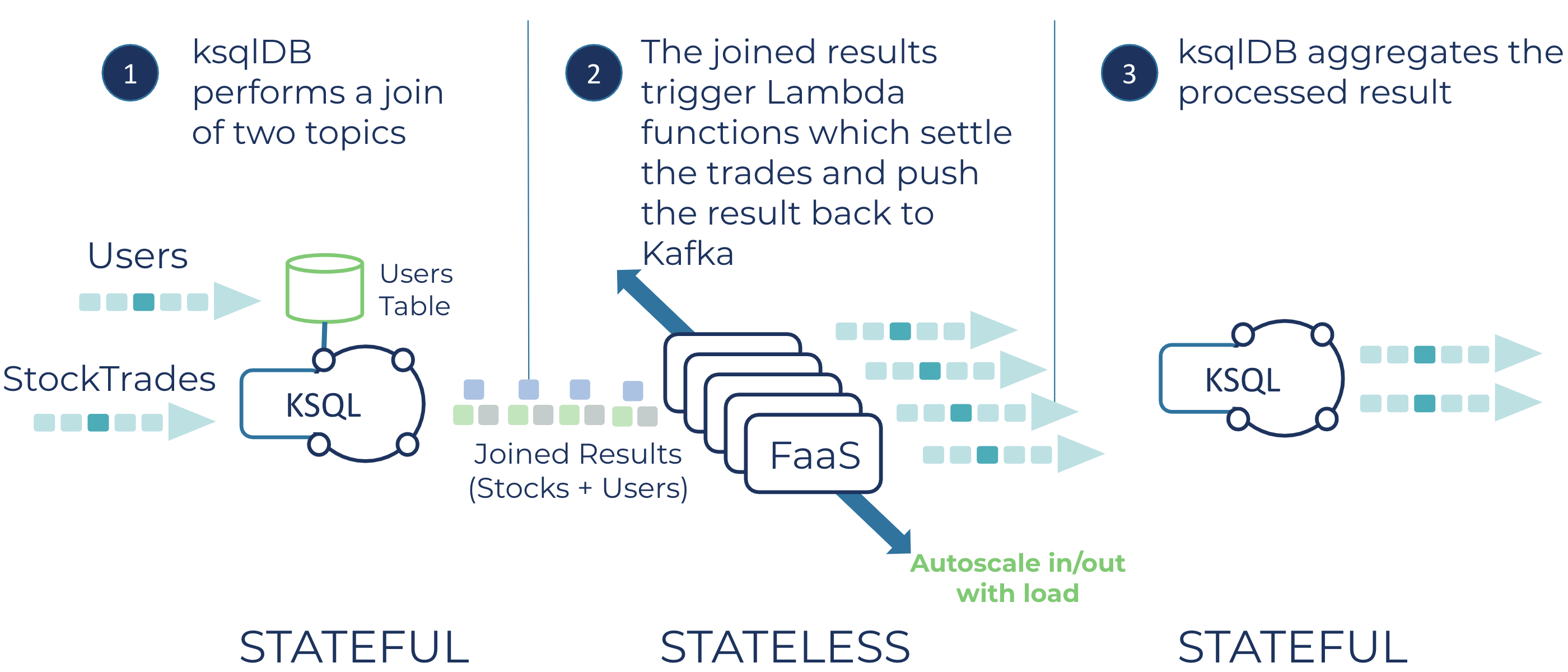
应用流程的描述
现在让我们从高层次的角度来看看应用程序的流程。
ksqlDB应用程序在Confluent Cloud上运行,利用管理的Datagen连接器来创建一个流和一个表。流的SQL看起来是这样的:
CREATE STREAM STOCKTRADE (side varchar, quantity int,
symbol varchar, price int, account varchar, userid varchar)
with (kafka_topic = 'stocktrade', value_format = 'json');
STOCKTRADE 流代表模拟的股票交易。创建包含客户信息的表(命名为USERS )的SQL的形式为:
CREATE TABLE USERS (userid varchar primary key,
registertime BIGINT, regionid varchar )
with ( kafka_topic = 'users', value_format = 'json');
ksqlDB然后执行了一个流-表连接:
CREATE STREAM USER_TRADES WITH (kafka_topic = 'user_trades')
AS SELECT s.userid as USERID, u.regionid,
quantity, symbol, price, account, side
FROM STOCKTRADE s LEFT JOIN USERS u on s.USERID = u.userid;
这个连接用执行交易的用户的信息丰富了股票交易数据。
我们使用了一个左外连接,这样我们总是有交易信息,不管用户信息在那个时间点是否存在。
让我们从应用概述中绕道而行,讨论一下ksqlDB的一个杀手锏,即有状态的流处理,或者换句话说,实时实现流数据的视图。ksqlDB使用嵌入式状态存储RocksDB,将记录持久化到ksqlDB服务器的本地磁盘。通过使用嵌入式本地存储,ksqlDB可以通过不断更新物化视图来保持流状态的运行状态。这与传统的数据库系统形成了对比,在传统的数据库系统中,当发生更新时,你必须使用触发器来更新物化视图。
此外,ksqlDB通过使用changelog主题确保你的状态是持久的。当ksqlDB向RocksDB写入一个有状态的结果时,同一记录会被持久化到支持存储的changelog主题中。如果ksqlDB服务器发生故障,从而失去了RocksDB存储,数据不会丢失,它被安全地存储在复制的changelog主题中。因此,当一个新的ksqlDB实例开始替换失败的实例时,它将重放所有的数据以填充其RocksDB实例,并继续处理物化视图上的查询。
在完成了对状态的讨论后,让我们回到示例应用程序的概述。
ksqlDB将连接的结果写到一个名为user-trades 的主题中。这个主题作为AWS Lambda的事件源映射。在这种情况下,我们使用Lambda作为一个外部进程的代理--结算交易。Lambda代码创建了一个Protobuf对象,TradeSettlement ,其中包含四个处置类型,Rejected ,Pending ,Flagged ,和Completed ,基于原始股票交易中包含的信息。然后Lambda将完成的TradeSettlement 对象返回到Confluent Cloud中一个名为trade-settlements 的主题。
上面所描述的只是你在Lambda内部可以做的事情的表面,你还可以选择:
- 根据处置代码,将记录写入不同的主题中
- 当交易状态为负面时,直接向客户发送电子邮件
- 联系机器学习(ML)模型,检查交易中的欺诈或可疑活动
重点是,Lambda为你提供了一个机会,可以执行每笔交易的业务逻辑,而不必管理任何基础设施。
对于无服务器处理的最后一步,ksqlDB应用程序从 "trade-settlements "主题中创建一个流。这个流作为四个表的来源,这些表使用翻滚窗口计算过去一分钟内每个状态的结果总数。例如,这里是确定完全结算的交易数量的SQL:
CREATE TABLE COMPLETED_PER_MINUTE AS
SELECT symbol, count(*) AS num_completed
FROM TRADE_SETTLEMENT WINDOW TUMBLING (size 60 second)
WHERE disposition like '%Completed%'
GROUP BY symbol
EMIT CHANGES;
关于这个无服务器应用程序的参考实现的最后说明。它的设置是,它将为你创建一切,你需要做的唯一步骤是运行ccloud-build-app.sh 脚本。这包括在Confluent Cloud上创建一个集群,启动Datagen连接器以提供初始数据,启动ksqlDB应用程序并运行连接查询,以及使用AWS Lambda(通过AWS CLI)。仓库的README包含了脚本创建的各种组件的工作部分的所有说明和细节。
Lambda - Kafka细节
在这一点上,我想介绍一下这个例子应用中一些比较重要的地方。
什么时候创建一个Kafka生产者实例
正如在高层次的应用描述中提到的,Lambda将产生记录返回到Confluent Cloud上的一个主题。在AWS Lambda中使用Kafka生产者是很直接的,但有一个重要的细节需要考虑。
在构建Lambda实例时,你可以在构造函数中初始化任何长期存在的资源,在字段级内联,或在静态初始化块中。任何以这种方式创建的对象都会保留在内存中,Lambda会重复使用它们,可能会跨越成千上万次的调用。在参考例子中,生产者在类的层面上被声明,并在构造函数中被初始化,如下图所示(为了清晰起见,有些细节没有提及):
public class CCloudStockRecordHandler implements RequestHandler<Map<String, Object>, Void> {
//Once initialized, producer is reusable for future invocations
private final Producer<String, TradeSettlementProto.TradeSettlement> producer;
private final StringDeserializer stringDeserializer = new StringDeserializer();
public CCloudStockRecordHandler() {
producer = new KafkaProducer<>(configs);
stringDeserializer.configure(configs, false);
通过这种方式创建生产者实例,它可以在Lambda实例的生命周期内跨执行使用。重要的是,你永远不要在处理方法本身中创建生产者实例,因为这将创建潜在的成千上万的生产者客户端,并给经纪人带来不必要的压力。
配置
当使用Kafka作为AWS Lambda的事件源时,你需要通过AWS Secrets Manager为Confluent Cloud Kafka集群提供用户名和秘密。设置Confluent Cloud集群的一部分是生成密钥和秘密,以使客户访问该集群(注意,附带的应用程序为您生成这些)。
但使用AWS Secrets Manager也提供了一个机会来存储连接到Kafka集群中的各种组件所需的所有敏感信息,如ksqlDB和Schema Registry的端点和认证。将所有这些设置放在Secrets Manager中,就可以在Lambda实例中无缝配置生产者和任何Schema Registry(de)序列化器。
AWS SDK提供了SecretsManagerClient,这使得以编程方式检索存储在Secrets Manager中的数据变得容易。让我们再看一下Lambda实例的构造函数。
public class CCloudStockRecordHandler implements RequestHandler<Map<String, Object>, Void> {
private final Producer<String, TradeSettlementProto.TradeSettlement> producer;
private final Map<String, Object> configs = new HashMap<>();
private final StringDeserializer stringDeserializer = new StringDeserializer();
public CCloudStockRecordHandler() {
configs.putAll(getSecretsConfigs());
producer = new KafkaProducer<>(configs);
stringDeserializer.configure(configs, false);
}
在类的层面上,你定义了一个名为configs 的HashMap 。然后在构造函数中,你使用方法getSecretsConfigs ,该方法利用SecretsManagerClient 检索所有必要的连接信息并将其存储在 "configs "对象中。现在,你可以轻松地将所需的连接凭证提供给任何需要它们的对象。
Kafka记录的有效载荷
Lambda服务通过handleRequest 方法向你的RequestHandler 实例分批交付记录(默认批次大小为100)。handleRequest 的签名由两个参数组成:一个Map<String, Object> 和一个Context 对象。Map "包含一个混合的对象类型的值,因此 "Object "是Map的值类型的通用名称。Context "对象提供了Lambda执行环境内部的访问,比如你可以用一个记录器来发送信息到AWS CloudWatch。
对于我们的目的,我们最感兴趣的是records 这个键,它指向的值是Map<String,List<Map<String,String>>> 。记录地图的键是主题分区的名称,值是一个地图实例的列表,列表中的每个地图都包含一个来自主题的键值对。
请注意,Map ,键和值的类型都是String 。但这并不代表话题中记录的实际类型。Lambda服务将键和值的字节数组转换为base64编码的字符串。因此,为了处理预期的键和值类型,你需要首先将它们base64解码成字节数组,然后使用适当的反序列化器。在这个例子中,我们期望的是JSON,所以它使用 "StringDeserializer"。
确保消息传递
当执行KafkaProducer#send 方法时,生产者不会立即将记录转发给经纪人。相反,它把记录放在一个缓冲区里,当这批记录满了或者它认为是时候发送这些记录的时候,再转发一批。当从AWS Lambda内部使用Kafka生产者时,重要的是你要执行KafkaProducer#flush ,作为Lambda退出前的最后一个动作。如果不这样做,就会有记录没有被发送的风险。但重要的是,你只能在处理方法的最后调用一次flush(当你完全处理了整个记录批次),而不是在每次调用KafkaProducer#send 。而且,设置acks=all ,以确保记录的持久性,这始终是一个最佳做法。
扩展和性能
构建包括AWS Lambda在内的无服务器应用程序还为你提供了在面对日益增长的需求时无缝扩展的能力。这也许是使用无服务器平台的最佳功能之一;你只需编写你的代码,其余的由平台处理。随着对计算资源需求的增长,会出现自动横向扩展,以跟上处理需求。
AWS监控底层消费者的进度。如果消费者开始滞后,AWS将创建一个新的消费者和Lambda实例来帮助处理负载。请注意,消费者的最大数量与分区的数量相等。每个消费者也只有一个Lambda实例,以确保分区的所有事件都按顺序处理。
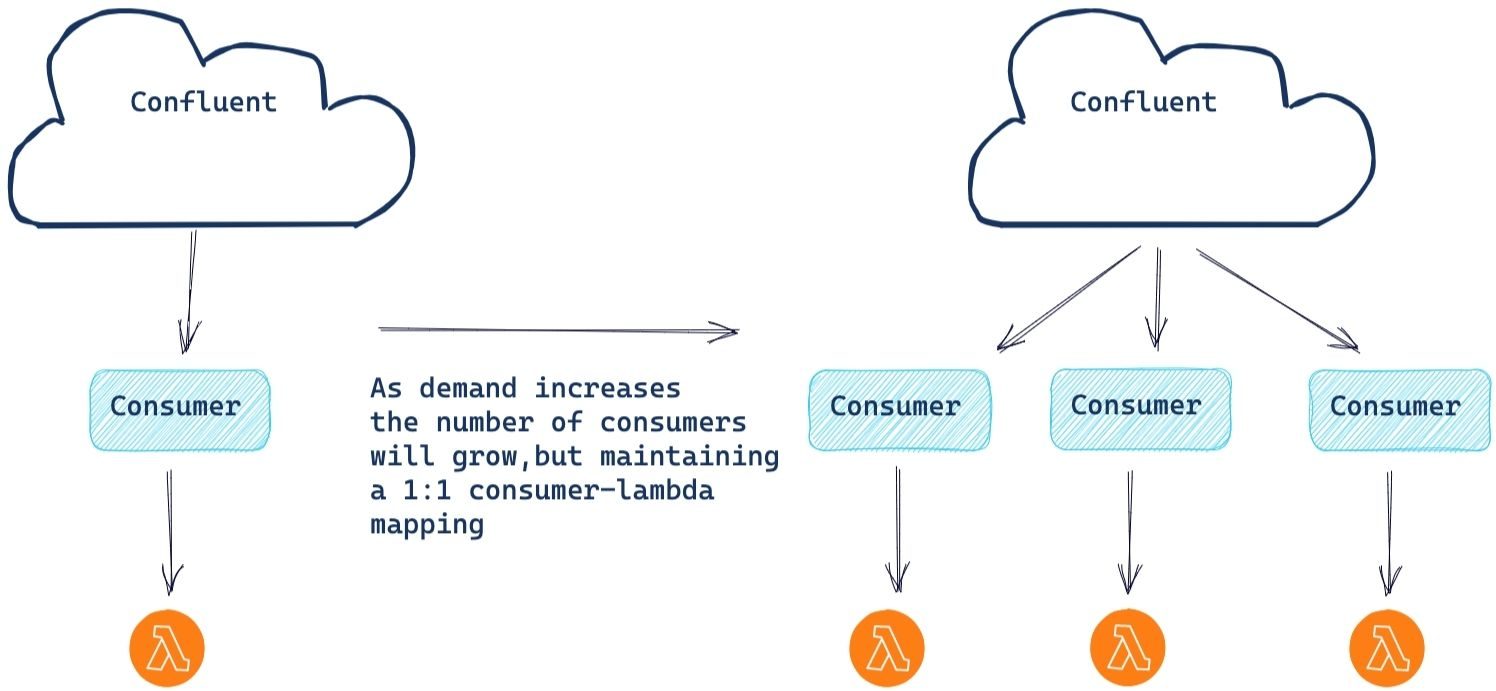
目前,有一个100个消费者的软限制,因此有100个并发的Lambda实例。如果你需要超过100个实例的最大并行化,只需向AWS提交一张服务单,他们就可以为你增加限制。
为此,我们想看看这个架构会如何应对一个有1000个分区的主题,包含大量的记录需要处理。
首先,我们与AWS服务团队协调,让他们将并发限制设置为1000个Lambda实例。为了强制增加横向扩展,我们对Lambda进行了修改,首先将批量大小设置为1(绝对不是生产值!),并在方法处理代码中加入了5秒的人为等待。选择这些值是为了模拟一个高的实例工作负载,而不必产生(和消耗)数十亿条记录。对于我们的事件数据,我们产生了5000万条记录到1K个分区的主题中,确保每个分区有50K条记录的均匀分布。
随着测试设置的完成,我们启动了AWS Lamba实例并开始测试。起初,它是由一个消费者和Lambda实例负责所有1000个分区。但以每五秒一条记录的速度(我们的工作负载在单线程内可实现的最大吞吐量),这是一个不够的进度,将迫使Lambda服务采取行动。在第一次重新平衡后(测试进行了大约15分钟),500个消费者Lambda对开始行动,产生了500倍的处理改进,达到每5秒500条记录。每隔几分钟(5-10),Lambda服务不断增加Lambda实例,最终达到目标数量。
这就是1000个消费者-Lambda对协同工作。现在,这是一些严重的并行处理!开始是每5秒一条记录,最后是每5秒1,000条记录,大大增加了主题积压的进度。虽然这是一个假想的例子,并不反映现实的生产环境,但重要的是要注意到,在所需的处理能力大幅增加的情况下,这个架构具有弹性,可以响应和满足这些需求,然后在完成工作量的激增后自动减少容量。
总结
现在你已经了解到,将ksqlDB和AWS Lambda结合起来,如何为你提供强大的无服务器一击,现在是时候了解更多关于构建自己的无服务器应用程序的信息了。请查看Confluent Developer上的免费ksqlDB介绍课程和ksqlDB内部课程,以开始在Confluent Cloud上构建无服务器事件流应用。
相关内容
- 聆听流媒体音频中由Bill Bejeck主讲的无服务器流处理播客。
- 查看《使用Apache Kafka、AWS Lambda和ksqlDB的无服务器流处理》白皮书
- 阅读AWS Lambda in Java和AWS Lambda文档,全面了解Lambda的情况
- 了解更多关于在Confluent Developer上构建无服务器数据流应用的信息
