

如何让你的数据进出你的Apache Kafka®集群是一个值得深思熟虑的选择。一方面,你可以选择使用Kafka Connect框架来开发自己的连接器。有一些使用案例可以开发一个专有的或专门的连接器,然而,由于缺乏支持,这通常不被推荐。除此之外,一个工程团队开发一个连接器平均需要6个月的时间(这还得假设你真的了解自己的东西)。
另一方面,你可以利用社区已经建立的现有开源连接器。在这种情况下,你可以避免几个月的开发,但是,这也有一点风险,因为开源连接器是不支持的。如果发生故障会怎样?在这两种选择中,促使Confluent提供广泛的预建连接器组合,使您能够通过企业级的安全性、可靠性、兼容性和支持,更快地实现整个数据架构的现代化。
这篇博文探讨了一种低运营开销的模式,即使用AWS EKS Fargate和Conflent for Kubernetes与Confluent Cloud一起托管Kafka Connect和Confluent连接器。
完全管理的连接器与自我管理的连接器
Confluent提供两种类型的连接器:完全管理和自我管理。
完全管理的连接器,可通过Confluent云,为您提供一个 "设置并忘记它 "的经验。凭借简单的基于UI的配置、弹性扩展和无需管理的基础设施,完全管理的连接器使得将数据移入和移出Kafka成为一件毫不费力的事情,让你有更多时间专注于应用开发。关于可用的完全管理的连接器的完整列表,请访问Confluent Cloud文档。
在以下情况下,自我管理的连接器可用于从您的Kafka集群中获取数据:您正在使用Confluent平台,您想使用的连接器尚未在完全管理的组合中提供,您的架构在使用VPC peered/PrivateLink集群时需要灵活的连接,或者在使用Confluent Cloud与企业内部资源时。这些类型的连接器提供了与完全管理的连接器相同程度的安全性和支持;但是,它们要求客户积极监测容量并自动进行扩展活动。
这篇文章探讨了在使用Confluent Cloud创建无服务器体验时,利用AWS来进一步抽象出自我管理连接器的操作负担。
一个主张:在EKS Fargate上运行你的自我管理的连接器
AWS Fargate是一项为容器提供按需、合适大小计算能力的技术。有了AWS Fargate,你不需要自己调配、配置或扩展虚拟机组来运行容器。你也不需要选择服务器类型,决定何时扩展你的节点组,或优化集群包装。
简而言之,EKS Fargate允许你以无服务器的方式运行自我管理的连接器。
为了展示AWS无服务器的Kubernetes产品上自我管理的连接器的力量,我们将通过以下设置:
- 在EKS Fargate集群上部署Kafka Connect。
- 使用Kafka Connect来指定S3源连接器应在运行时加载。
- 上传一个测试的JSON文件,由S3源连接器读取并写入Confluent Cloud集群中的一个主题。
大部分设置使用Confluent for Kubernetes(CFK),这是一个云原生控制平面,用于在你的私有云环境中部署和管理Confluent。这个捆绑包包含了Helm图表、模板和脚本,它们将把部署简化为几行命令。
前提条件
在开始之前,本攻略需要以下条件:
- Confluent云账户(当你第一次注册时,你会收到400美元的信用额度)
- AWS账户
- 一个带有访问密钥和SR访问密钥的Confluent Cloud集群设置
- 安装了AWS CLI
- 安装了Kubectl
- 安装了Helm
- 安装了Eksctl
创建IAM执行角色
根据AWS文档,"在AWS Fargate基础设施上运行pod,需要Amazon EKS pod执行角色。当你的集群在AWS Fargate基础设施上创建pod时,在Fargate基础设施上运行的组件需要代表你调用AWS API,以完成从Amazon ECR拉取容器镜像或将日志路由到其他AWS服务等事情。亚马逊EKS豆荚执行角色提供了IAM权限来做到这一点。"你将使用这个相同的角色来授予EKS pod权限到你的S3桶。
导航到IAM并创建一个新角色。
选择EKS并进一步向下滚动,选择EKS - Fargate pod。
你会注意到 "AmazonEKSFargatePodExecutionRolePolicy "已经被附加了,没有其他政策(在这个时候)可以被附加。AWS通常允许你在创建期间为一个角色附加多个策略,但在这种情况下,AWS不允许附加额外的策略。然而,你将能够在这个过程的后期附加额外的政策。现在,只需点击进入审查页面,在那里你将提供角色名称并点击创建角色。
角色创建后,你现在可以通过搜索你新创建的角色并附加政策来添加更多的政策。由于你需要访问从S3读取数据并将其放入你的Confluent Cloud集群,你需要将AmazonS3ReadOnlyAccess策略添加到你的EKS Fargate Pod角色。
注意这个角色的名字,这样你就可以在以后的集群创建过程中引用它。
设置EKS集群
在你的本地机器上保存YAML文件。这个配置文件将被传递到下面的命令中,以便在创建时指定EKS集群设置:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: connector-fargate
region: <YOUR_AWS_REGION>
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: s3-reader
namespace: confluent
attachRoleARN: <role_you_created_for_EKS_Fargate>
fargateProfiles:
- name: fp-default
selectors:
- namespace: confluent
- namespace: kube-system
iam角色:创建一个服务账户角色,pod可以与其他AWS服务互动。注意附加的角色是你在上一步创建的角色。
fargateProfiles\:指定在Fargate上部署哪些资源。在这种情况下,Confluent和kube-system命名空间内的所有pod都被部署到Fargate。
欲了解更多信息,请查看eksctl文档。
使用上面的YAML文件和下面的命令,你将在Fargate上创建一个EKS集群(这将需要几分钟时间):
eksctl create cluster -f fargate.yaml
在集群创建完成后,配置kubectl以指向你的集群:
aws eks update-kubeconfig --region --name connector-fargate
确保kubectl正在使用正确的连接器:
kubectl config use-context connector-fargate
将confluent\ 作为默认的命名空间,使命令更容易。或者,你可以在所有后续命令中添加-n confluent :
kubectl config set-context --current --namespace=confluent
部署操作者pod
随着kubectl现在被设置为与你的EKS Fargate集群通信,你可以开始配置该集群。你将使用以下包含Confluent for Kubernetes(CFK)的Helm repo来部署一个操作员pod。操作员豆荚将在以后被用来部署连接器豆荚:
helm repo add confluentinc https://packages.confluent.io/helm
从新添加的repo中安装操作员:
helm upgrade --install operator confluentinc/confluent-for-kubernetes -n confluent
提示
你可以通过综合使用以下命令来跟踪你的pod部署:
kubectl get events --sort-by='.metadata.creationTimestamp'
kubectl get pods
kubectl logs -f <your_pod_name>
kubectl describe pod <your_pod_name>
设置秘密
创建一个名为 ccloud-credentials.txt 的新文件:
username=<your_cluster_key>
password=<your_cluster_secret>
创建另一个名为ccloud-sr-credentials.txt的新文件:
username=<your_cluster_schema_registry_key>
password=<your_cluster_schema_registry_key>
参考这些新的文本文件,你将创建Kubernetes的秘密,使你的连接器能够与Confluent Cloud对话:
kubectl create secret generic ccloud-credentials --from-file=plain.txt=ccloud-credentials.txt
kubectl create secret generic ccloud-sr-credentials --from-file=basic.txt=ccloud-sr-credentials.txt
部署连接器豆荚
在创建了EKS集群、部署了操作员pod并生成了必要的秘密之后,你现在就可以准备部署连接器pod了。
创建一个名为 "s3.yaml "的新文件,并将下面的代码粘贴到其中。这将被用来部署一个S3连接器豆荚。请确保你更新了模式注册表的URL和引导端点,以匹配你的集群的。另外,注意对集群秘密和你之前创建的模式注册表秘密的引用。
apiVersion: platform.confluent.io/v1beta1
kind: Connect
metadata:
name: s3
spec:
replicas: 1
image:
application: confluentinc/cp-server-connect:7.0.1
init: confluentinc/confluent-init-container:2.2.0-1
podTemplate:
resources:
requests:
cpu: 1000m
memory: 512Mi
probe:
liveness:
periodSeconds: 10
failureThreshold: 5
timeoutSeconds: 30
initialDelaySeconds: 100
readiness:
periodSeconds: 10
failureThreshold: 5
timeoutSeconds: 30
initialDelaySeconds: 100
podSecurityContext:
fsGroup: 1000
runAsUser: 1000
runAsNonRoot: true
build:
type: onDemand
onDemand:
plugins:
locationType: confluentHub
confluentHub:
- name: kafka-connect-s3-source
owner: confluentinc
version: 2.0.1
dependencies:
kafka:
bootstrapEndpoint: <your_bootstrap_endpoint>
authentication:
type: plain
jaasConfig:
secretRef: ccloud-credentials
tls:
enabled: true
ignoreTrustStoreConfig: true
schemaRegistry:
url: <your_schema_registry_url>
authentication:
type: basic
basic:
secretRef: ccloud-sr-credentials
用下面的方法部署连接器:
kubectl apply -f ./s3.yaml
一旦pod准备好了,打开一个端口,通过http与pod通信:
kubectl port-forward s3-0 8083
配置连接器
最后的设置步骤是配置连接器。在一个单独的终端,发出以下命令。这将把S3源连接器设置为通用模式,这意味着它可以读取任何支持的文件类型,而不只是由S3汇连接器写入的数据。关于配置的可用字段的更多信息,请访问S3连接器文档:
curl -X PUT \
-H "Content-Type: application/json" \
--data '{
"connector.class" : "io.confluent.connect.s3.source.S3SourceConnector",
"name" : "s3",
"tasks.max" : "1",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter",
"mode" : "GENERIC",
"topics.dir" : "quickstart", <-- Folder within S3 bucket.
"topic.regex.list" : "quick-start-topic2:.*", <-- “Destination topic”:”regular_expression”. In this example, the * means to read all files”
"format.class" : "io.confluent.connect.s3.format.json.JsonFormat",
"s3.bucket.name" :<your_bucket_name>,
"value.converter.schemas.enable" : "false",
"s3.region" : "us-east-2",
"aws.access.key.id" : <your_access_key_id>,
"aws.secret.access.key": <your_access_key_id>
}' \
http://localhost:8083/connectors/s3/config | jq .
注意
aws.access.key.id:建议依靠服务账户角色来提供对S3等服务的访问。这段代码只是展示了另一种提供这种访问的方法,前提是你有适当的范围的键来拥有尽可能少的权限。
s3.region:虽然S3服务是一个全局服务,你仍然必须指定S3桶的创建位置。请访问AWS CLI docmentationfor S3以了解更多信息。
如果一切顺利,你应该能够发出以下命令并收到类似的响应:
curl http://localhost:8083/connectors/s3/status | jq
{
"name": "s3",
"connector": {
"state": "RUNNING",
"worker_id": "s3-0.s3.confluent.svc.cluster.local:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "s3-0.s3.confluent.svc.cluster.local:8083"
}
],
"type": "source"
}
上传一个测试文件
导航到你的S3源连接器正在读取的S3桶,并上传一个有效的JSON文件。下面提供了一个样本:
{
“f3”: “3”
}
查看测试文件
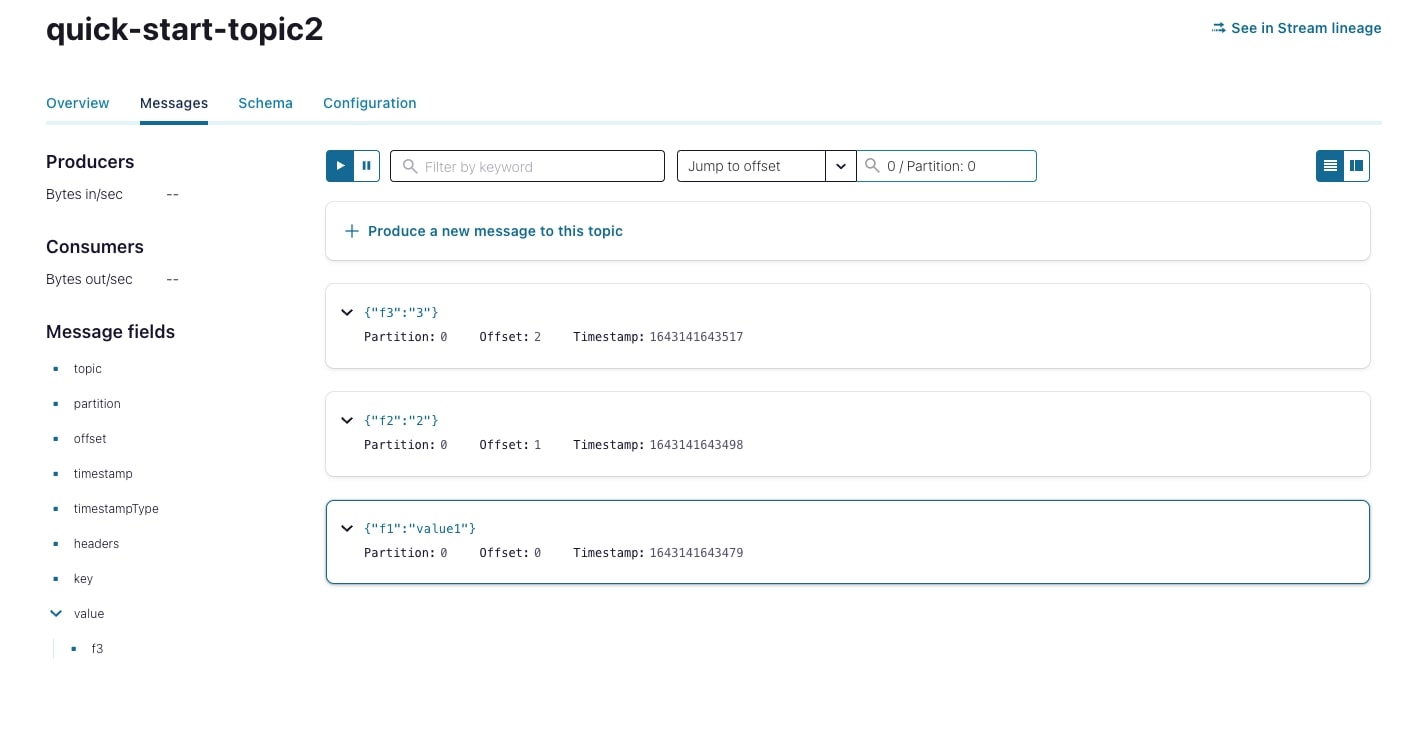
在confluent.cloud中导航你的集群,点击主题部分。由于S3连接器不会自动创建一个主题,你必须创建你提供给连接器的配置文件中指定的主题(见上面的配置连接器部分)。在提供的例子中,我们将目标主题设置为quick-start-topic2。一旦话题被创建,你就会看到数据流向该话题。
结论
将EKS Fargate的弹性与Confluent的预建连接器结合起来,在选择自我托管连接器和Confluent云集群时,给你带来灵活性和最小的操作开销。由于类似的步骤也可以用来实现水槽连接器,这意味着你现在有一个可扩展的方法,不仅可以将你的数据移入你的Kafka集群,还可以将你的数据移出集群。通过注册Confluent Cloud,你将获得400美元的免费使用权,以进一步探索Confluent如何帮助你让你的数据运动起来。
