

处理 "垃圾进"、"垃圾出"(GIGO)的问题已经折磨了几代数据团队。分析和决策一直受到这种 "垃圾 "的影响。机器学习的新时代和越来越多的数据驱动带来了更多的担忧和后果。数据质量控制确保数据适合消费,并满足下游数据消费者和整个企业用户的需求。
虽然数据质量在静止的数据世界中是一个问题,但在运动中的数据和流媒体的新世界中,这个问题更加严重,因为坏数据可以更快地传播到更多地方。特别是,在对实时数据立即做出反应的事件驱动系统中,坏的数据会导致整个生态系统的应用程序和服务崩溃,或在无效的模式和信息上以次优的方式运行。
在异步消息传递模式中,由不同团队开发、维护和部署的解耦服务和应用程序必须有办法理解对方。这些实体需要能够通过商定的数据合同进行通信,他们都可以信任和分享--这是一种数据流的语言符号。
那么,为什么我们现在比以往任何时候都更能感受到糟糕的数据质量带来的痛苦?
- 数据的数量、种类和速度正在迅速增加,特别是随着流媒体和运动数据的兴起。
- 全球范围内的数据系统的重新架构正在发生,并向云端大规模转移
- 日益复杂的数据架构,应用程序、数据库和其他数据系统激增,需要在不同环境中相互对话
- 纠结和动态的数据流使得很难准确地指出问题发生的地方
- 随着团队向分布式数据所有权模式的转变,数据所有权也变得不那么清晰了
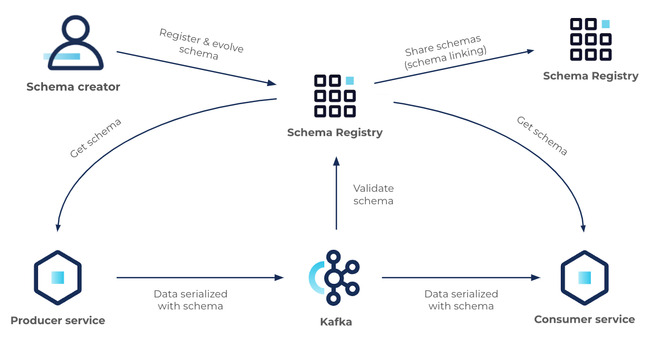
用Confluent的流质量确保流数据质量
Confluent的流质量使团队能够在整个业务中提供可信的实时数据流。这些组件设置和控制数据规则、约束和条件,整个事件驱动的系统就是据此运行的。目前,流质量包括两个组件:模式注册和模式验证。
在这篇博文中,我们将深入讨论这些组件的重要性,涵盖最常见的用例,并告诉你如何快速启动和运行。
模式注册:定义和共享数据合同的最简单的方法,没有操作的复杂性
Confluent的Schema Registry是一个模式的中央存储库,它。
- 允许生产者和消费者通过模式形式的定义明确的 "数据合同 "进行通信
- 通过每个人都能理解的明确的兼容规则来控制模式的演变
- 通过传递模式ID而不是整个模式定义来优化网上的有效载荷
在其核心部分,模式注册有两个主要部分:
- 一个用于验证、存储和检索Avro、JSON Schema和Protobuf模式的REST服务
- 插入Apache Kafka®客户端的序列化器和反序列化器,用于处理这三种格式的Kafka消息的模式存储和检索
此外,Schema Registry还可以与Confluent生态系统的其他部分无缝集成。
所以,让我们看看如何利用Schema Registry在Kafka中可靠地生产和消费数据。
1.选择一个数据序列化格式
决定在Kafka中使用哪种数据序列化格式是一个重要的问题。在我们的环境中,数据序列化是将一个对象转化为字节流的过程,通过电线发送并存储在Kafka中。从存储在Kafka中的字节流中重构对象的反向过程被称为反序列化。我们建议你使用一个支持模式的序列化格式。模式在数据流中对于各方之间的清洁和安全的通信极为重要。模式在数据流中扮演着一种API的角色;作为解耦服务和应用程序的操作界面。
如上所述,在Confluent,我们增加了对Avro、协议缓冲区和JSON的特别支持。这些是我们推荐的与Kafka一起使用的序列化格式。决定使用这三种格式中的哪一种,其实取决于你的需求、偏好和限制。
下表提供了三种格式的特点和区别的快速浏览,以帮助你做决定:
| Avro | 协议缓冲区 | JSON | |
| 类型 | 基于二进制的 | 基于二进制的 | 基于文本的 |
| 模式支持 | 有 | 有的 | 有 |
| 读取时的模式 | 是的 | 不 | 没有 |
| 模式语言 | JSON | Protobuf IDL | JSON |
| 大小/压缩 | 伟大的压缩 | 极大压缩 | 无压缩 |
| 速度 | 非常好 | 非常好 | 中等的 |
| 使用方便 | 非常好 | 很好 | 非常好 |
| 支持的编程语言 | 很好 | 非常好 | 很好 |
| 工具化 | 非常好 | 非常好 | 中等 |
| 社区活动 | 中等 | 很好 | 中等 |
2.在模式注册表中注册一个模式
一旦你建立并运行了模式注册中心,你就可以通过用户界面、API、CLI或maven插件开始注册模式了。模式注册中心将为每个注册的模式分配一个单调增长(但不一定是连续的)的唯一ID(在该注册中心内)。此外,对于非生产场景,你可以让你的生产者应用程序直接用属性auto.register.schemas=true.
注册一个模式。
3.制作记录到Kafka
现在是时候开始向Kafka发送数据了。生产者要做的第一件事是从模式注册处获取模式ID,给定一个Avro、Protobuf或JSON对象(参考描述它的模式)。然后,模式ID将被预置到记录的有效载荷(模式ID+记录)中,并被发送到Kafka。注意,所有这些协调都是由Kafka客户端上的Avro、Protobuf和JSON序列化器自动完成的。
4.从Kafka获取记录
在消费者端,收到有效载荷后,消费者要做的第一件事就是提取模式ID(有效载荷的第1至5字节,第0字节是一个神奇的字节),如果缓存中没有,就用它在模式注册中心查找/获取写作者的模式(客户端在第一次与模式注册中心对话时缓存了模式ID到模式的映射,并将其用于后续查找)。有了写作者模式和当前的读者模式,消费者现在可以对有效载荷进行反序列化。注意,所有这些协调工作都是由Kafka客户端上的Avro、Protobuf和JSON反序列化器自动完成的。
5.演化模式
生产者和消费者在模式演进方面是解耦的,他们可以按照商定的兼容类型独立升级他们的模式。在最初的模式被定义后,应用程序可能需要随着时间的推移而演化它。当这种情况发生时,下游消费者能够无缝地处理用新旧模式编码的数据是至关重要的。这是一个在实践中往往被忽视的领域,直到你遇到第一个生产问题。如果不仔细考虑数据管理和模式的演变,人们往往会在以后付出更高的代价。
一般来说,后向兼容是最容易操作的,因为它不要求你提前计划未来的变化,所以你只需要考虑模式的过去版本。你可以在遇到新的需求时进行模式变更。首先,你将更新新的消费者以适应模式的变化,然后你将更新生产者。
引用Martin Kleppmann关于模式演变的精彩博文:
"在现实生活中,数据总是在不断变化。当你认为你已经敲定了一个模式的时候,有人会想出一个没有预料到的用例,并希望'只是快速添加一个字段'。"
随着Kafka的使用增长,以支持企业内更多的关键任务的工作负载,以及更多的团队开始使用该技术,建立和执行数据质量的全球控制的需求只会增加。模式链接为共享模式和建立一致的质量控制提供了一个简单的方法,在任何需要的地方:跨云、企业内部、整个混合环境等。与集群链接相配,这使你能够。
- 通过共享模式和完美的镜像数据建立一个全球连接和高度兼容的Kafka部署。
- 通过利用实时同步的共享模式,确保各地数据的兼容性和操作的简便性
- 共享模式以支持每一个集群连接的用例,包括具有成本效益的数据共享、用于灾难恢复的多区域数据镜像、集群迁移等等。
将此付诸行动--StreamWearables
让我们通过一个电子商务企业StreamWearables如何处理其在线订单的例子来了解模式一致性和兼容性的重要性。在下图中,我们可以看到在线的 "订单服务 "向一个名为 "订单 "的主题产生新的订单事件,两个消费者 "发货服务 "和 "客户奖励服务 "消耗这些事件进行进一步处理。
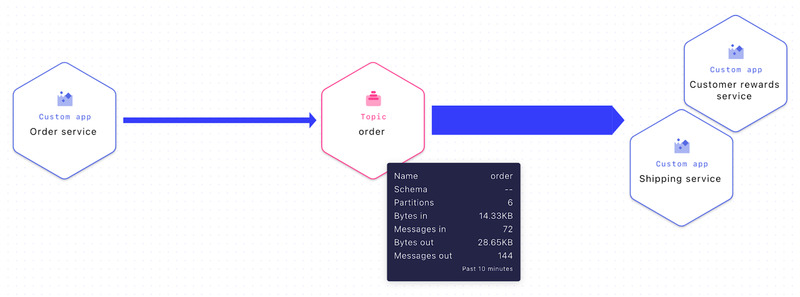
Stream Lineage(数据流的实时视图)"订单服务 "向主题 "订单 "生产,"客户奖励服务 "和 "航运服务 "从主题 "订单 "消费。
现在,因为StreamWearables的团队认为他们在相互沟通和保持同步方面很出色,所以模式和模式注册成为事后的考虑。"让我们在没有模式的情况下继续前进",首席流媒体架构师Francisco说,"不需要担心,因为我们已经控制了一切,生活很美好"。这倒是真的,直到它变得不那么好为止。有一天,"订单服务 "决定将orderId 类型从数字改为字符串,然后💣💣💣,"发货服务 "和 "客户奖励服务 "都崩溃了。
接下来,灾难降临,订单无法完成--现在,有人需要在星期六的凌晨2点给首席执行官打电话,在他一年中唯一的假期里。

"发货服务 "日志在 "订单服务 "改变数据格式之前和之后的情况
有 "订单服务 "的Stream Lineage向 "订单 "主题生产,但没有服务从中消费(由于意外的数据格式变化,服务崩溃的结果)。
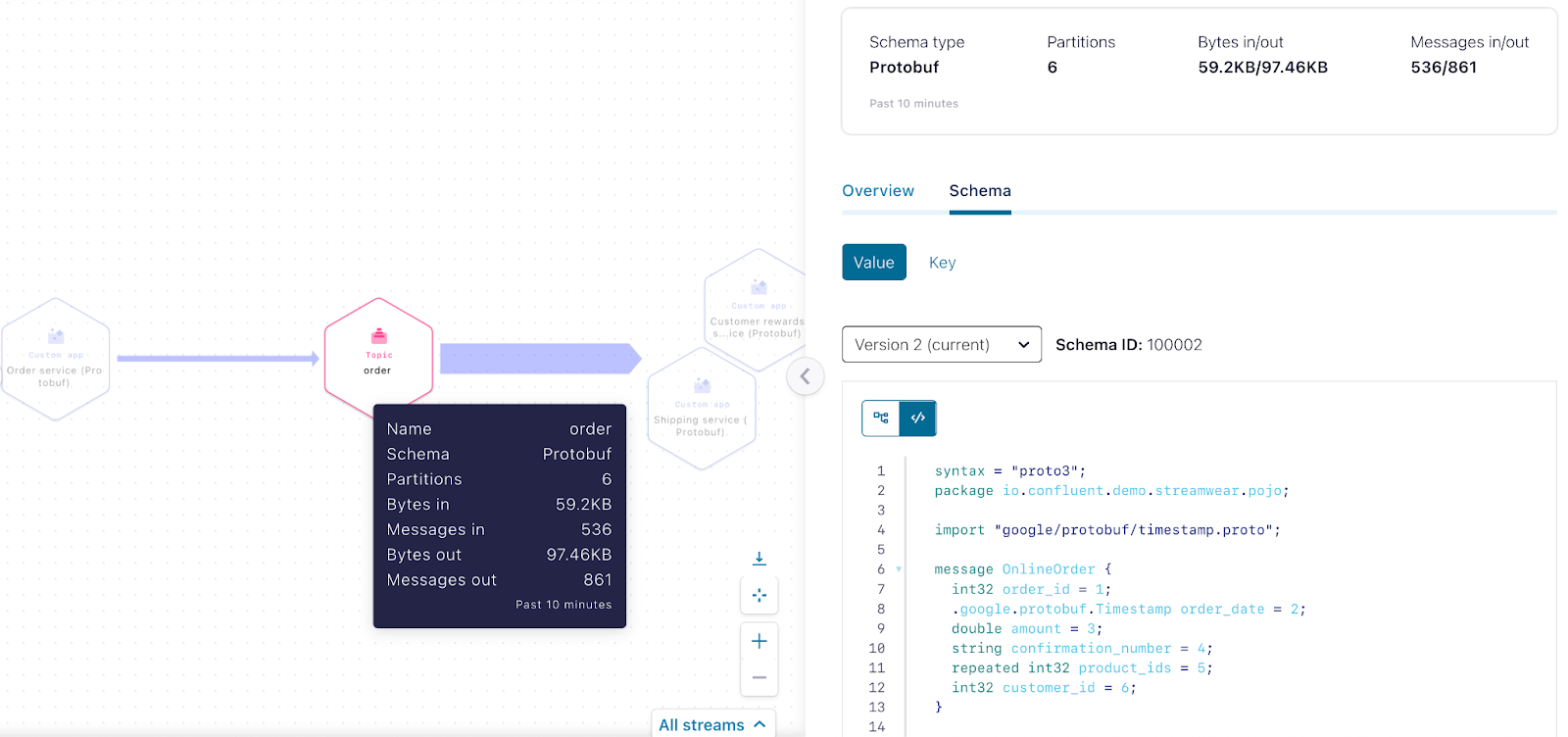
StreamWearables团队是如何解决这个问题的?他们以Protobuf模式的形式为订单事件创建了一个明确的数据契约,并在模式注册中心注册了它。
syntax = "proto3";
package io.confluent.demo.streamwear.pojo;
import "google/protobuf/timestamp.proto";
message OnlineOrder {
string order_id = 1;
google.protobuf.Timestamp order_date = 2;
double order_amount = 3;
repeated int32 product_id = 4;
int32 customer_id = 5;
}
OnlineOrder Protobuf模式
接下来,所有的团队都改变了他们的代码,以使用Confluent的Protobuf序列化器和反序列化器与新的Protobuf模式。
// Set key serializer to StringSerializer and value serializer to KafkaProtobufSerializer
props.put("key.serializer", StringSerializer.class);
props.put("value.serializer", "io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializer
");
// New online order - create the OnlineOrder POJO generated from protoc-jar-maven-plugin
Order.OnlineOrder order = new OnlineOrder().newProtobufOrder();
// Create a producer
Producer producer = new KafkaProducer<>(props);
// Create a producer record
ProducerRecord record =
new ProducerRecord<>(topic, "" + order.getOrderId(), order);
// Send the record
producer.send(record);
// Close producer
producer.close();
使用KafkaProtobufSerializer的订单服务代码片段
随着所有服务的运行和与新的订单模式的通信,现在让我们再看看Stream Lineage内的数据流:
StreamWearables团队从这次事件中吸取了教训;"SCHEMA- DRIVEN DEVELOPMENT ROCKS "现在被写在了办公室的墙上。
最后但并非最不重要的是,首席执行官履行了他的承诺:每个人都在Stream船上度过了为期一周的假期,以示庆祝

来源:原图来自于《爱之船:幸福的生活》(1986),为本博文修改
模式验证:只需点击一个按钮就能强制执行数据契约
使用模式和模式注册是非常简单的,如上文所解释的,但要依靠客户端来确保规则得到遵守,也就是说,数据的序列化和反序列化要符合在模式注册处注册的模式。这基本上是数据的生产者和消费者之间的握手协议。

源于此。"为生活而设计"(1933)
但是,如果有一方退出了协议,不管是自愿的还是非自愿的,怎么办?通常在这种情况下,你最终会在Kafka中得到坏的数据。请注意,这不一定是坏的行为者--事实上,很多时候,也可能是最常见的是简单的错误配置或没有意识的客户端。
Schema Validation确保产生到Kafka主题的数据在Schema Registry中使用了有效的模式ID,如果不是这样,就会以验证错误的方式丢弃它。从本质上讲,模式验证可以确保双方都遵守他们的协议。今天,模式验证适用于Confluent云的专用集群,以及Confluent平台。

在Confluent CLI生产者中,当试图向配置了经纪方模式验证的主题 "order "发送 "garbage "消息时,出现了错误信息。
在主题上启用模式验证是很简单的,可以使用Confluent CLI或Confluent UI进行配置:
confluent kafka topic update order --config
confluent..schema.validation=true
使用Confluent CLI在主题订单上启用经纪方模式验证:
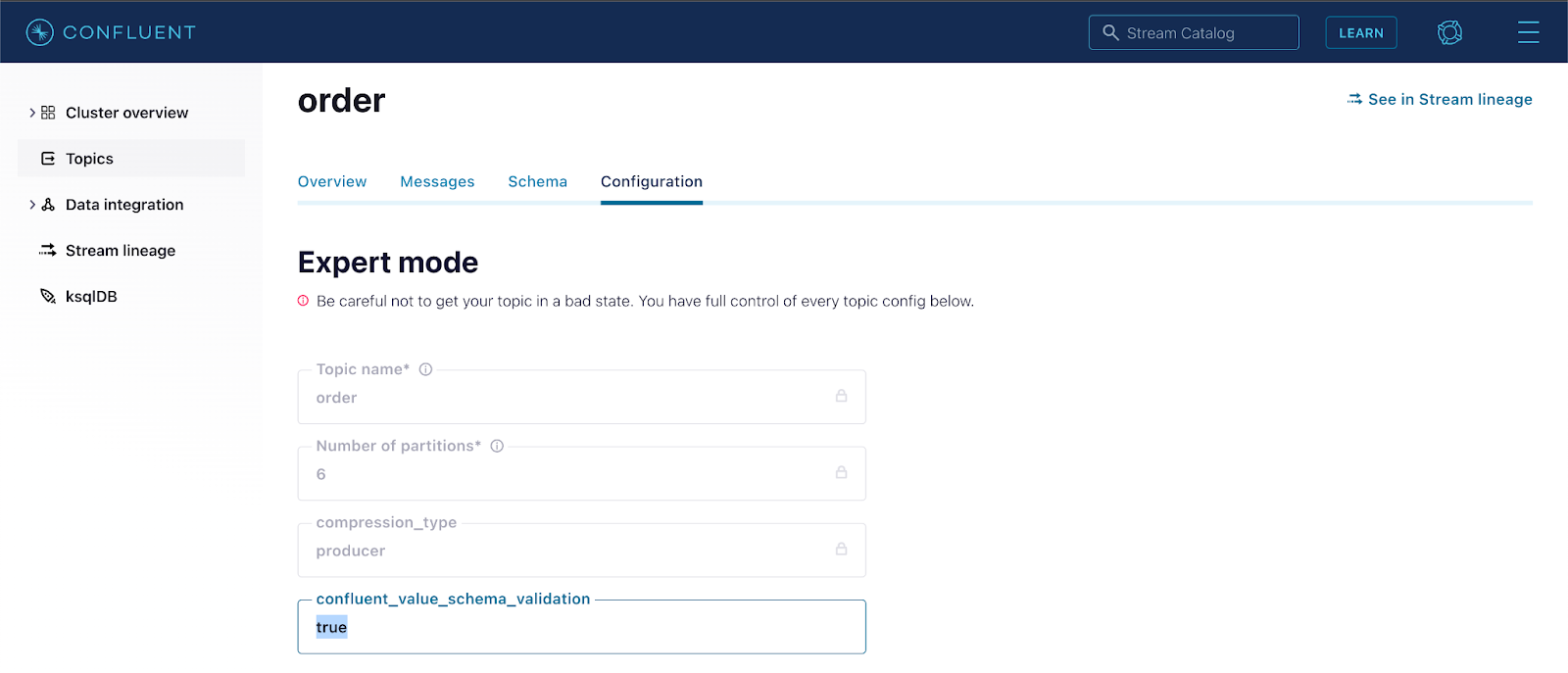
使用Confluent用户界面(Topic → Configuration → Switch to expert mode → confluent_value_schema_validation → true)在主题顺序上启用经纪人方的模式验证。
此外,我们已经做了大量的改进,并在不同的场景下进行了基准测试,以确保这种验证不会对集群性能产生负面影响。我们的测试结果显示,集群的性能开销只有3-4%,对于保证和信任进来的数据是高质量的,而不是可能最终导致系统瘫痪的 "垃圾 "来说,这是一个很小的代价。
总结
我们已经介绍了Confluent的流质量的两个功能。模式注册和模式验证。两者结合在一起,提供了一套强大的工具,以确保在你的Kafka架构中达到高标准的流数据质量。有一个单一的来源来定义你的流数据的数据结构,使你的组织能够在服务之间无缝交换和验证数据。重要的是,随着你的数据的发展,你不必担心你的服务和应用程序会因为模式的差异而崩溃。
