

Hadoop和Redshift的区别
Hadoop是一个由Apache软件 基金会开发的开源框架,其主要优点是可扩展性、可靠性和分布式计算。数据处理、存储、访问和安全是Hadoop生态系统中的几类功能。HDFS具有高吞吐量,这意味着能够以并行处理能力处理大量数据。Redshift是由Amazon.com Inc.内部的Amazon Web Services部门开发的云主机网络服务,是Amazon提供的现有服务之外的。它用于在云中设计大规模的数据仓库。Redshift是一个PB级的数据仓库服务,它是完全管理的,并具有成本效益,可以在大型数据集上运行。
让我们详细研究一下Hadoop和Redshift
Hadoop HDFS具有很高的容错能力,被设计为在低成本的硬件系统上运行。Hadoop可以在其系统内处理最小类型大小为TeraBytes到GigaBytes的文件。HDFS是由名称节点和数据节点组成的主从架构,其中名称节点包含元数据,数据节点包含要处理或操作的真实数据。
RedShift使用不同的数据加载技术,如BI(商业智能)报告、分析工具和数据挖掘。Redshift提供一个控制台来创建和管理亚马逊Redshift集群。Redshift数据仓库的核心组件是一个集群。
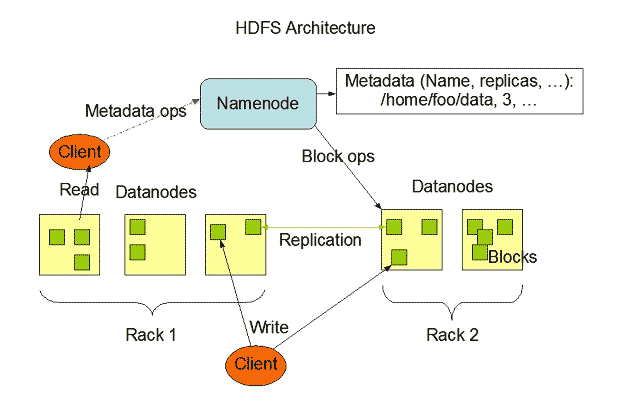
图片来源:Apache.org
RedShift架构
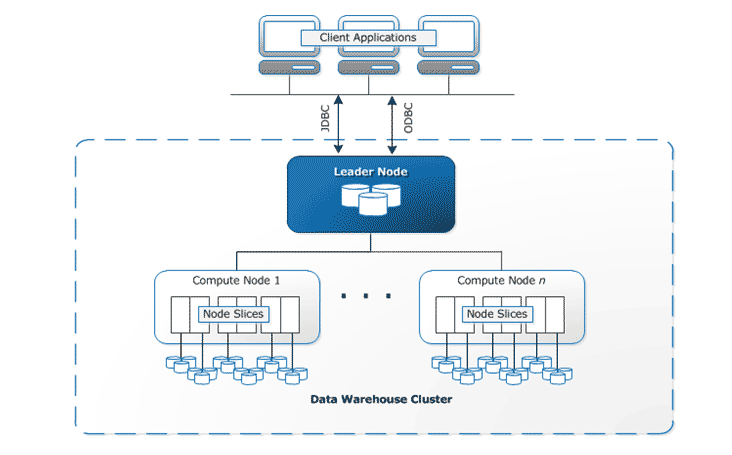 图片来源:Amazon.com
图片来源:Amazon.com
Hadoop和Redshift之间的头对头比较(信息图)。
下面是Hadoop和Redshift之间的10大比较,如下。

Hadoop与Redshift的主要区别
以下是Hadoop与Redshift之间的主要区别如下
1.Hadoop HDFS(Hadoop分布式文件系统)架构有名称节点和数据节点,而Redshift有领导节点和计算节点,其中计算节点将被分割成片状。
2.2.Hadoop提供了一个命令行界面来与文件系统进行交互,而RedShift有一个管理控制台来与亚马逊的存储服务如S3、DynamoDB等进行交互。
3.3.数据库操作需要由开发人员进行配置。Redshift通过解析执行计划来实现数据库操作的自动化。
4.4. Hadoop有几个第三方工具支持,可以很容易地集成,而Redshift只支持亚马逊在其云中开发的产品。
5.5.在Hadoop的架构设计中,网络、存储、安全和性能被认为是主要元素,而在Redshift中,这些元素可以通过亚马逊云管理控制台轻松而灵活地配置起来。
6.6. Hadoop是一个基于Java应用编程接口(API)的文件系统架构,而Redshift则是基于关系模型的数据库管理系统(RDBMS)。
7.7.Hadoop可以与不同的供应商进行整合,而Redshift在这种情况下没有支持,亚马逊是他们唯一的供应商。如果用户对服务不满意怎么办?在这种情况下,Hadoop是一种优势。
8.大多数现有公司仍在使用Hadoop,而新客户则选择RedShift。
9.9.在性能方面,Hadoop总是落后于Redshift,在对大量数据进行查询执行的情况下,Redshift总是胜出。
10.10.Hadoop使用Map Reduce编程模型来运行作业。亚马逊Redshift使用亚马逊的Elastic Map Reduce。
11.Hadoop使用Map Reduce编程模型来运行作业。Amazon Redshift使用Amazon的Elastic Map Reduce。
12.12.Hadoop更适合每天运行批处理作业,这样会更便宜,而Redshift在在线分析处理(OLAP)技术方面更便宜,该技术存在于许多商业智能工具背后。
13.13.Hadoop在运行查询时比Redshift慢10倍,同样,Hadoop的成本比Redshift高10倍,导致Hadoop在Redshift之前是最不受欢迎的。
14.14.在数据加载方面,Hadoop也一直落后于Redshift,系统将数据从存储空间加载到其文件处理系统所需的时间。
15.15.Hadoop可用于低成本存储、数据归档、数据湖、数据仓库和数据分析,而Redshift则属于数据仓库功能,这限制了其多用途的使用。
16.Hadoop平台为各种外部供应商和自己的Apache项目提供支持,如Storm、Spark、Kafka、Solr等,而另一方面,Redshift仅对亚马逊产品提供有限的集成支持。
Hadoop与Redshift对比表
| 比较的基础 比较 | HADOOP | REDSHIFT |
| 可用性 | Apache项目的开源框架 | 亚马逊提供的有价服务 |
| 实施 | 由Hortonworks和Cloudera供应商等提供。 | 由亚马逊开发和提供 |
| 性能方面 | Hadoop MapReduce作业速度较慢 | Redshift的性能比Hadoop集群更快。 |
| 可扩展性 | 可扩展性方面的限制 | 很容易根据需求缩小/扩大规模 |
| 价格 | 运行查询的费用为每月200美元 | 价格取决于服务器的区域,比Hadoop便宜。 例如:20美元/月 |
| 速度 | 与Redshift相比,速度较快,但较慢 | 比Hadoop快10倍 |
| 查询速度 | 运行1.2TB的数据需要1491秒 | 运行1.2TB数据需要155秒 |
| 数据整合 | 灵活使用本地文件系统和任何数据库 | 只能从Amazon S3或DynamoDB加载数据 |
| 数据格式 | 支持所有的数据格式 | 严格的数据格式,如CSV文件格式 |
| 使用的便利性 | 管理活动复杂,处理起来比较麻烦 | 自动备份和数据仓库管理 |
总结
最后总结一下,这次比较的大赢家是Redshift,它在操作、维护和生产力方面胜出,而Hadoop在性能扩展性和服务成本方面有所欠缺,唯一的好处是容易与第三方工具和产品整合。由于Redshift的高可用性和比Hadoop更低的运营成本,它最近一直在发展,并被许多客户和顾客接受,这使得它越来越受欢迎。但是,到目前为止,大多数现有的财富1000强公司都在其架构中使用Hadoop平台来管理客户数据。
在大多数情况下,RedShift一直是任何客户或顾客为商业目的考虑的最佳选择,以处理任何金融机构或公共信息的大型和敏感数据,具有更多的数据完整性和安全性。
除此之外,Hadoop也有自己的优势,它是一个开源项目,并且已经有很多年的历史了,这也导致现有的系统被替换为一个产生成本的过程。最后应该根据需求和灵活性来选择产品,而不是根据驱动的业务需求来定价或普及。
