

XML树简介
树状结构也被称为XML树模型或分层模型。它可以被定义为具有两个额外好处的分层数据结构:列表和属性,通过在需要时对文档的所有部分提供完全真实的访问,简化了XML文档的工作。这种树形结构的数据模型是节点元素的图形表示,以表达它们与树形模式的关系。与其他树不同的是,XML没有即时显示内容,只有结构被显示出来。树状结构有根元素,然后是子元素和子元素。要挑选单个节点或一组节点,最终要使用Xpath.XML树形结构给他们的实现提供了python、C#语言。
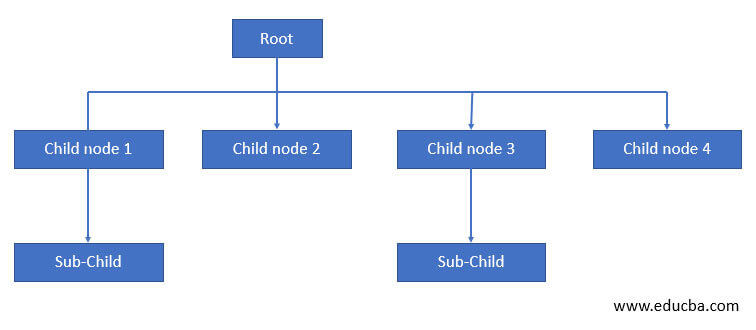
语法
基本的语法结构如下图所示。
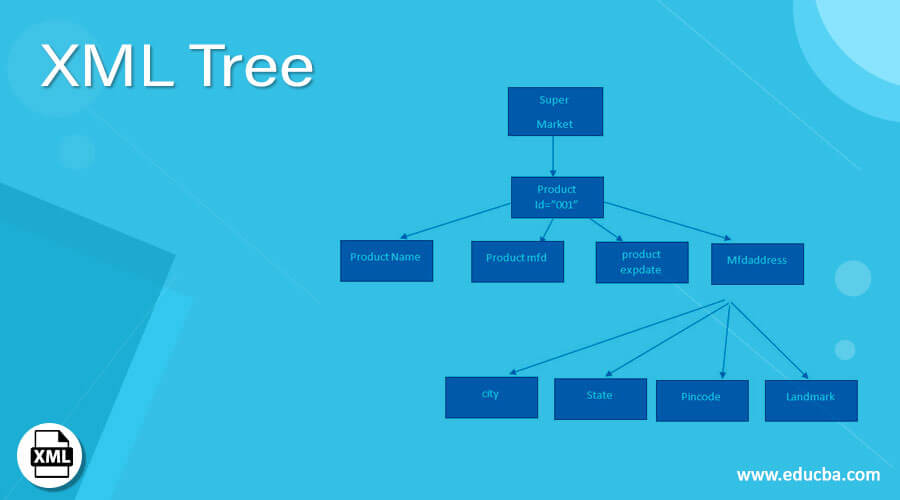
树的工作
树的结构类似于连接树枝和树叶的方式;底层的树结构形成了祖先和后裔的关系。其中,顶级元素被置于根部,子元素与根元素相连,当然形成了元素树。由于树有任意数量的子节点(意味着任何元素都可以有子元素)。再说,特定的子节点可以作为根节点,根节点可以有任意数量的子节点,以此类推直到深度。树形结构使用户能够读取XML格式的数据。为了理解树形结构,有必要阅读基本的XML术语和XML结构。
如何在XML中设计一棵树?
首先,我们将看到一个XML文档,在此基础上,我们可以设计一个树形结构,因为树形结构是对XML语言最好的支持,它有推导位置的能力,有力地结合了分层格式。我们有一些规则来设计XML文档中的结构和两个元素之间的关系。这些规则表述如下。
规则1--子孙。 如果XML元素'X'被另一个元素'Y'所包含,X就是Y的后代。
规则2--祖先。 如果XML元素'X'有元素'Y',那么Y就是X的祖先。
规则3-- 栏目数据中的标签名称应该是相对的。
XML文档的例子
让我们先来看看XML文档的例子
例子1
<?xml version="1.0" encoding="UTF-8"?>
<SuperMarket>
<product id="001">
<productname>fssai dates</productname>
<productmfd> 12 october</productmfd>
<productexpdate> 4 january</productexpdate>
<mfdaddress>
<city>bangalore</city>
<state>karnataka</state>
<pincode>201301</pincode>
<landmark>Near waterpark</landmark>
</mfdaddress>
</product>
</SuperMarket>
在这个例子中,第一行指出XML文档的版本是 "1.0"。所以,这里是根元素,后面有许多子元素。
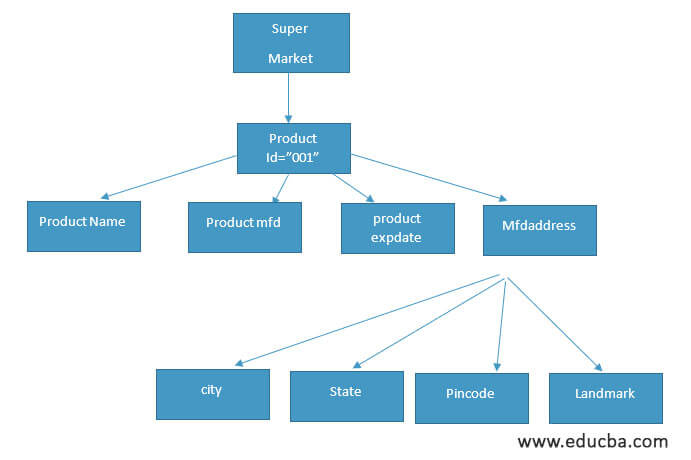
XML树
上述XML文档的树形结构如下所示:根节点是,子元素是,,,和相应的子元素是,,,。
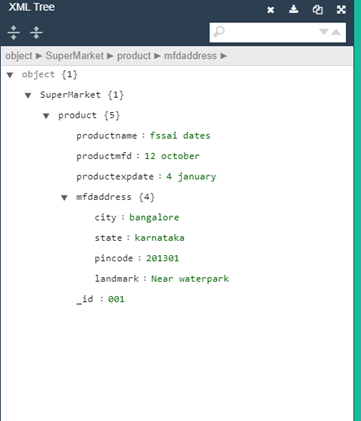
计算机在XML浏览器中生成的XML树
当你点击向下的箭头时,它会详细显示树的子子孙孙。
例子#2
在Xml文档中用属性和值实现。
<?xml version="1.0" encoding="UTF-8"?>
<playstore app="game">
<title>Farmvillie- paris</title>
<developer>leonard britan</developer>
<CEO>mark kevin</CEO>
<released date="feb 23, 2001"></released>
<Music>
<Song no="1" duration="15:22">Wheels on the buse</Song>
<Song no="2" duration="16:25">Baby Shark</Song>
</Music>
</playstore>
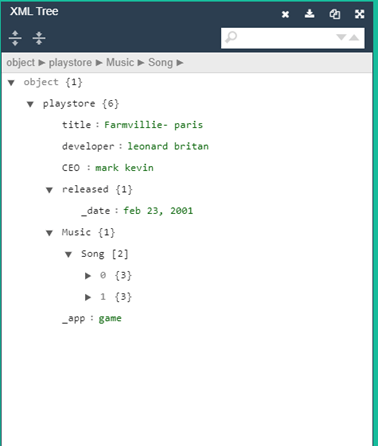
在上面的代码中,是根节点,category type =" game" 是一个节点属性,year date=" Feb 23 2001" 是一个节点值。在这里,游戏ID和歌曲编号都有封闭的文本,并且已知是文本节点。将上述信息以树状格式表示,如。
结果
例子 #3
树的实现示例,通过Java进行解析。
这里我们使用了几个方法来创建元素节点、子节点、文本节点和注释节点,如createElement(),appenrChild(),create TextNode(),这是在一个文本文件中创建的。
import java.io.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import javax.xml.transform.*;
import javax.xml.transform.dom.*;
import javax.xml.transform.stream.*;
public class Main {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory builderFactory =
DocumentBuilderFactory.newInstance();
DocumentBuilder docBuilder =
builderFactory.newDocumentBuilder();
Document dt = docBuilder.newDocument();
new Main().createXmlTree(dt);
}
public void createXmlTree(Document dt) throws Exception {
Element root = dt.createElement("CBSESchool");
dt.appendChild(root);
Element child = dt.createElement("Accrediation");
root.appendChild(child);
Element child1 = dt.createElement("SchoolName");
child.appendChild(child1);
Text text = dt.createTextNode("St.Francis International School");
child1.appendChild(text);
Comment comment = dt.createComment("Faculties in the School");
child.appendChild(comment);
Element element = dt.createElement("Faculties");
child.appendChild(element);
Text text1 = dt.createTextNode("Nithya Ananda");
element.appendChild(text1);
Element chilE = dt.createElement("FID");
chilE.setAttribute("name", "Nithya");
root.appendChild(chilE);
// adding a text element to the child
Text text12 = dt.createTextNode("Qualification");
chilE.appendChild(text12);
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer();
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
StringWriter stw = new StringWriter();
StreamResult res = new StreamResult(stw);
DOMSource src = new DOMSource(dt);
transformer.transform(src, res);
String xmlString = stw.toString();
File file = new File("samplexml.xml");
BufferedWriter buf = new BufferedWriter
(new OutputStreamWriter(new FileOutputStream(file)));
buf.write(xmlString);
buf.flush();
buf.close();
System.out.println("Generated XML file is:\n"
+ xmlString);
}
}
结果
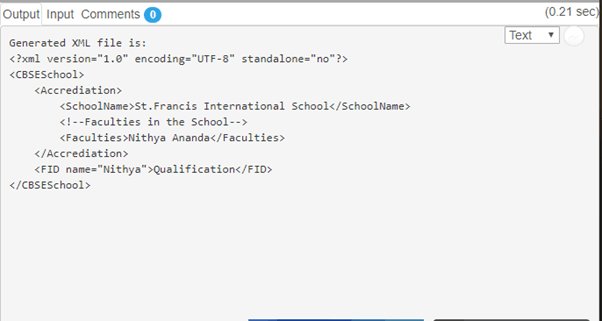
结论
因此,我们已经经历了树,一个家族树,它提供了方便的访问,以灵活的方式操纵树内的数据,因为它提供了在需要时对XML文档中的值的完全访问。它们为今天互联网上使用的各种数据形成了一个巨大的基础。XML文件在保存程序控制方面非常方便,这种树提供了读取XML文件的巨大功能。如果树的结构是恒定的,完整的XML树的结构是彻底的。
