

梯度提升与AdaBoost的区别
Adaboost和梯度提升是机器学习中应用的集合技术类型,用于提高周学习者的效能。提升算法的概念是连续破解预测器,每一个后续模型都试图修复其前任的缺陷。提升算法将许多简单的模型组合成一个复合模型。通过尝试许多简单的技术,整个模型成为一个强大的模型,组合的简单模型被称为周学习者。因此,自适应提升和梯度提升增加了这些简单模型的功效,在机器学习算法中带来了巨大的性能。
梯度提升与AdaBoost之间的正面比较(信息图)
以下是梯度提升与AdaBoost之间的主要区别。
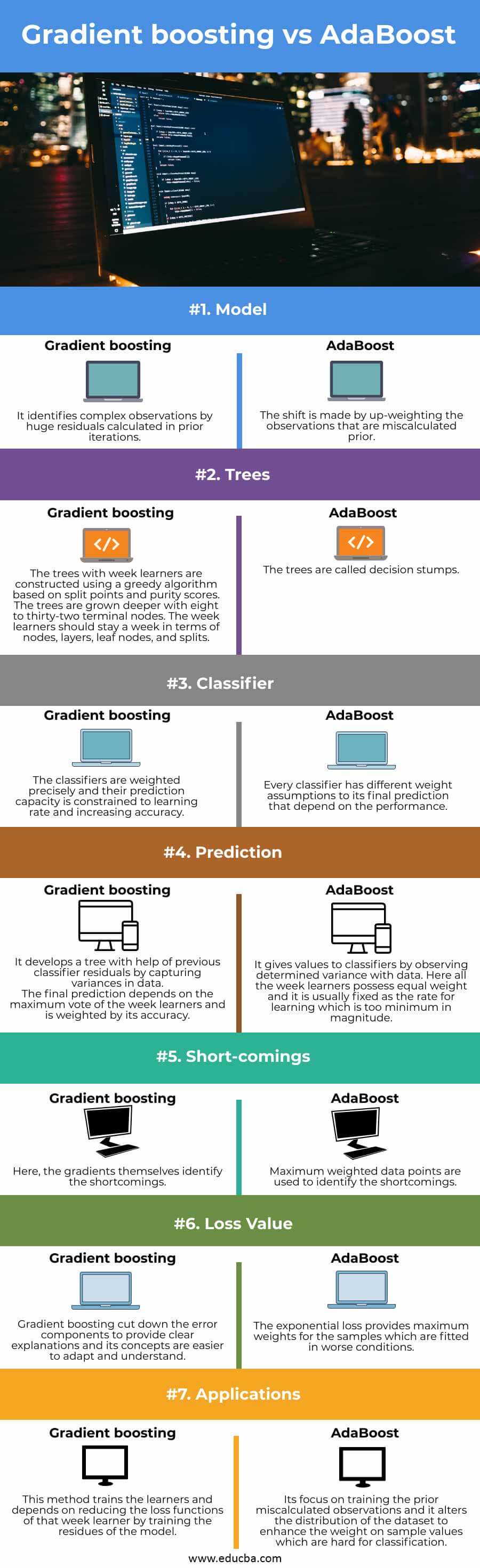
梯度提升和AdaBoost的主要区别
梯度提升法的重要区别将在下面的章节中讨论。
定义。
Adaboost提高了所有可用的机器学习算法的性能,它被用来处理弱的学习者。它获得的准确度刚好高于对问题进行分类的任意几率。AdaBoost中的适应性和最常用的算法是单层的决策树。梯度提升取决于直觉,当与先前的模型相结合时,哪个是下一个合适的可能模型,使累积预测误差最小。梯度提升的关键思想是为下一个模型固定目标结果以减少误差。
原理。
第一个提升集合模型是自适应提升,它将其参数修改为取决于当前迭代的原始性能的数据值。用于重新计算数据值的权重和用于最终组合的权重都是再次反复操作的。在这里,它被用于简单的分类树作为基础学习,与分类的单一基础学习者或一棵树算法相比,它提供了更高的性能。梯度提升结合了提升和梯度下降的思想,形成一个强大的机器学习算法。术语 "梯度 "指的是一个类似函数的双导数或多导数。弱学习者、损失函数和附加模型是梯度提升的三个组成部分。它从数值优化的角度对提升技术进行了直接分析,在一个函数中泛化了它们,使得随机损失函数的优化成为可能。
损失函数
损失函数的测量是为了计算预测模型对其预期值或结果的表现。用户将学习问题改为描述损失函数的优化函数,并再次调整算法以减少损失函数,从而获得更多的准确性。自适应提升方法使指数损失函数最小化,这使算法对其异常值的变化更加深刻。在梯度提升中,与AdaBoost相比,可区分的损失函数对异常值更加敏感。
可操作性。
Adaboost是用一个特定的损失函数来计算的,当涉及到少数迭代时就会变得更加僵硬。但在梯度提升中,由于它是用一些通用的特征建立起来的,所以它有助于找到额外迭代建模问题的适当解决方案。由此可见,与AdaBoost相比,梯度提升法更加灵活,因为它有固定的损失函数值。
优点。
当它隐含在周学习者中时,Adaboost是有效的,当它与少数分类错误有关时,它减少了损失函数。它是针对需要二元分类的问题而开发的,可以用来提高决策树的效率。在梯度提升中,它被用来破解有差异损失函数的问题。在回归问题和分类问题中都可以隐含它。尽管这两种提升技术有一些不同之处,但两者都遵循相似的路径,有相同的历史根源。两者都是通过持续地将注意力转移到对计算和预测具有挑战性的问题注释上,来提升单个学习者的性能。
劣势。
现有的一周学习者可以在梯度提升中找到,在Adaboost中可以找到最大权重的数据点。
Adaboost和梯度提升的比较表
| 特点 | 梯度提升 | Adaboost |
| 模型 | 它通过在先前迭代中计算的巨大残差来识别复杂的观测值 | 通过提高先前计算错误的观测值的权重来实现转变。 |
| 树 | 使用基于分裂点和纯度分数的贪婪算法,构建具有周学习者的树。树的生长深度为8至32个终端节点。周学习者应该在节点、层、叶子节点和分割点方面保持一周的时间 | 这些树被称为决策树桩。 |
| 分类器 | 分类器的权重是精确的,它们的预测能力受制于学习率和增加的准确性 | 每个分类器对其最终的预测都有不同的权重假设,这取决于性能。 |
| 预测 | 它在以前的分类器残余的帮助下,通过捕捉数据中的变异来开发一棵树。 最终的预测取决于一周学习者的最大投票,并以其准确性为权重。 | 它通过观察确定的数据方差来给分类器取值。在这里,所有的周学习者都拥有相同的权重,它通常被固定为学习率,其幅度太小。 |
| 缺点 | 在这里,梯度本身确定了缺点。 | 最大加权的数据点被用来识别缺点。 |
| 损失值 | 梯度提升减少了错误成分,提供了清晰的解释,其概念更容易适应和理解 | 指数损失为在较差条件下拟合的样本提供最大权重。 |
| 应用 | 这种方法训练学习者,取决于通过训练模型的残差来减少该周学习者的损失函数。 | 它的重点是训练事先计算错误的观察结果,它改变了数据集的分布,以提高对难以分类的样本值的权重。 |
结论
因此,当涉及到自适应提升时,该方法是通过提高被误判的先验观察值的权重来完成的,并用于训练模型以获得更多的功效。在梯度提升中,复杂的观测值是由前一次迭代中留下的大量残余物计算出来的,以提高现有模型的性能。
