

Presto与Hive的区别
Apache Hive是一个运行在Apache Hadoop之上的数据仓库解决方案,允许你轻松地查询和分析大数据集。Hive使用类似SQL的方法查询数据,使得探索和分析大量数据变得简单。
Presto是一个分布式SQL查询引擎,可以从Hadoop、S3、MySQL、Teradata以及其他关系型和非关系型数据库中查询数据。Facebook创建的Presto可以对众多数据存储进行查询,响应时间从几分之一秒到几分钟不等。
Apache Hive和Presto都允许企业在业务数据上运行查询,但它们有几个区别性的特征,使它们具有独特性。
1.Hive和Presto之间的内存架构过程
Presto针对延迟进行了优化,而Hive则针对查询吞吐量进行了优化。Presto对查询中的每个任务所能容纳的内存有一个限制,因此如果一个查询需要大量的内存,查询就会失败。对于交互式查询来说,这样的错误处理逻辑(或缺乏这样的逻辑)是没有问题的;但是,对于必须可靠执行的每日/每周报告来说,这就不一样了。对于这样的活动,Hive是一个更好的选择。
Hive使用MapReduce。MapReduce中的每个操作都需要写入磁盘,而且每个阶段都必须等待前一个阶段完成后才能继续进行。因为MapReduce可以在众多服务器上处理任务,所以它在Hive中运行良好。通过分配任务,可以提高项目的速度。即使如此,数据还是必须写到磁盘上,这可能会刺激一些用户。
当Presto将SQL翻译成阶段时,每个阶段由众多任务执行,每个任务被分割成几个分片。所有的任务都是并行完成的,数据在各阶段之间通过管道发送。跨网络的内存-对内存也被用来传输数据,消除了对磁盘输入-输出事务的需求。
正因为如此,Presto的性能比Hive的性能快5-10倍。
2.ANSI SQL和名为HiveQL的类SQL语言
尽管Apache Hive利用的语言与SQL很接近,但有足够的差异,新用户必须重新训练一些查询。HiveQL,即Hive查询语言,包含一些古怪的东西,可能会让新人感到困惑。另一方面,任何熟悉SQL的人都应该能够很快掌握HiveQL。
当许多数据工程师第一次尝试Presto时,他们首先注意到的是,他们可以使用现有的SQL技能。Presto使用普通的SQL来执行查询,检索数据,并修改数据库中的数据。如果你懂得SQL,你可以马上开始使用Presto。许多人认为这是个好处。
3.扩展数组和地图
LATERAL VIEW(在Hive中)语句在与用户定义的表生成函数(如explode())一起使用时,会将列的地图或数组类型扁平化。通过LATERAL VIEW,explode函数可以同时用于ARRAY和MAP。
UNNEST可以用来扩展MAP或ARRAY。数组被折叠成一列,而地图被分成两列(键,值)。UNNEST通常与JOIN一起使用,它可以与连接左侧的关系中的列相关联。
Hive查询
SELECT student, mark
FROM tests
LATERAL VIEW explode(marks) t AS mark;
Presto查询
SELECT student, mark
FROM tests
Cross Join UNNEST explode(marks) t AS mark;
4.自定义代码插件
由于Presto是基于SQL的,你已经有了所有你需要的命令。一些工程师认为这是一个好处,因为它允许他们轻松检索和修改数据。
然而,不能插入自定义代码会给大数据专家用户带来问题。在这种情况下,Hive比Presto有一个优势。如果你对语言很了解的话,你可以把自定义代码放到你的查询中。这不是你一直需要做的事情,但在你做的时候会很方便。
5.Presto查询的小时限制
运行超过48小时的Presto查询将被立即终止。运行超过一两天的Presto查询通常是不成功的查询。
对于长期运行的查询,你可以将Presto查询重建为一个Hive查询。
6.列名转义
当一个列的名称与一个保留关键字的名称相匹配时,该列的名称必须被加引号。在Hive中,像大多数基于SQL的查询语言一样,引号字符是反斜线字符`。在Presto中,双引号字符""代替了"`",被用来引用列名。请看下面的例子。
SELECT `join` FROM Demo # Hive
SELECT "join" FROM Demo # Presto
7.数据限制
不幸的是,Presto作业所能存储的数据量是有限的。一旦你遇到这堵墙,Presto的理由就崩溃了。你几乎可以依靠Presto来很好地生成每小时或每天的报告。请记住,Facebook利用Presto,创造了大量的数据。然而,有一个限制。
Hive似乎没有任何数据限制,至少没有与现实世界场景相关的限制。对于制作周报或月报的企业来说,Hive是首选的数据查询解决方案。如果涉及到大量的数据,该项目将花费更长的时间。另一方面,Hive不会失败。它将继续工作,直到完成你所有的命令。
Presto与Hive的比较(信息图表)
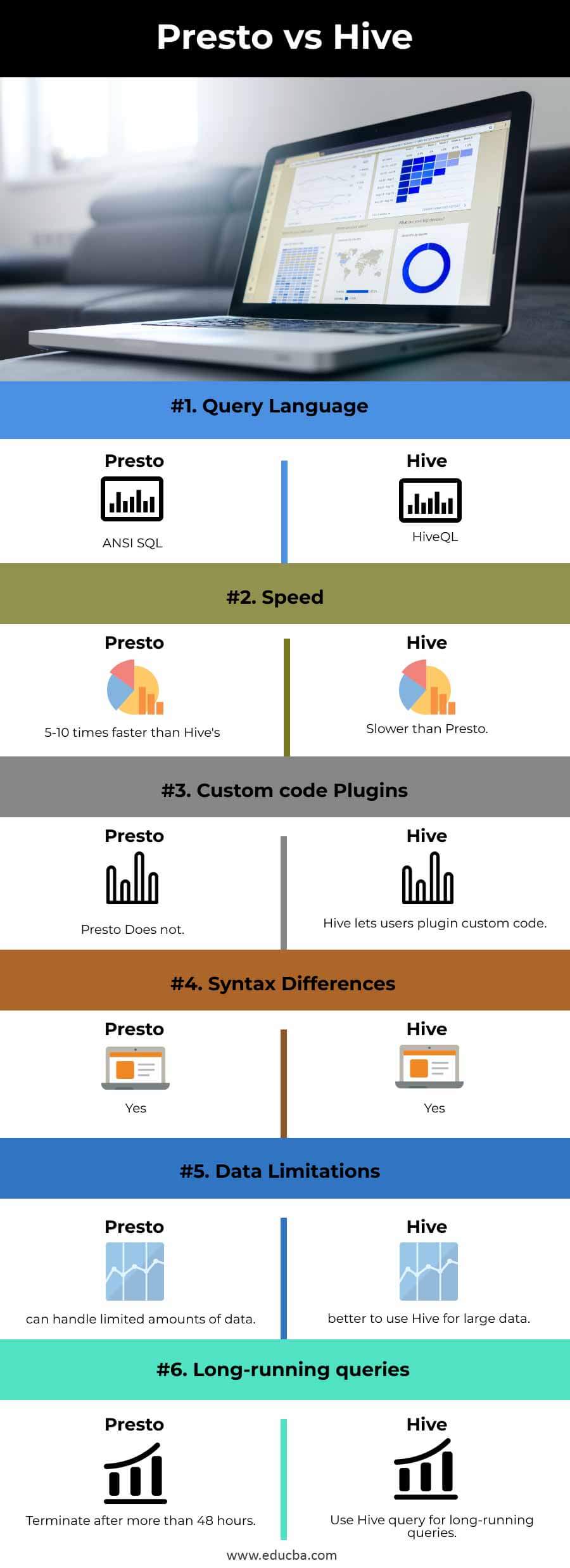
下面是Presto与Hive的主要区别。
主要区别
- Presto不允许用户插入自定义代码,但Hive允许。
- Presto使用ANSI SQL,而Hive使用HiveQL
- Presto只能处理有限的数据量,因此对于较大的数据,建议使用Hive。
Hive与Presto的比较表
| 基础 | 蜂巢 | 普雷斯托 |
| 查询语言 | ANSI SQL | HiveQL |
| 速度 | 比Hive的速度快5-10倍 | 比Presto慢 |
| 自定义代码插件 | Presto 没有 | Hive允许用户插入自定义代码 |
| 语法差异 | 有 | 有 |
| 数据限制 | 可以处理有限的数据量 | 最好使用Hive来处理大数据 |
| 长时间运行的查询 | 超过48小时就会终止 | 使用Hive查询长期运行的查询。 |
结论 - Presto vs Hive
仅仅因为有些人喜欢Hive,这并不意味着你应该忽视Presto。如果运用得当,它的表现是令人钦佩的。Presto是一个能迅速工作的任务处理系统。只是不要一下子给它施加太多的压力。如果你这样做,你就会面临失败的机会。另外,Apache Hive和Presto都是开源工具,所以每一个的源代码都是免费提供的。
