

尽管SQL为我们提供了防止重复数据的约束条件,但你可能会遇到一个已经存在的数据库有重复记录的情况。
使用本教程,你将发现如何识别数据库中的重复行。
SQL查找重复数据
我们可以使用的第一个方法是计数函数来查找重复的行。
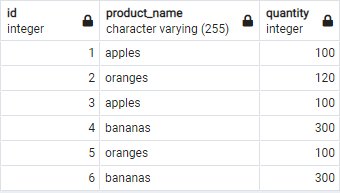
假设我们有一个包含样本数据的表,如图所示。
CREATE TABLE products(
id serial,
product_name VARCHAR(255),
quantity INT
);
INSERT INTO products(product_name, quantity)
VALUES ('apples', 100),
('oranges', 120),
('apples', 100),
('bananas', 300),
('oranges', 100),
('bananas', 300);
上述查询应返回如图所示的表格。
为了过滤重复的记录,我们可以使用如下所示的查询。
SELECT PRODUCT_NAME,
QUANTITY
FROM PRODUCTS
GROUP BY PRODUCT_NAME,
QUANTITY
HAVING COUNT(ID) > 1;
上面的查询使用group by和count函数来搜索重复的记录。这应该返回如图所示的输出。
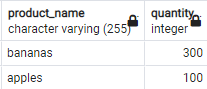
上面的查询是通过创建一个具有相同值的记录组来实现的。这是用group by子句完成的。然后我们找出哪些组的计数大于1,这意味着该组中存在重复记录。
终止
在这篇文章中,你发现了如何使用group by和count子句在SQL中找到重复的记录。
谢谢你的阅读!!
