

pandas describe()函数允许你获得Pandas数据框架内的数据的统计摘要。该函数返回数据的统计信息,包括统计平均值、标准差、最小和最大值等。
函数语法
该函数的语法如下所示。
DataFrame.describe(percentiles=None, include=None, exclude=None, datetime_is_numeric=False)
函数参数
该函数接受以下参数。
- percentiles- 允许你在DataFrame中获得数据的特定百分位数。百分位数的范围是0到1。
- include- 指定一个数据类型的列表,在结果集中有接受的值,包括None和all。
- exclude- 在结果集中要排除的数据类型的列表。
- datetime_is_numeric- 允许函数将日期时间对象视为数字。
函数的返回值
该函数返回一个DataFrame,每一行都持有列的统计属性的类型。
例子1
请看下面的例子,它说明了潘达斯中describe()函数的主要用途
import pandas as pd
df = pd.DataFrame({
"first_name": ['Fracis', 'Bernice', 'Debra'],
"last_name": ['Barton', 'Wyche', 'Wade']},
index=[1,2,3])
df.describe()
在上面的例子中,我们先是导入了pandas库。然后我们创建了一个简单的DataFrame并调用describe()方法。
上面的代码应该返回一个关于DataFrame的基本信息摘要。一个输出示例如图所示:
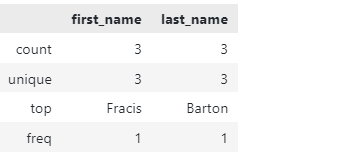
注意该函数是如何返回基本的统计信息的,比如值的数量,有多少是唯一的,最高值等等。
例子2
考虑一下下面的例子,返回一个Pandas系列的统计摘要。
s = pd.Series([10,20,30])
s.describe()
在这个例子中,函数应该返回如图所示的输出:

在这种情况下,函数返回基本的摘要信息,如标准平均值、第25、50和75个百分位数,以及系列中的最大值。
例子3
要描述Pandas DataFrame中的一个特定列,请使用如下所示的语法。
DataFrame.column_name.describe()
例子4
要从结果中排除一个特定的数据类型,请使用所示的语法。
df.describe(exclude=[np.datatype])
例子5
要描述一个DataFrame中的所有列,无论其数据类型如何,运行代码。
df.describe(include='all')
总结
在这篇文章中,我们讨论了如何在Pandas中使用describe()函数。
