

在本教程中,我将向你展示如何使用Sklearn train_test_split函数,将机器学习数据分成训练集和测试集。
我将回顾该函数的作用,解释其语法,并展示一个如何使用它的例子。
如果你需要具体的东西,只需点击下面适当的链接。 该链接将带你到本教程的特定部分。
目录
Sklearn训练-测试分割的快速介绍
Sklearn train_test_split函数将一个数据集分割成训练数据和测试数据。
让我们快速回顾一下机器学习的过程,以便你理解我们为什么要这样做。
机器学习通常需要训练数据和测试数据
机器学习算法是一种算法,当我们把它们暴露在数据中时,它们的性能会得到改善。
因此,当我们建立一个机器学习模型时,我们通常需要将一个数据集送入机器学习算法。
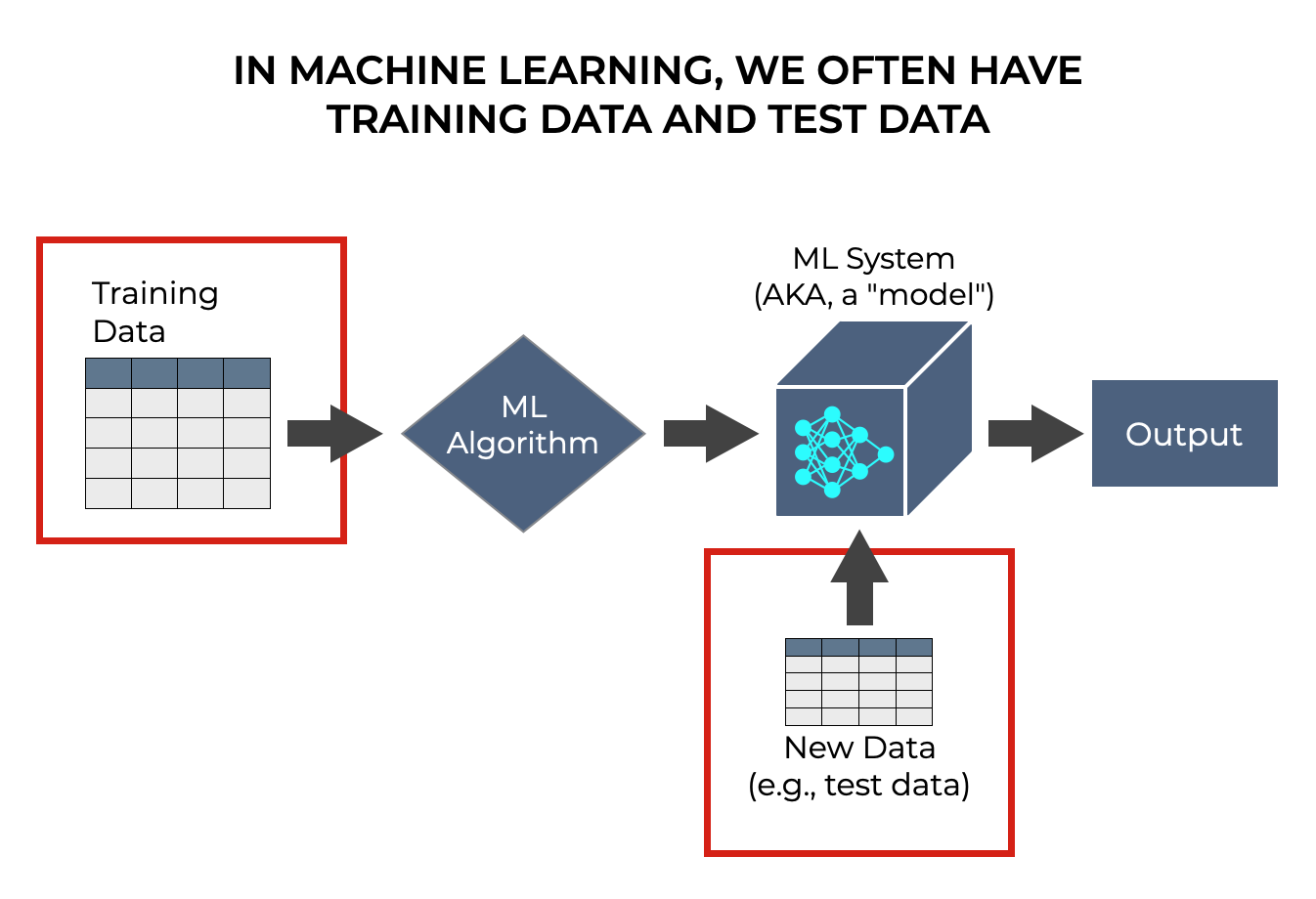
这个最初被我们送入机器学习算法以 "训练 "算法的数据集,通常被称为训练数据集。 训练数据集被专门用作输入,以帮助算法 "学习"。
但通常,我们也有一个所谓的 "测试 "数据集。 在模型建立后,我们使用测试数据集作为模型的输入,以 "测试 "模型是否按需要工作。
因此,当我们建立一个机器学习模型时,我们通常需要一个训练数据集和一个测试数据集。
Sklearn train_test_split 分割了一个数据集
当我们在Python中建立机器学习模型时,Scikit Learn包给了我们一些工具来执行常见的机器学习操作。
其中一个工具就是train_test_split函数。
Sklearn train_test_split函数帮助我们创建训练数据和测试数据。
这是因为通常情况下,训练数据和测试数据都来自同一个原始数据集。
为了得到建立模型的数据,我们从一个数据集开始,然后把它分成两个数据集:训练和测试。
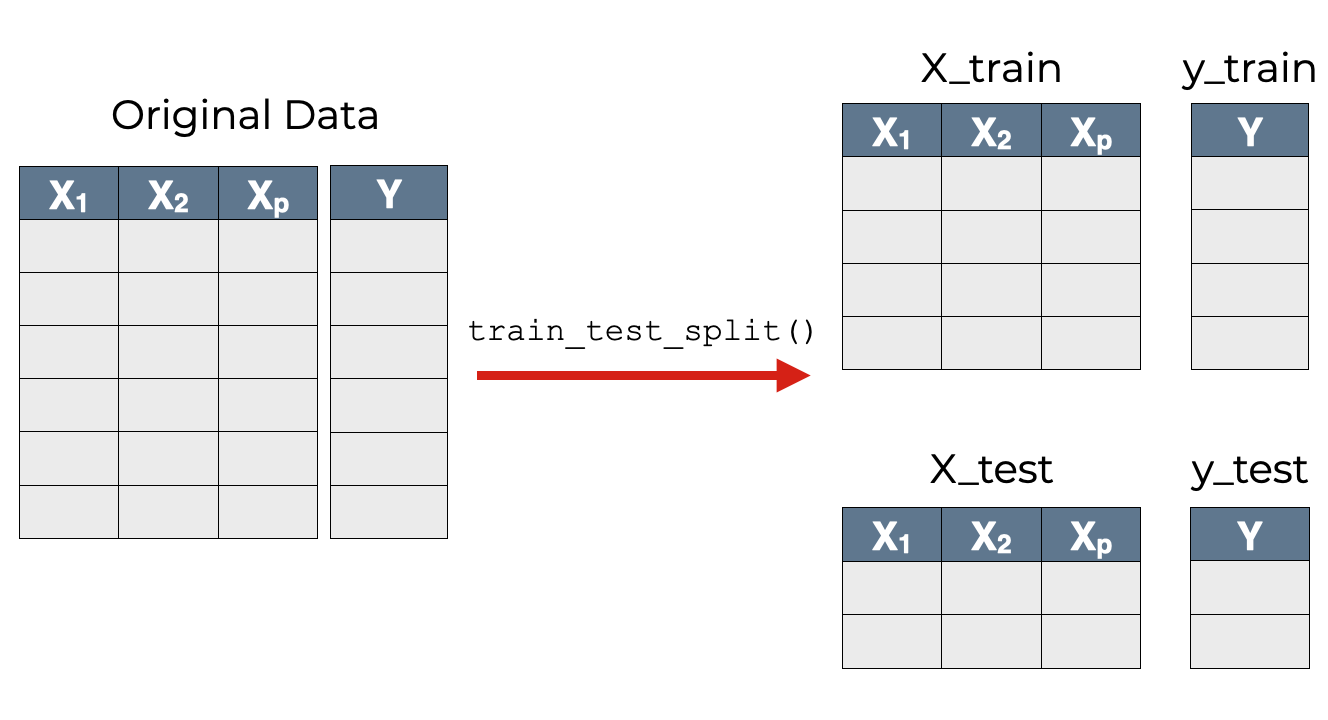
因此,scikit learn train test split函数使我们能够将一个数据集分成训练数据和测试数据。
说了这么多,该函数如何工作取决于你给它的输入数据,以及如何使用语法中的可选参数。
既然如此,我们来看看语法。
Sklearn train_test_split的语法
在这里,我将解释Scikit Learn train test split函数的语法。
在我们继续之前,请记住,要使用这个函数,你需要先导入它。 你可以用下面的代码来做。
from sklearn.model_selection import train_test_split
train_test_split 语法
如果我们已经如上图所示导入了这个函数,我们就以train_test_split() 的方式调用这个函数。
在括号内,我们将提供 "X" 输入数据的名称作为第一个参数。 这个数据应该包含特征数据。 作为选择,我们还可以提供包含标签或目标数据集的"y"数据集的名称(这在我们使用监督学习时很常见)。
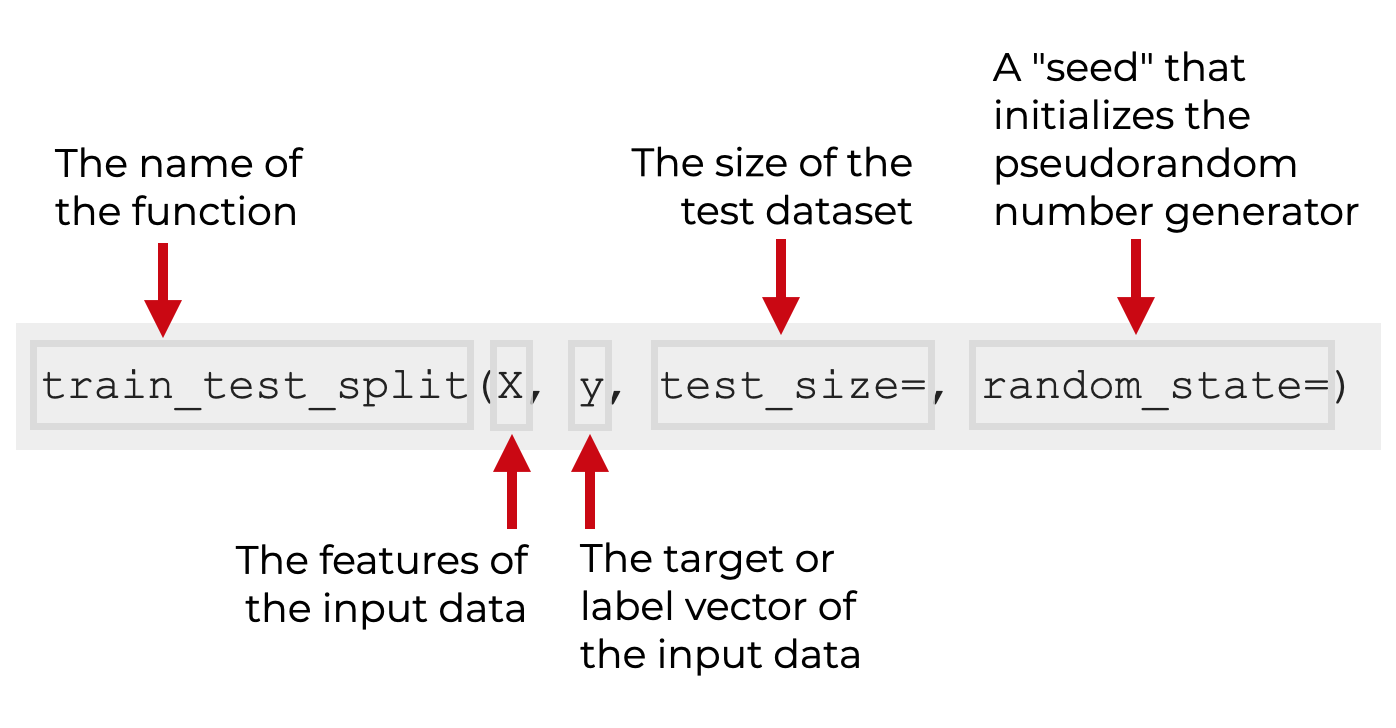
此外,还有几个可选的参数,我们可以用它们来控制函数的具体方式。
让我们更仔细地看一下这些参数。
train test split的参数
train/test split函数有几个重要的输入和参数
Xytest_sizerandom_stateshufflestratify
让我们来看看其中的每一个。
X (必填)
X 参数是一个输入数组,包含特征数据(即你想用来建立模型的变量/列。
这通常是一个Numpy数组,但该函数也允许其他结构,如Python列表。
这个对象应该是二维的,所以如果它是一个一维的Numpy数组,你可能需要重新塑造你的数据。 这通常是通过代码.reshape(-1,1) 来完成的。
y
y 参数通常包含目标值的向量(即你数据的目标或标签)。
这通常是一个一维的Numpy数组,尽管该函数也允许二维数组和列表。
如果它是一个一维的对象,它的长度应该与X 中的行数相同。或者如果它是二维的,它的行数应该和X 。
additional arrays
尽管我们通常在一个或两个输入数组(X 和y )上使用 train_test_split ,但从技术上讲,该函数会对多个数组进行操作。
如果你需要分割许多数组,你可以在X 和y 之外提供它们。
test_size
test_size 参数使你可以指定输出测试集的大小。
作为这个参数的参数,你可以提供一个整数,或者一个浮点数。
如果参数是一个整数,测试集的大小将等于这个数字。
如果参数是一个浮点数,它必须在0和1之间,这个数字将代表测试集中的观察值的比例。(注意:这可能是使用该参数的最常见方式)。
random_state
random_state 参数控制伪随机数生成器如何随机地选择观测值进入训练集或测试集。
如果你提供一个整数作为这个参数的参数,那么train_test_split将在分裂前以相同的顺序洗刷数据,每次你使用这个函数时,都会使用同一个整数。
实际上,如果你为这个参数提供一个整数,它将使你的代码在函数的每次调用中都是完全可重复的。
shuffle
shuffle 参数控制输入数据集在被分割成训练和测试数据之前是否被随机洗牌。
默认情况下,这个参数被设置为shuffle = True 。这意味着,默认情况下,数据在拆分前被洗成随机顺序,所以观测值将被随机分配到训练和测试数据中。
如果你设置shuffle = False ,随机排序将被关闭,数据将按照数据已经存在的顺序进行分割。
如果你设置了shuffle = False ,那么你必须设置stratify = None 。
stratify
shuffle 参数控制数据是否以分层的方式进行分割。
默认情况下,它被设置为stratify = None 。
输出的格式
输出将是训练和测试数据集,其中输入数据的观测值已经被分配到训练集和测试集。
输出对象是Numpy数组。
输出的数量将等于输入数量的2倍。 因此,如果你只向函数提供一个X输入,将有两个输出(X_train和X_test)。 如果你向函数提供一个X和Y的输入,将有四个输出(X_train、X_test、y_train和y_test)。
输入数据的格式
在我们继续之前,有一个最后的说明。
对于Scikit learn中的大多数工具,我们需要有2维的特征数据。
例如,当我们使用Sklearn fit方法或Sklearn predict方法时,X数据需要有一个二维结构。
在这种情况下,在你将X数据放入train_test_split之前,将其结构化为二维格式通常是很有用的。 如果你这样做了,那么你的X_train和X_test都会有正确的二维结构,并为其他Sklearn工具做好准备。
例子:如何使用Sklearn train_test_split
现在我们已经看了train_test_split的语法,让我们看看一些例子。
例子
运行设置代码
在我们使用训练/测试分割函数之前,我们需要运行一些设置代码。
具体来说,我们需要
- 导入scikit-learn和其他软件包
- 创建一个数据集
让我们快速完成这些。
导入Scikit Learn和其他包
首先,我们需要导入Numpy、Seaborn,以及train_test_split(来自Scikit Learn)。
from sklearn.model_selection import train_test_split
import numpy as np
import seaborn as sns
我们显然需要train_test_split函数来分割我们的数据。
但我们也会使用Numpy和Seaborn。 我们将使用Numpy来创建一个模拟数据集,我们将使用Seaborn来简单地绘制数据。
创建训练数据
接下来,让我们创建一个我们可以使用的模拟数据集。
在这里,我们将创建一个有两个变量的数据集。 这些变量将是线性相关的,其中有一点随机的噪音。
我们将使用Numpy linspace来创建我们的X轴变量。 这个变量将有100个均匀分布的值,从1到99。
y轴变量将等于x轴变量,并加入一点随机的正态噪声,由Numpy随机正态生成。
注意,我们还将使用np.random.seed来设置随机数发生器的种子。
observation_count = 100
x_var = np.linspace(start = 1, stop = 100, num = observation_count)
np.random.seed(22)
y_var = x_var + np.random.normal(size = observation_count, loc = 10, scale = 20)
一旦你运行了这段代码,你会有两个变量。
- x_var
- y_var
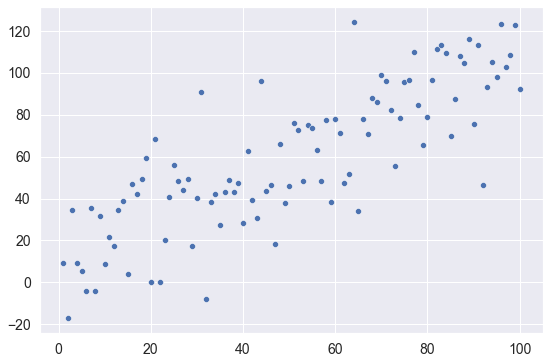
让我们用Seaborn绘制它们。
sns.scatterplot(x = x_var, y = y_var)
输出
重塑x变量
在我们做例子之前,还有一件事。
通常,当我们使用Scikit Learn时,"X "数据(即特征)需要被结构化为一个二维数组。
我们刚刚创建的X变量,x_var ,是一维的。 这种一维格式在train_test_split中可以使用,但是如果你想把它用于其他工具,比如sklearn fit和sklearn predict,就会有问题。
因此,在这里,我们将把x_var 重塑为二维格式。
x_var_2d = x_var.reshape(-1,1)
现在我们有了一些数据,我们可以将其分割并用于Scikit Learn。
例子1:简单的数据分割,使用默认参数
我们将从最简单的例子开始。
在这里,我们将用train_test_split() ,用默认参数来分割我们的数据。
该函数的唯一输入将是x_var_2d 和y_var 。
(X_train, X_test, y_train, y_test) = train_test_split(x_var_2d, y_var)
解释
请注意,这段代码创建了4个输出数据集。
X_trainX_testy_trainy_test
原始数据有100个观察值,但是这些新的数据集包含了x_var_2d 和y_var 的子集。
具体来说,X_test 和y_test 分别包含原始数据中25%的x和y行。 这是因为在默认情况下,train_test_split 将数据分割成75%的训练数据和25%的测试数据。
但是,我们可以通过test_size 参数来改变这一点。
实例2:创建一个具有特定测试规模的分割数据
在这里,我们要创建一个训练/测试分割,在测试数据中要有特定比例的观察值。
要做到这一点,我们将使用test_size = .2 ,它将把20%的观测值分配给测试集。
(X_train, X_test, y_train, y_test) = train_test_split(x_var_2d, y_var, test_size = .2)
解释
再一次,Sklearn train_test split函数创建了4个数据集。X_train,X_test,y_train, 和y_test 。
请记住,原始输入数据有100个观测值。
如果我们检查y_test 数据集,我们会发现它有20个观测值。
y_test.size
输出
20
这是有道理的。 我们设置test_size = .2 ,所以20%的数据(100个观测值中的20个)被分配到测试集。
实例3:使用random_state来进行可重复的分割
最后,让我们创建一个 "可重复 "的训练/测试分割。
如果你运行前面一个例子中的代码,然后再次运行该代码,你会注意到输出数据集中的确切观测值会发生变化。
这是因为train_test_split将数据行分配到输出randomly 。因此,每次你用默认设置运行train_test_split时,输出数据将包含从输入数据中随机选择的观测值。
有时候,这没什么问题。
但是,有时候,我们希望我们的代码是完全可重复的。 因此,例如,出于训练和测试的目的(即与学生或新同事分享代码),我们希望输出结果是相同的,这使得我们更容易验证代码是否正常工作。
如果你想在Scikit Learn中做到这一点,那么你希望在你的数据中拥有相同的训练/测试分割。
为了创建这样一个可重复的训练/测试分割,你可以使用随机状态。
(X_train, X_test, y_train, y_test) = train_test_split(x_var_2d, y_var, random_state = 22)
解释
在这里,我设置了random_state = 22 。
我建议在运行代码后,打印出其中一个数据集的观察结果。
print(y_test)
输出
[ 34.63583358 46.12242594 113.13776798 -7.80060786 42.98140927 34.75504429 104.59206851 30.84326284 92.33713696 87.52333107 96.71044417 20.07852775 110.1999608 75.90678294 77.69534726 90.98353281 63.28392045 42.04873081 73.64578603 9.1610016 78.56890633 18.53540289 96.4100534 44.26118189 82.23007252]
所以这里我们有了y_test 中的y值。
但是现在,再次运行train_test_split,用同样的随机状态。
(X_train, X_test, y_train, y_test) = train_test_split(x_var_2d, y_var, random_state = 22)
print(y_test)
输出
[ 34.63583358 46.12242594 113.13776798 -7.80060786 42.98140927 34.75504429 104.59206851 30.84326284 92.33713696 87.52333107 96.71044417 20.07852775 110.1999608 75.90678294 77.69534726 90.98353281 63.28392045 42.04873081 73.64578603 9.1610016 78.56890633 18.53540289 96.4100534 44.26118189 82.23007252]
你会注意到,如果我们用同样的随机状态运行train_test_split,我们会在输出中得到完全相同的观察结果。
这是因为 train_test_split 是伪随机的。 它是随机的......但是如果我们使用相同的值random_state ,它将产生完全相同的输出。
如果你仍然对此感到困惑,我建议你阅读我们关于Numpy随机种子的教程,它更深入地解释了伪随机数生成器。
在本教程中,我已经向你展示了如何使用Sklearn训练-测试分割功能。
