

agg 这个名字是聚合的简称。聚合就是将许多观察值汇总成一个单一的值,代表观察数据的某个方面。
.agg() 函数可以处理一个数据框架、一个系列或一个分组的数据框架。它可以执行许多聚合函数,例如:'[mean](https://blog.finxter.com/pandas-dataframe-mean-method/)', '[max](https://blog.finxter.com/pandas-dataframe-max-method/)',......在一次调用中沿着其中一个轴。它还可以执行lambda函数。请继续阅读例子。
我们将使用一个FIFA球员的数据集。在这里可以找到这个数据集。
使用Jupyter笔记本的基本设置
让我们从导入pandas和加载我们的数据集开始。
import pandas as pd
df_fifa_soccer_players = pd.read_csv('fifa_cleaned.csv')
df_fifa_soccer_players.head()

为了提高可读性,我们将使用数据的一个子集。让我们通过选择我们想要在子集中的列来创建子集,并创建一个新的数据框架。
df_fifa_soccer_players_subset = df_fifa_soccer_players[['nationality', 'age', 'height_cm', 'weight_kgs', 'overall_rating', 'value_euro', 'wage_euro']]
df_fifa_soccer_players_subset.head()

基本聚合
Pandas提供了各种内置的聚合函数。例如,pandas.DataFrame.describe 。当应用于一个数据集时,它会返回一个统计值的摘要。
df_fifa_soccer_players_subset.describe()

为了理解聚合以及为什么它有帮助,让我们仔细看看返回的数据。
例子。我们的数据集包含17954名球员的记录。最年轻的球员是17岁,最年长的球员是46岁。平均年龄为25岁。我们了解到,最高的球员身高为205厘米,平均身高为175厘米左右。通过一行代码,我们可以回答关于我们数据的各种统计问题。describe 函数识别了数字列并为我们进行了统计汇总。Describe还排除了包含字符串值的列nationality 。
聚合就是将许多观察值总结成一个单一的值,代表观察数据的某个方面。
Pandas为我们提供了各种预建的聚合函数。
| 函数 | 说明 |
mean() | 返回一组数值的平均值 |
sum() | 返回一组数值的总和 |
count() | 返回一组数值的计数 |
std() | 返回一组数值的标准偏差 |
min() | 返回一组数值中最小的值 |
max() | 返回一组数值的最大值 |
describe() | 返回一组数值的统计值的集合 |
size() | 返回一组数值的大小 |
first() | 返回一组数值的第一个值 |
last() | 返回一组数值的最后一个数值 |
nth() | 返回一组数值的第n个数值 |
sem() | 返回一组数值的平均值的标准误差 |
var() | 返回一组数值的方差 |
nunique() | 返回一组数值的唯一值的数量。 |
让我们使用上面列表中的另一个函数。我们可以更具体一些,要求 "value_euro"系列的 "sum"。这一列包含一个球员的市场价值。我们选择列或系列 'value_euro' 并执行预先建立的sum() 函数。
df_fifa_soccer_players_subset['value_euro'].sum()
# 43880780000.0
Pandas向我们返回了所要求的值。让我们来了解一个更强大的pandas方法来聚合数据。
pandas.DataFrame.agg' 方法
函数语法
.agg() 函数可以接受许多输入类型。输出类型在很大程度上是由输入类型决定的。我们可以向.agg() 函数传入许多参数。
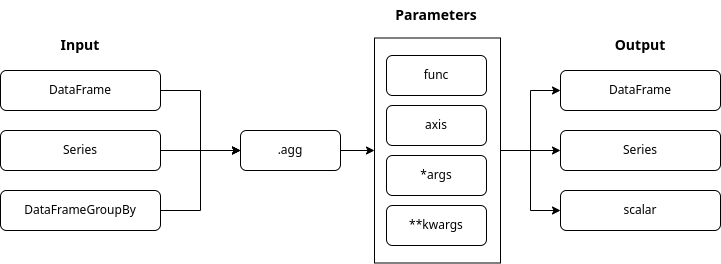
"func" 参数。
- 默认设置为
**None** - 包含一个或多个聚合数据的函数
- 支持预先定义的pandas聚合函数
- 支持lambda表达式
- 支持
[dataframe.apply()](https://blog.finxter.com/pandas-apply-a-helpful-illustrated-guide/)方法,用于特定的函数调用
"axis" 参数。
- 默认设置为0 ,将函数应用于每一列
- 如果设置为1,则将函数应用于行
- 可以持有值。
0或 ' 'index1或 ' 'columns
那么*args 和**kwargs:
- 我们使用这些占位符,如果我们事先不知道我们需要向函数传递多少个参数的话
- 当参数的类型相同时,我们使用
*args - 当参数的类型不同时,我们使用
**kwargs。
系列上的Agg方法
让我们看看.agg() 这个函数的运行情况。我们为'wage_euro'系列请求一些预建的聚合函数。我们使用函数参数并提供我们想要执行的聚合函数作为一个列表。并且让我们把得到的系列保存在一个变量中。
wage_stats = df_fifa_soccer_players_subset['wage_euro'].agg(['sum', 'min', 'mean', 'std', 'max'])
print(wage_stats)

Pandas使用科学符号来表示大大小小的浮点数。为了将输出转换为熟悉的格式,我们必须将浮点数移到右边,如加号所示。加号后面的数字代表了步数的多少。
让我们一起对一些数值进行操作。
所有工资的总和是175,347,000欧元(1.753470e+08)
工资的平均值是9902.135欧元(9.902135e+03)。
我们在一个系列输入源上执行了许多函数。因此,我们的变量 'wage_stats' 属于Series 类型,因为。
type(wage_stats)
# pandas.core.series.Series
请看下面如何从变量和返回的数据类型中提取,例如,'min'值。
wage_stats_min = wage_stats['min']
print(wage_stats_min)
# 1000.0
print(type(wage_stats_min))
# numpy.float64
现在的数据类型是一个标量。
如果我们在同一个数据源(系列)上执行一个函数,返回的类型是一个标量。
wage_stats_max = df_fifa_soccer_players_subset['wage_euro'].agg('max')
print(wage_stats_max)
# 565000.0
print(type(wage_stats_max))
# numpy.float64
让我们再用一个例子来理解输入类型和输出类型之间的关系。
我们将使用函数 "nunique" ,它将给我们提供唯一国籍的计数。让我们在两个代码例子中应用这个函数。我们两次都将引用系列 "nationality"。唯一的区别是我们将函数 "nunique" 传递给我们的agg() 函数的方式。
nationality_unique_series = df_fifa_soccer_players_subset['nationality'].agg({'nationality':'nunique'})
print(nationality_unique_series)
# nationality 160
# Name: nationality, dtype: int64
print(type(nationality_unique_series))
# pandas.core.series.Series
当我们使用字典传入 "nunique" 函数时,输出类型是一个系列。
nationality_unique_int = df_fifa_soccer_players_subset['nationality'].agg('nunique')
print(nationality_unique_int)
# 160
print(type(nationality_unique_int))
# int
当我们将 "nunique" 函数直接传入agg() 时,输出类型是一个整数。
DataFrame 上的 Agg 方法
以Python列表的形式传递聚合函数
一列代表一个系列。我们现在将选择两列作为我们的输入,因此与一个数据框架一起工作。
让我们选择列 'height_cm' 和 'weight_kgs' 。
我们将执行函数min(),mean() 和max() 。为了选择一个二维数据(数据框架),我们需要使用双括号。我们将把结果四舍五入到两个小数点。
让我们把结果存储在一个变量中。
height_weight = df_fifa_soccer_players_subset[['height_cm', 'weight_kgs']].agg(['min', 'mean', 'max']).round(2)
print(height_weight)

我们得到一个包含行和列的数据框。让我们通过检查'height_weight'变量的类型来确认这一观察。
print(type(height_weight))
# pandas.core.frame.DataFrame
我们现在将使用我们新创建的名为'height_weight'的数据框架来使用'axis'参数。整个数据框架包含数字值。
我们定义函数并传入axis 参数。我使用count() 和sum() 函数来显示axis 参数的效果。结果数值没有什么意义。这也是我为什么不重命名标题以恢复丢失的列名的原因。
height_weight.agg(['count', 'sum'], axis=1)

我们沿着行进行汇总。返回每行的项目数和项目值的总和。
将聚合函数作为python字典传递
现在让我们将不同的函数应用于我们数据框架中的各个集合。我们选择集合 'overall_rating' 和 'value_euro'。我们将把函数std(),sem() 和mean() 应用到 'overall_rating' 系列,把函数min() 和max() 应用到 'value_euro' 系列。
rating_value_euro_dict = df_fifa_soccer_players_subset[['overall_rating', 'value_euro']].agg({'overall_rating':['std', 'sem', 'mean'], 'value_euro':['min', 'max']})
print(rating_value_euro_dict)

该数据框架包含计算值和空(NaN)值。让我们快速确认我们输出的类型。
print(type(rating_value_euro_dict))
# pandas.core.frame.DataFrame
以Python元组的形式传递聚合函数
现在我们将重复前面的例子。
我们将使用元组而不是字典来传入聚合函数。元组有局限性。我们只能在一个元组中传递一个聚合函数。我们还必须为每个元组命名。
rating_value_euro_tuple = df_fifa_soccer_players_subset[['overall_rating', 'value_euro']].agg(overall_r_std=('overall_rating', 'std'),overall_r_sem=('overall_rating', 'sem'),overall_r_mean=('overall_rating', 'mean'),value_e_min=('value_euro', 'min'),value_e_max=('value_euro', 'max'))
print(rating_value_euro_tuple)

在分组的DataFrame上的Agg方法
通过单列进行分组
''[groupby](https://blog.finxter.com/pd-dataframe-groupby-a-simple-illustrated-guide/)'方法创建一个分组数据框架。我们现在将选择列'age'和'wage_euro',并使用列'age'来分组我们的数据框架。在我们的分组数据框架上,我们将使用函数count(),min(),max() 和mean() 应用agg() 函数。
age_group_wage_euro = df_fifa_soccer_players_subset[['age', 'wage_euro']].groupby('age').aggage(['count', 'min', 'max', 'mean'])
print(age_group_wage_euro)

每一行代表一个年龄组。计数值显示有多少球员属于该年龄组。最小值、最大值和平均值对年龄组成员的数据进行汇总。
多重指数
分组数据框架的另一个方面是产生的分层索引。我们也称它为 多指标.
我们可以看到,我们分组的数据框架的各个列处于不同的层次。查看层次结构的另一种方法是请求特定数据集的列。
print(age_group_wage_euro.columns)

使用多索引的工作是另一篇博文的主题。为了使用我们已经讨论过的工具,让我们平铺多索引并重置索引。我们需要以下函数。
droplevel()reset_index()
age_group_wage_euro_flat = age_group_wage_euro.droplevel(axis=1, level=0).reset_index()
print(age_group_wage_euro_flat.head())

结果数据框架的列现在是平的。在扁平化过程中我们丢失了一些信息。让我们重新命名这些列并返回一些丢失的上下文。
age_group_wage_euro_flat.columns = ['age', 'athlete_count', 'min_wage_euro', 'max_wage_euro', 'mean_wage_euro']
print(age_group_wage_euro_flat.head())

按多列分组
按多列分组可以创建更加细化的子段。
让我们使用 "age"作为第一个分组参数,"nationality"作为第二个分组参数。我们将使用列'overall_rating'和'height_cm'来汇总所产生的分组数据。现在我们已经熟悉了这个例子中使用的聚合函数。
df_fifa_soccer_players_subset.groupby(['age', 'nationality']).agg({'overall_rating':['count', 'min', 'max', 'mean'], 'height_cm':['min', 'max', 'mean']})

每个年龄组都包含国籍组。聚合的运动员数据是在国籍组内。
自定义聚合函数
我们可以编写和执行自定义聚合函数来回答非常具体的问题。
让我们来看看内联lambda函数。
 Lambda函数是所谓的匿名函数。它们被这样称呼是因为它们没有名字。在一个lambda函数中,我们可以执行多个表达式。我们将通过几个例子来看看lambda函数的作用。
Lambda函数是所谓的匿名函数。它们被这样称呼是因为它们没有名字。在一个lambda函数中,我们可以执行多个表达式。我们将通过几个例子来看看lambda函数的作用。
在pandas中,lambda函数存在于 "DataFrame.apply()" 和 "Series.appy()" 方法中。我们将使用DataFrame.appy() 方法来执行两个轴上的函数。让我们先来看看基础知识。
函数语法
DataFrame.apply() 函数将沿着DataFrame的定义轴执行一个函数。我们将在我们的例子中执行的函数将与通过apply() 方法传递给我们的自定义函数的系列对象一起工作。根据我们将选择的轴,系列将由我们的数据框架的一行或一列组成。

"func" 参数。
- 包含一个应用于数据框架中某一列或某一行的函数。
axis"参数。
- 默认设置为0 ,将传递一系列的列数据。
- 如果设置为1将传递一系列的行数据
- 可以持值。
- 0或 "
index - 1或 '
columns'
- 0或 "
"raw" 参数。
- 是一个布尔值
- 缺省设置为
False - can hold values:
False--一个Series对象被传递给函数True-> 一个ndarray对象被传递给了函数
"result_type" 参数。
- 只能在轴为1或 '
columns' 时适用。 - can hold values:
- '
expand' ‘reduce’- '
broadcast'
- '
"args()" 参数。
- 作为元组的函数的附加参数
**kwargs "参数:函数的附加参数为元组。
- 参数:函数的附加参数,作为键值对。
过滤器
让我们看一下过滤器。它们在我们探索数据时将非常方便。
在这个代码示例中,我们创建了一个名为filt_rating 的过滤器。我们选择我们的数据框架和列overall_rating 。如果overall_rating 列中的值是90或以上,条件>= 90 返回True 。
否则,过滤器会返回False 。
filt_rating = df_fifa_soccer_players_subset['overall_rating'] >= 90
print(filt_rating)

结果是一个Series对象,包含索引,以及相关的值True 或False 。
让我们将过滤器应用于我们的数据框架。我们调用 [.loc](https://blog.finxter.com/slicing-data-from-a-pandas-dataframe-using-loc-and-iloc/)方法,并将过滤器的名称作为一个列表项传入。这个过滤器的工作原理就像一个面具。它涵盖了所有数值为False 的记录。其余的行符合我们的过滤条件:overall_rating >= 90 。
df_fifa_soccer_players_subset.loc[filt_rating]

Lambda函数
让我们用一个lambda函数来重新创建同样的过滤器。我们将称我们的过滤器为filt_rating_lambda 。
让我们看一下代码。我们指定我们的过滤器的名称,并调用我们的数据框架。请注意双方括号。我们用它们来传递一个数据框架而不是一个系列对象给.appy() 方法。
在.apply() ,我们使用关键字'lambda'来表明我们即将定义我们的匿名函数。'x' 代表传递到lambda函数中的系列。
该系列包含来自overall_rating 列的数据。在半列之后,我们再次使用占位符x 。现在我们应用一个名为ge() 的方法。它代表了我们在第一个过滤器例子中使用的相同条件 ">=" (大于或等于)。
我们定义整数值为90,并关闭应用函数的括号。结果是一个数据框架,它包含一个索引和只有一列的布尔值。为了将这个数据框架转换为一个系列,我们使用squeeze() 方法。
filt_rating_lambda = df_fifa_soccer_players_subset[['overall_rating']].apply(lambda x:x.ge(90)).squeeze()
print(filt_rating_lambda)
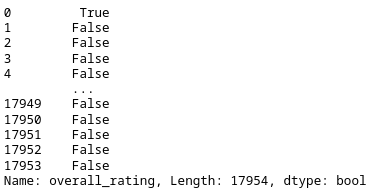
让我们使用我们的过滤器。很好,我们得到的结果与我们第一个过滤器的例子相同。
df_fifa_soccer_players_subset.loc[filt_rating_lambda]

我们现在想知道我们的过滤器返回了多少名球员。让我们先不使用lambda函数,然后使用lambda函数来看看同样的结果。我们正在计算行数或记录。
df_fifa_soccer_players_subset.loc[filt_rating_lambda].count()

df_fifa_soccer_players_subset.apply(lambda x:x.loc[filt_rating_lambda]).count()

很好。现在让我们把我们放在一个真正需要使用apply() 方法和lambda函数的地方。我们想在一个分组的数据框中使用我们的过滤器。
让我们按国籍分组,看看这些了不起的球员的分布情况。输出将包含所有列。这使得代码更容易阅读。
df_fifa_soccer_players_subset.groupby('nationality').loc[filt_rating_lambda]

Pandas在这个错误信息中告诉我们,我们不能在分组的数据框对象上使用'loc'方法。
现在让我们看看如何通过使用lambda函数来解决这个问题。我们不在分组数据框架上使用'loc'函数,而是使用apply() 函数。在apply() 函数中,我们定义我们的 lambda 函数。现在我们在变量 "x"上使用 "loc"方法,并通过我们的过滤器。
df_fifa_soccer_players_subset.groupby('nationality').apply(lambda x:x.loc[filt_rating_lambda])

apply()函数的轴参数
现在让我们使用axis 参数来计算这些球员的体重指数(BMI)。到目前为止,我们已经在我们的数据列上使用了lambda函数。
'x'变量是单个列的代表。我们将轴参数设置为'1'。在我们的lambda函数中的'x'变量现在将代表我们数据的各个行。
在我们计算BMI之前,让我们创建一个新的数据框架并定义一些列。我们将称我们的新数据框架为'df_bmi'。
df_bmi = df_fifa_soccer_players_subset.groupby('nationality')[['age', 'height_cm', 'weight_kgs']].apply(lambda x:x.loc[filt_rating_lambda])
print(df_bmi)

现在让我们重设索引。
df_bmi = df_bmi.reset_index()
print(df_bmi)

我们计算BMI的方法如下。我们用体重(公斤)除以身高(米)的平方。
让我们仔细看一下lambda函数。我们将'axis'定义为'1'。'x' 变量现在代表一行。我们需要在每一行使用特定的值。为了定义这些值,我们使用变量 'x' 并指定一个列名。在我们代码示例的开头,我们定义了一个新的列,命名为'bmi'。在最后,我们将结果取整。
df_bmi['bmi'] = df_bmi.apply(lambda x:x['weight_kgs']/((x['height_cm']/100)**2), axis=1).round()
print(df_bmi)
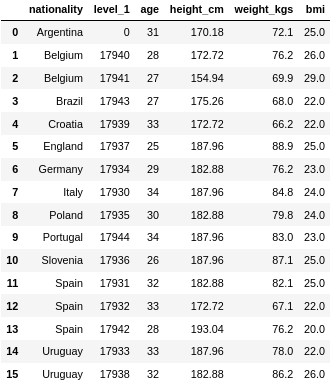
很好!我们的自定义函数成功了。我们的自定义函数起作用了。新的BMI列包含计算值。
总结
恭喜你完成了本教程。我祝愿你在今后的数据项目中能有许多伟大而细微的见解。我包括Jupyter-Notebook文件,所以你可以实验和调整代码。
书呆子的幽默

