

在本教程中,我将解释如何使用Pandas drop方法从数据框架中删除行和列。
我将解释drop方法的作用,解释其语法,并向你展示清晰的例子。
如果你需要特定的东西,你可以点击以下任何一个链接。
目录
Drop技术使用起来相当简单,但有几个重要的细节你应该知道。 所以,让我们先快速解释一下它的作用和工作原理。
Pandas drop的快速介绍
Pandas drop方法从Python数据框和系列对象中删除行和列。
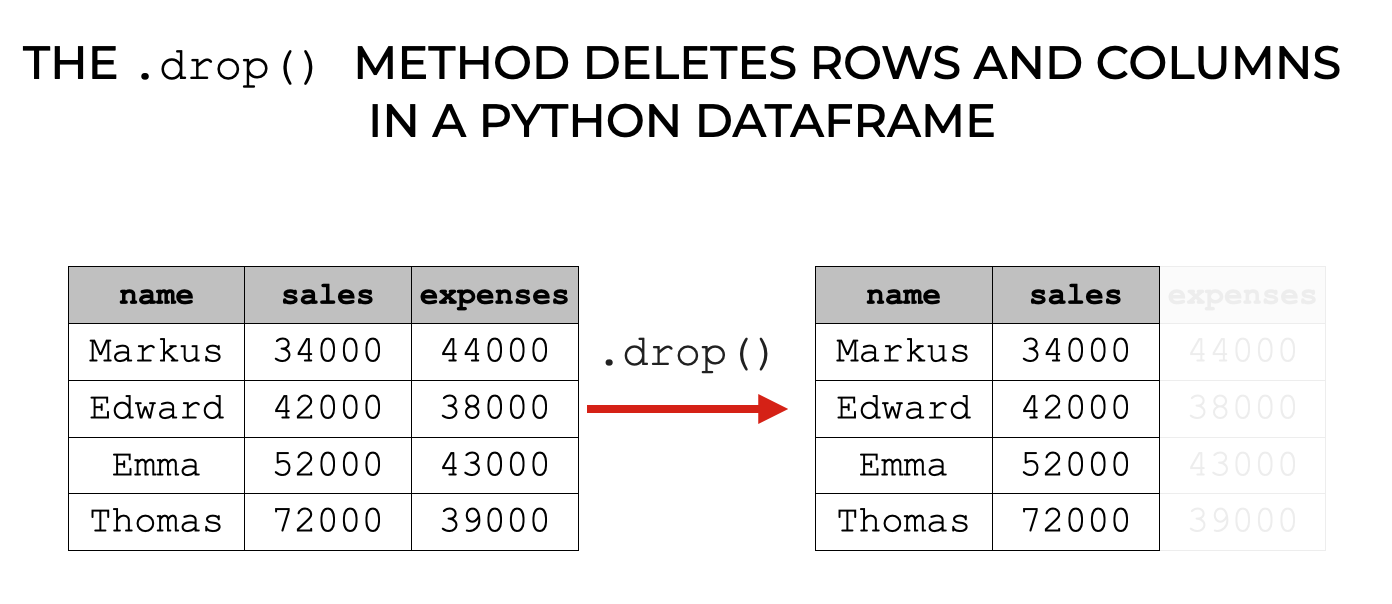
实际上,你可以用这个技术来。
- 删除行
- 删除列
虽然,我最经常使用这种技术来删除列(即变量)。
当你在做 "数据整理"或数据清理时,删除行和列是非常常见的。 所以要掌握Python中的数据整理,你真的需要知道如何使用这种技术。
说了这么多,究竟如何使用它取决于语法。 既然如此,我们来看看drop() 方法的语法。
Pandas drop的语法
在这一节中,我将向你展示以下的语法。
我们将分别看这些,之后我将解释一些可选参数。
一个简短的说明
在我们看语法之前,有一个快速说明。
所有这些语法解释都假设你已经导入了Pandas,并且你有一个可用的Pandas数据框架(或一个系列)。
你可以通过以下代码导入Pandas。
import pandas as pd
语法:删除一个列
首先,让我们看看删除一列的语法。
要删除一列,你要输入你的数据框架的名称,然后.drop() 来调用这个方法。
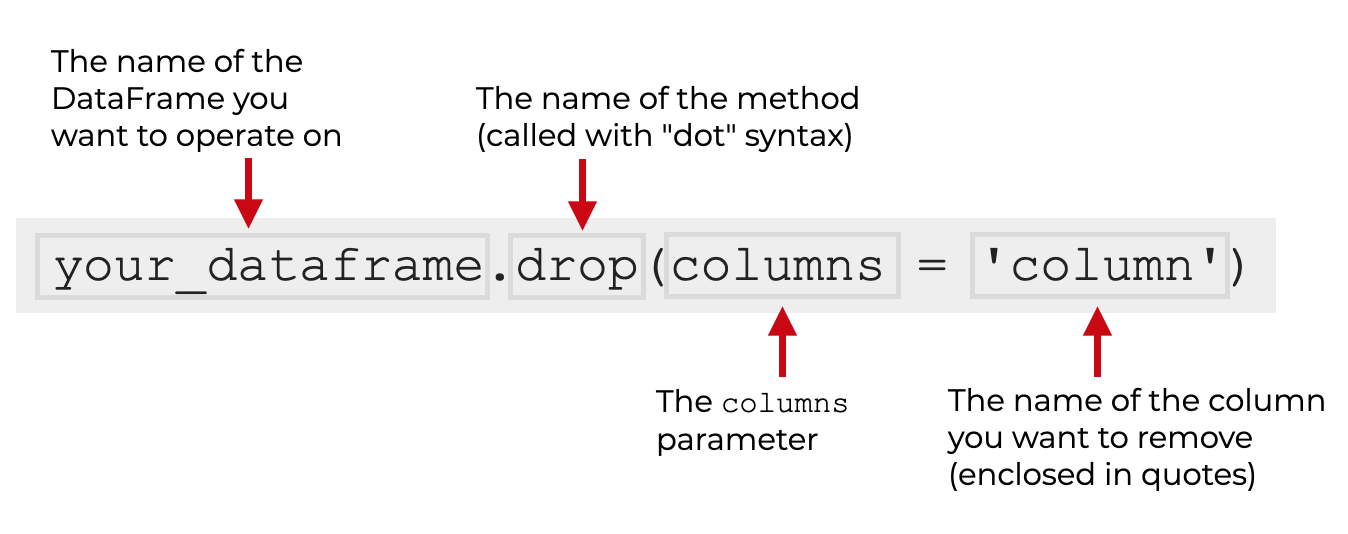
在括号内,你需要使用columns 参数。
该参数的参数将是你要删除的列的名称。 列的名称应该被括在引号内。
我将在例1中向你展示这个例子。
语法:删除多列
删除多列的语法与删除单列的语法类似。
你输入你的数据框架的名称和.drop() 来调用这个方法。 你也仍然使用columns 参数。

但是在这里,为了删除多列,你提供了一个列名的列表。
我将在示例2中向你展示这个例子。
语法:删除行
最后,让我们看看删除一行或几行的语法。
删除行的语法与前面的语法变化非常相似。
你通过输入数据框架的名称来调用该方法,然后.drop() 来调用该方法。
但是在这里,为了删除行,你使用labels 参数。
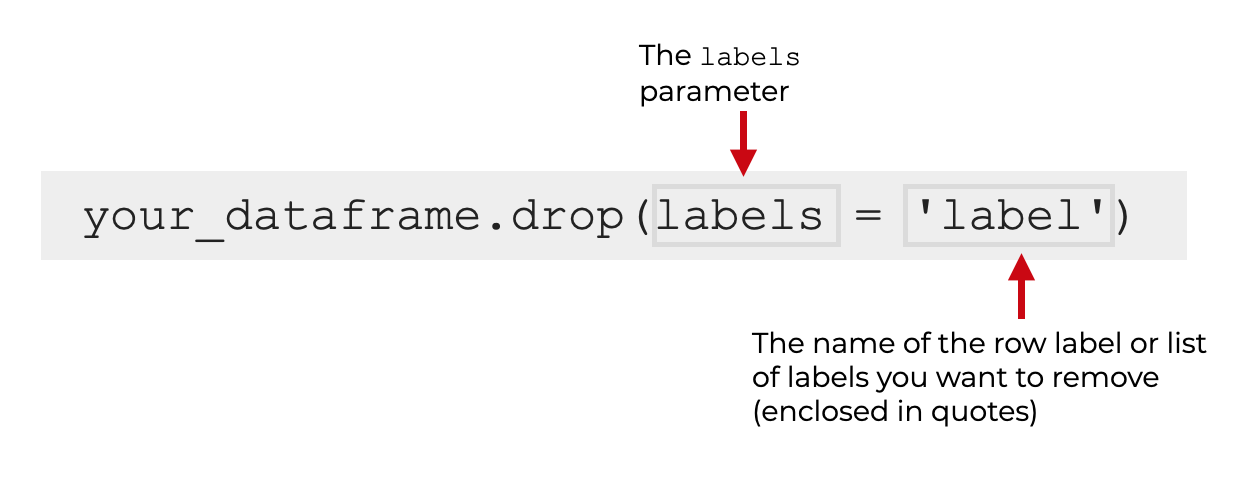
labels 参数的参数是数据框架索引中的行的 "标签"。 你可以使用一个单一的行标签,或者在一个Python列表中使用多个标签。
这样做相当简单,但是要正确地做到这一点,你真的需要了解Python数据框架的索引。 如果你需要复习一下,你可以阅读我们关于Pandas索引的教程。
我将在例3中向你展示一个如何删除行的例子。
Pandas drop的参数
现在我们已经看了Pandas drop的基本语法,让我们来看看一些参数。
我认为你应该知道的重要参数是。
columnslabelsinplace
还有一些其他的参数,但我认为其中有几个参数对于大多数初学者来说根本就是混乱的,而且还有一些不必要的参数。 所以,上面三个是我推荐使用的。
让我们来逐一讨论。
columns
columns 参数使你能够指定你要删除的列。
这个参数的参数可以是一个单一的列名或一个列名的列表。 列名本身必须包含在引号内。
我将在例子1和例子2中向你展示如何使用columns 参数。
labels
labels 参数使你能够指定你要删除的行。
这个参数的参数可以是一个单一的行标签或一个行标签的列表。
标签的格式取决于你是如何构建索引的。 如果标签是整数,你提供的标签将是整数。 但是如果索引标签是字符串,那么你将为这个参数提供字符串。
我将在例子3中向你展示如何使用labels 参数。
inplace
inplace 参数使你可以直接修改你的数据框架。
记住:默认情况下,drop() 方法会产生一个新的数据框架,并使原来的数据框架不发生变化。 这是因为在默认情况下,inplace 参数被设置为inplace = False 。
如果你设置了inplace = True ,drop() 方法将直接从原始数据框架中删除行或列。 换句话说,如果你设置了inplace = True ,Pandas将覆盖你的数据而不是产生一个新的数据框架作为输出。
当你使用这个参数时要小心,因为它将覆盖你的数据。
Pandas drop的输出
默认情况下,drop() 技术会输出一个新的数据框,而让你的原始数据框不发生变化。
这是因为在默认情况下,inplace 参数被设置为inplace = False 。
如果你设置了inplace = True ,Pandas将直接修改你所操作的数据,而不是产生一个新的对象。 当你使用inplace = True ,要小心,因为它将覆盖你的数据。
例子:如何删除潘达斯数据框架的行和列
现在我们已经看过了语法,让我们来看看如何使用drop() 方法来删除Python数据框架的行和列。
例子
首先运行此代码
在你运行任何例子之前,你需要先运行一些初步代码。
具体来说,你需要
- 导入Pandas
- 创建一个数据框架
导入Pandas
首先,让我们导入Pandas。
你可以用下面的代码来做。
import pandas as pd
很明显,我们需要Pandas来使用Pandas drop技术。 我们还需要Pandas来创建我们的数据。 接下来让我们来做这个。
创建数据框架
在这里,我们将创建一个简单的数据框架,名为sales_data 。
为此,我们将调用pd.DataFrame() 函数,但我们也将用set_index() 方法设置数据框架的索引。
# CREATE DATAFRAME
sales_data = pd.DataFrame({
"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
# SET INDEX
sales_data.set_index('name', inplace = True)
这个数据框架包含模拟的销售数据。 我们将能够在我们的例子中使用它。
让我们快速地把它打印出来,这样我们就可以看到它的内容。
print(sales_data)
输出
region sales expenses
name
William East 50000 42000
Emma North 52000 43000
Sofia East 90000 50000
Markus South 34000 44000
Edward West 42000 38000
Thomas West 72000 39000
Ethan South 49000 42000
Olivia West 55000 60000
Arun West 67000 39000
Anika East 65000 44000
Paulo South 67000 45000
正如你所看到的,这个数据框架有3列。region,sales, 和expenses 。
该数据框架还有一个索引,包含数据中销售人员的名字。 我们将能够使用该索引来引用这些行并删除特定的行。
现在我们有了我们的数据框架,让我们运行一些例子。
例子1:从数据框架中删除一个单列
首先,让我们从非常简单的开始。
在这里,我们要从我们的数据框架中删除一个单列。
要做到这一点,我们将调用drop方法,并且我们将使用columns 参数。
让我们看一下。
sales_data.drop(columns = 'expenses')
输出
region sales
name
William East 50000
Emma North 52000
Sofia East 90000
Markus South 34000
Edward West 42000
Thomas West 72000
Ethan South 49000
Olivia West 55000
Arun West 67000
Anika East 65000
Paulo South 67000
解释
这相当简单,但让我解释一下。
在这里,我们删除了expenses 列。
为了做到这一点,我们输入了数据框架的名称,然后.drop() 来调用这个方法。
在括号内,我们用代码columns = 'expenses' 来指定我们要删除expenses 列。 注意,列的名称在引号内(即,它以字符串的形式呈现)。
在输出中,我们看到整个expenses 列已被删除。
还要注意:输出是一个新的数据框架,而原始数据保持不变。 这是因为在默认情况下,inplace 参数被设置为inplace = False 。当inplace = False ,drop() 将输出一个新的数据框架,但保留原始数据框架不变。
我将在例子4中告诉你如何直接修改原始数据框架。
实例2:从数据框架中删除多列数据
接下来,让我们从一个Pandas数据框架中删除多列。
要做到这一点,我们仍将使用columns 参数。
但是我们将提供一个列名作为参数,而不是一个单一的列名,我们将提供一个列名列表。
具体来说,在这里,我们将删除region 变量和expenses 变量。
让我们看一下。
sales_data.drop(columns = ['region','expenses'])
输出
sales
name
William 50000
Emma 52000
Sofia 90000
Markus 34000
Edward 42000
Thomas 72000
Ethan 49000
Olivia 55000
Arun 67000
Anika 65000
Paulo 67000
解释
在输出中我们看到,region 变量和expenses 变量都被删除了。
为了做到这一点,我们调用了drop() 方法,但是我们使用了columns 参数来指定要删除的多个变量。
具体来说,在括号内,我们用代码columns = ['region','expenses'] 来表示我们要删除region 变量和expenses 变量。 注意,这些变量的名字都在引号内(即,它们以字符串的形式呈现)。 此外,它们是作为一个变量名称的列表传递给columns 参数的。
请记住,在这里,我们只删除了两个变量。 但是如果你有一个更大的数据框架,你想删除更多的变量,你可以简单地创建一个你想删除的所有名字的列表。
实例3:从数据框架中删除特定的行
现在,让我们从我们的数据框架中删除一些行。
删除行与删除列非常相似。 但是我们不使用columns ,而是使用labels 参数。
通过使用labels 参数,我们可以通过索引标签指定要删除的特定行。
让我们看一下。
sales_data.drop(labels = ['William','Paulo'])
输出
region sales expenses
name
Emma North 52000 43000
Sofia East 90000 50000
Markus South 34000 44000
Edward West 42000 38000
Thomas West 72000 39000
Ethan South 49000 42000
Olivia West 55000 60000
Arun West 67000 39000
Anika East 65000 44000
解释
在这里,我们删除了威廉和保罗的记录。 我们用代码drop(labels = ['William','Paulo']) 来完成这个任务。
labels 参数使我们能够按索引标签删除记录,而数值列表(即:['William','Paulo'] )则准确地指出要删除哪些记录。
注意,在这个例子中,我们删除了多条记录,所以我们在Python列表中展示了标签,类似于在例子2中删除多列的做法。
例子 4:删除列并 "原地 "修改数据
最后,让我们通过 "就地 "删除一列来直接修改我们的数据。
记住:当我们使用drop() 方法时,该技术默认产生一个新的数据框架作为输出,并保留原始数据框架不变。
我们可以通过设置inplace = True 来改变这种行为。
让我们来看看,然后我会解释。
创建数据框架副本
在我们运行这个例子之前,我们首先要创建一个数据的副本。
这是因为我们将直接修改我们的数据。 作为一种保障,我们现在就用一份副本来工作。
sales_data_copy = sales_data.copy()
如果你检查这个数据,你会发现它和sales_data 。
删除 "到位 "列
好的。 现在,我们将直接从sales_data_copy 中删除一列。
sales_data_copy.drop(columns = 'expenses', inplace = True)
然后让我们把数据打印出来。
print(sales_data_copy)
输出
region sales
name
William East 50000
Emma North 52000
Sofia East 90000
Markus South 34000
Edward West 42000
Thomas West 72000
Ethan South 49000
Olivia West 55000
Arun West 67000
Anika East 65000
Paulo South 67000
解释
当你运行代码后,再看sales_data_copy ,你可以看到expenses 这个变量已经从数据框中永久删除。
记住:当我们使用drop() 技术和inplace = True ,Pandas将直接对数据框架进行操作。
这与inplace = False 相反。如果你设置了inplace = False (这是默认行为),Pandas将产生一个新的数据框架,并保持原有的数据框架不变。
所以当你使用inplace = True ,Pandas将直接改变你的数据。 这可能是很危险的。 在你使用之前,你应该测试你的代码,以确保它能正常工作!
关于Pandas drop的常见问题
现在我们已经看了一些例子,让我们看看关于drop() 技术的一些常见问题。
常见问题。
问题1:我使用了下降法,但我的数据框架没有变化。 为什么?
如果你使用了drop方法,你可能会注意到,在你调用该方法后,你的原始数据框架仍然没有变化。
例如,在例子1中,我们使用了以下代码。
sales_data.drop(columns = 'expenses')
如果你在运行该代码后打印出sales_data ,你会发现sales_data 是没有变化的。 expenses 列仍然在那里。
这是因为drop() 方法产生了一个新的数据框,并使两个原始数据框保持不变。
默认情况下,该方法的输出被发送到控制台。 我们可以在控制台中看到输出,但是为了保存它,我们需要用一个名字来存储它。
例如,你可以像这样存储输出。
sales_data_updated = sales_data.drop(columns = 'expenses')
你可以给输出命名任何你想要的东西。 你甚至可以用原来的名字命名sales_data 。
另外,你可以设置inplace = True ,这也会覆盖你的原始数据集。我在例4中展示了一个这样的例子。
但是要小心,如果你使用这两种技术,它们都会覆盖你的原始数据集。 请确保你在覆盖输入数据框之前检查你的代码,使其正常工作。
问题2:轴参数有什么作用?
axis 参数是控制你是否删除行或列的另一种方式。
我个人认为,在drop() 方法中使用axis 参数是非常糟糕的设计。 我就不多说了,但是Pandas的开发者实现这个参数的方式让人非常困惑,难以操作。
好消息是,还有一个办法。 你可以完全跳过使用axis 参数。
相反,当你想删除列时,你可以使用columns 参数,而当你想删除行时,你可以使用labels 参数。
我在语法部分展示了使用这些其他参数的语法,并在例1、例2和例3中展示了删除列和行的例子。
这个教程应该已经给你一个关于Pandas drop技术的很好的介绍,但是如果你真的想掌握Python中的数据处理和数据科学,还有很多东西需要学习。
