

本教程将告诉你如何制作Plotly散点图。 具体来说,它将告诉你如何用Plotly express创建一个散点图。
所以本教程将解释px.scatter函数的语法,包括一些重要的参数。
它还将向你展示如何在Plotly express中创建散点图的清晰、逐步的例子。
目录
如果你需要具体的东西,你可以点击上面的任何一个链接。
然而,如果你是Plotly的新手或者是Python数据科学的新手,如果你读完整个教程,一切可能会更有意义。
好的,让我们开始吧。
对Plotly散点图的快速介绍
正如你可能知道的,散点图是一种数据可视化,它绘制了两个数字变量。 一个数字变量被映射到X轴上,另一个被映射到Y轴上。
然后,数据中的单个观测值被绘制成点。
px.scatter 创建散点图
在Python中实际上有几种创建散点图的方法(即Seaborn散点图和Matplotlib散点图),用Plotly创建散点图的方法也不止一种。
但是用Plotly创建散点图的最简单的方法是用Plotly Express中的px.scatter 函数。
在这里,我将引导你了解Plotly Express散点图的基本语法,并解释一些额外的参数,使你能够修改你的图。
px.scatter的语法
用Plotly Express创建一个散点图的语法相当简单。
在简单的情况下,你只需调用函数px.scatter,提供你想要绘制的数据框架的名称,然后将变量映射到x轴和y轴上。
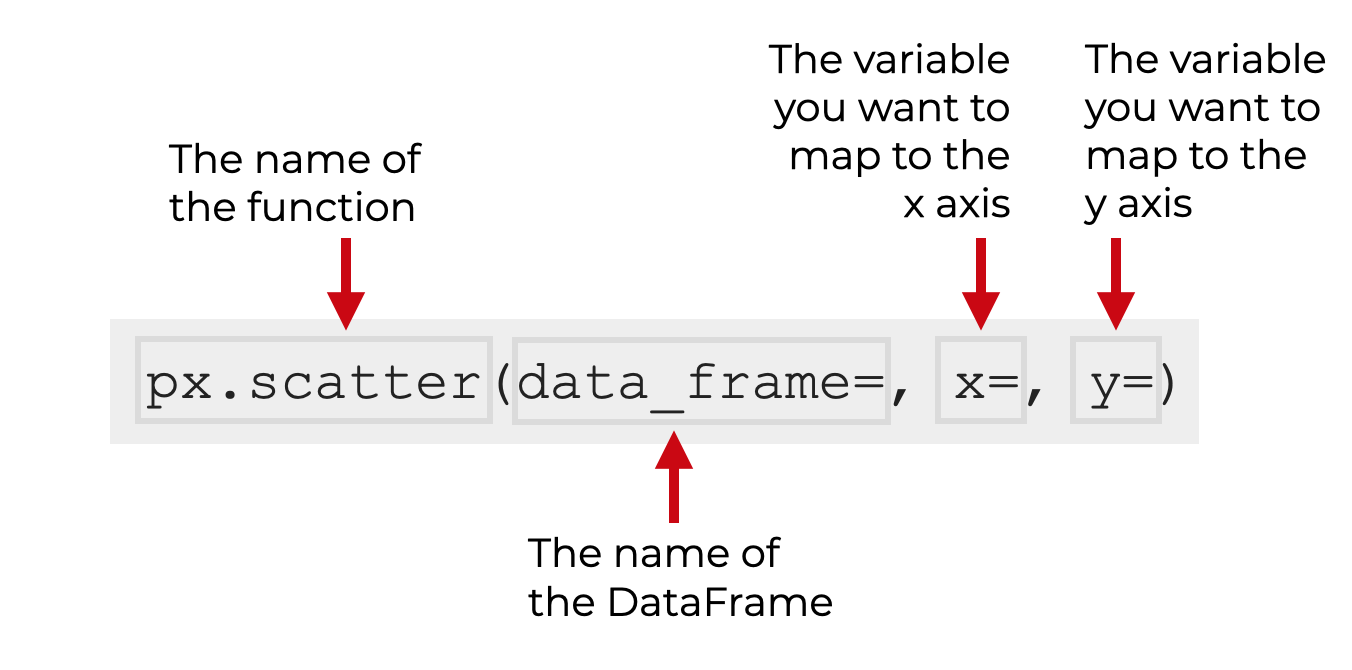
注意,这假定你已经将Plotly Express导入为px 。这是常见的惯例,我们将在本教程中坚持使用它。
除了基本的散点图,还有一些散点图的变化,你也可以通过使用一些参数来创建。 让我们来看看这些参数,然后我们再看一些例子。
px.scatter的参数
px.scatter() 函数有大约4打参数,你可以用它们来修改你的Plotly散点图。
事实上,你可能只会经常使用其中的几个,所以试图解释所有的参数是很不合适的。
因此,本着80/20规则的精神,我将解释我认为最重要的参数,你应该首先学习。
data_framexycolorcolor_discrete_sequenceopacity
让我们快速地讨论一下这些参数中的每一个
data_frame (必填)
data_frame 参数允许你指定包含你想要绘制的数据的Pandas DataFrame。
你的DataFrame应该是所谓的"整洁 "格式。 整齐的数据是结构化的数据,每个变量都在自己的列中,每个观察值都有自己的行。(你的数据可能有其他格式,所以你需要注意你的数据的格式)。
这个参数是可选的。 如果你不提供一个DataFrame,那么你就需要改变你使用x 和y 参数的方式。
x
x 参数允许你指定将被映射到X轴的变量。
作为该参数参数的变量应该是数字型的(尽管该函数在某些特殊情况下会允许字符串型的变量)。
如果你用data_frame 参数指定一个数据框架,那么这个参数的参数应该是你的数据框架的一个列的名称。
或者,如果你没有指定一个DataFrame,那么你可以使用Series或类似列表的对象作为x 参数的参数。
y
y 参数与x 参数非常相似。
y 参数允许你指定将被映射到Y轴的变量。
作为这个参数的参数,你提供的变量应该是数字的(尽管在一些特殊情况下允许使用字符串变量)。
如果你用data_frame 参数指定了一个数据框架,那么这个参数的参数应该是你的数据框架中的一个列的名称。
或者,如果你没有指定一个DataFrame,那么你可以使用Series或类似列表的对象作为y 参数的参数。
color_discrete_sequence
color_discrete_sequence 参数使你可以修改点的内部颜色(或应用于一组点的整个调色板)。
如果你绘制的散点图只有一种颜色,那么默认情况下,点的颜色将是一种中等的蓝色。
如果你绘制的散点图有多种颜色(即多个类别),则有一组默认颜色将作为默认调色板应用。
通过使用color_discrete_sequence 参数,你可以覆盖这些默认颜色,并为你的点或点的类别指定你想要的确切颜色。
我将在例子2中向你展示这个例子。
默认情况下,颜色是一种中等的蓝色,但你可以把它改成各种各样的颜色。 这个参数将接受所谓的 "命名颜色",但十六进制的颜色也可以。
color
color 参数使你能够根据一些变量来修改点的颜色。
这个参数将接受一个分类参数(例如,一个字符串)或一个数字变量。
例如,如果你的数据有多个类别,你可以使用color 参数在散点图中用颜色来区分这些类别。
你也可以向 color 参数传递一个数字变量。 在这种情况下,该函数将根据你提供的变量的数值,沿梯度改变点的颜色。
还要注意的是,你作为参数传递的变量可以是DataFrame中某一列的名称(如果你使用了data_frame 参数)。 或者,你可以传入一个Pandas系列或类似列表的对象。
我将在例子4中向你展示这个例子。
opacity
opacity 参数使你可以改变点的不透明度(即它们的透明程度)。
不透明度的范围从0到1,1是完全不透明的,0是完全透明的。 1是默认的。
我将在实例3中向你展示如何使用这个参数的例子。
例子:如何用Plotly制作散点图
好的。 现在我们已经看了px.scatter的语法,让我们看看如何使用这个函数来创建散点图的几个例子。
例子
先运行这个代码
在你运行任何一个例子之前,你需要运行一些代码,让一切都准备好。
具体来说,我们要导入相关的包,并创建我们将在例子中使用的DataFrame。
导入软件包
首先,让我们导入一些我们要使用的Python包。
我们将导入Numpy和Pandas来帮助我们用一些随机数字数据创建一个DataFrame。
显然,我们需要导入Plotly来创建我们的Plotly散点图。
import pandas as pd
import numpy as np
import plotly.express as px
创建数据
接下来,我们需要创建我们要绘制的DataFrame。
在这里,我们将创建一个简单的DataFrame,其中包含两个正态分布的数字变量和一个分类变量。我将数字变量称为x_var 和y_var ,我将分类变量称为categorical_var 。
np.random.seed(0)
x_var = np.random.normal(size = 6000)
y_var = np.random.normal(size = 6000)
norm_data = pd.DataFrame({'x_var':x_var
,'y_var':y_var}
)
norm_data = norm_data.assign(category_var = np.where(x_var > 1, "Category A","Category B"))
在这里,我们使用Numpy random seed来为我们的随机数生成器设置种子,我们使用Numpy random normal来创建我们的数字变量。 然后,我们使用pd.DataFrame 函数将它们组合成一个DataFrame。
我们还使用Numpy where函数和Pandas assign技术来创建我们的分类变量,category_var 。
让我们通过head()技术打印出前几行的数据来看看这些数据。
norm_data.head()
输出
x_var y_var category_var
0 1.764052 2.042536 Category A
1 0.400157 -0.919461 Category B
2 0.978738 0.114670 Category B
3 2.240893 -0.137424 Category A
4 1.867558 1.365527 Category A
在这里,我们可以看到前5行,这应该让你对数据有一个大致的了解。 同样,我们有两个数字变量和一个分类变量。
我们将能够利用这些数据绘制一些不同类型的散点图。
现在我们有了数据,让我们举几个例子。
例子1:创建一个简单的散点图
首先,我们将从一个简单的散点图开始。
为了创建这个,我们将调用px.scatter() 函数。
在括号内,我们将使用data_frame 参数来指定我们要绘制的DataFrame,norm_data 。
然后,我们将变量x_var 映射到x轴上,y_var 映射到y轴上。
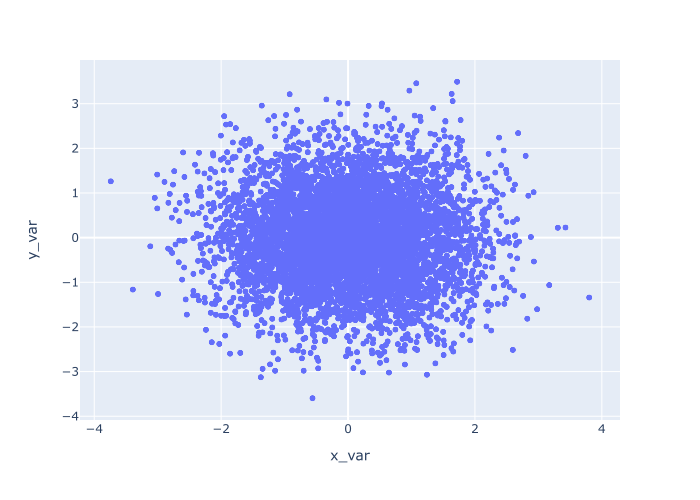
px.scatter(data_frame = norm_data
,x = 'x_var'
,y = 'y_var'
)
当我们运行这段代码时,下面是输出结果。
解释
这相当简单,但让我解释一下。
px.scatter 函数指定我们要创建一个散点图。
data_frame 参数指定了我们要绘制的数据集。
我们使用x 和y 参数来指定我们想在x轴和y轴上绘制的变量。
当我们运行它时,该函数为每一行的数据绘制一个点。 每个点的位置由x_var 和y_var 指定。
实例2:改变所有点的内部颜色
现在,让我们来改变这些点的颜色。
要做到这一点,我们将使用color_discrete_sequence 参数。
在这个例子中,我们将把点的颜色设置为'red' 。尽管如此,你可以使用 Python 中任何有效的 "命名颜色"。 使用十六进制的颜色也是可以接受的。
好的。让我们看一看。
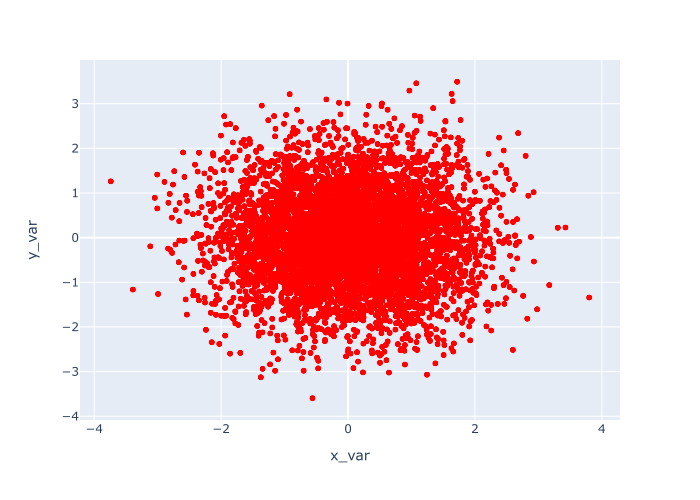
px.scatter(data_frame = norm_data
,x = 'x_var'
,y = 'y_var'
,color_discrete_sequence = ['red']
)
输出
解释
同样,这也是相当简单的。
这个例子几乎与例子1完全一样。
主要的区别是,我们通过使用代码color_discrete_sequence = ['red'] ,将点的颜色改为'red'。
显然,你可以使用除红色以外的其他颜色,所以可以尝试一些,看看你喜欢什么。
实例3:使点更加透明,以减轻过度绘图的影响
现在,我们来修改点的透明度。
你可能注意到在我们之前的两个例子中,有很多的点。 事实上,有这么多的点,它们相互重叠。 我们把这称为 "过度绘图",这是绘制散点图时的一个常见问题。
有几种方法来处理过度绘图的问题,但最好的方法之一是使点更加透明。
在Plotly中,这很容易通过opacity 参数来实现。
默认情况下,不透明度参数被设置为1,这是完全不透明的。
因此,为了使点更加透明,我们将降低不透明度。 具体来说,我们将设置opacity = .2 。
记住,opacity 的比例是在0和1之间,1是完全不透明,0是完全透明。
通过设置opacity = .2 ,我们将使这些点的不透明度只达到完全的20%。 在这个水平上,这些点几乎是透明的!
让我们看一看。
px.scatter(data_frame = norm_data
,x = 'x_var'
,y = 'y_var'
,opacity = .2
)
输出
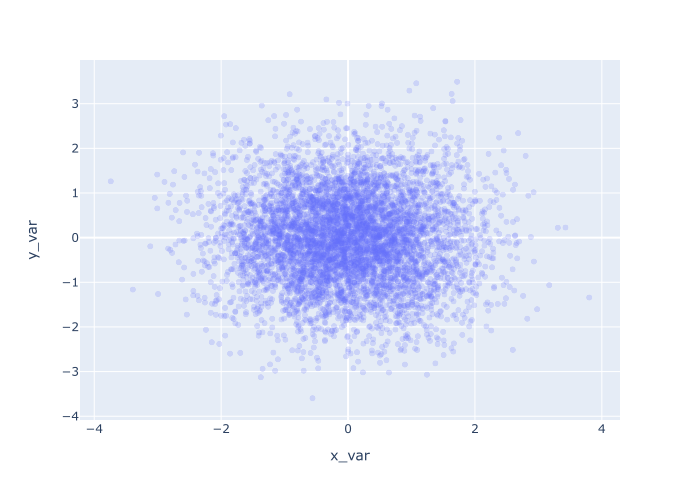
解释
在这里,你可以看到,这些点明显地更加透明了。
正因为如此,我们更容易看到数据是如何分布的。 数据在中心位置比较密集,而当你向边缘移动时,数据就会变稀疏。
为了得到这种效果,我们只需设置opacity = .2 ,这就减少了不透明度(即,使点更加透明)。
同样,这是一个你需要了解的技术,以便能够处理过度绘图。
例子4:根据一个分类变量改变颜色
接下来,我们将再次修改点的颜色。
但是这一次,我们不是让所有的点都是同样的颜色,而是根据第三个分类变量来给点着色。
为了达到这个目的,我们将把我们的分类变量,category_var ,映射到color 参数上。
让我们看一下。
px.scatter(data_frame = norm_data
,x = 'x_var'
,y = 'y_var'
,color = 'category_var'
)
输出
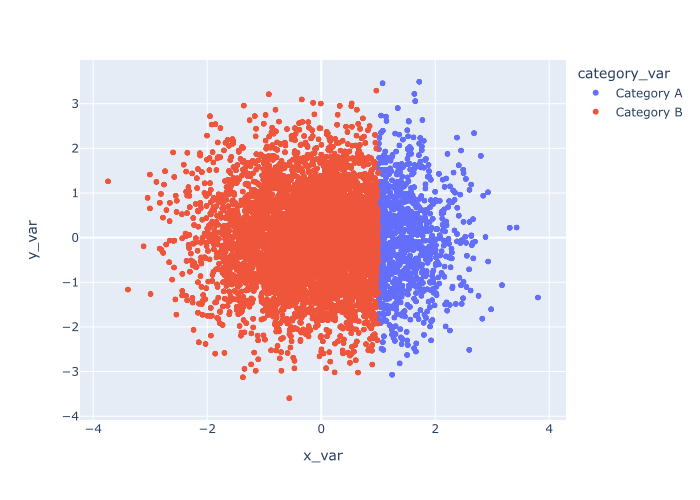
解释
在这个例子中,点的颜色是由category_var 变量的值决定的。
分配给'Category A'的点被染成了蓝色,而分配给'Category B'的点是橙色。
当你有一个分类变量想用来进一步分析你的散点图数据时,这是一个非常有用的技术。 这是创建多变量图的一种方法,可以同时分析多个变量。
例子5:一个结合多种技术的例子
最后,让我们结合前面例子中的两种技术。
我们将同时修改color 和不透明度(即alpha )。
px.scatter(data_frame = norm_data
,x = 'x_var'
,y = 'y_var'
,color = 'category_var'
,opacity = .2
)
输出
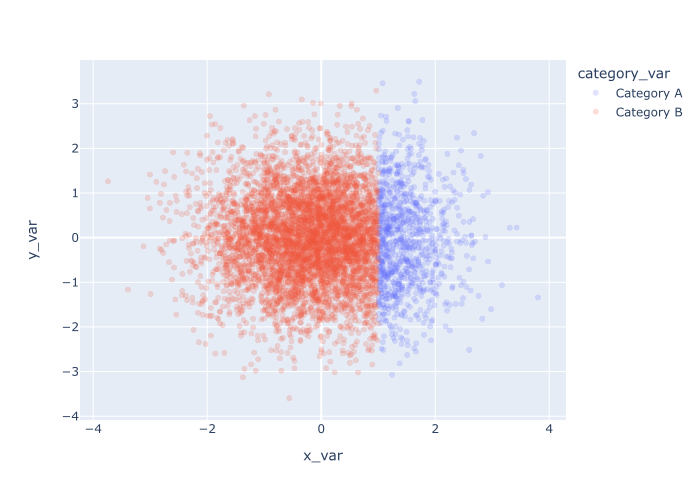
解释
在这里,我们根据category_var 中的数值对点进行了着色*,并且*我们设置了opacity = .2 ,以减少过度绘制的现象。
我在这里向你展示的例子应该足以让你开始用Plotly Express创建散点图。
