

在本教程中,我将向你展示如何用px.histogram 函数制作Plotly直方图。
我将解释px.histogram 的语法,我还将向你展示如何用Plotly express制作直方图的清晰、逐步的例子。 我将向你展示一个简单的直方图,以及一些变化。
目录
好的让我们开始吧。
直方图的快速介绍
在我们看语法之前,让我们快速回顾一下直方图。
直方图
当你探索或分析数据时,你需要看一下你的变量。
根据变量类型的不同,有不同的方法可以做到这一点。
当你检查数字变量时,最常见的检查方法之一就是直方图。 直方图向你展示了数字变量的分布情况。
通常,在直方图中,我们将一个数字变量映射到X轴上。
然后,X轴被分成若干部分,我们称之为 "仓"。可能有一个从0到20的仓,然后是一个从20到40的仓,以此类推。
然后,在最后一步,我们计算每个仓中的观察值的数量,并为每个仓绘制一个条形图。 仓的长度对应于该仓中观察值的数量。
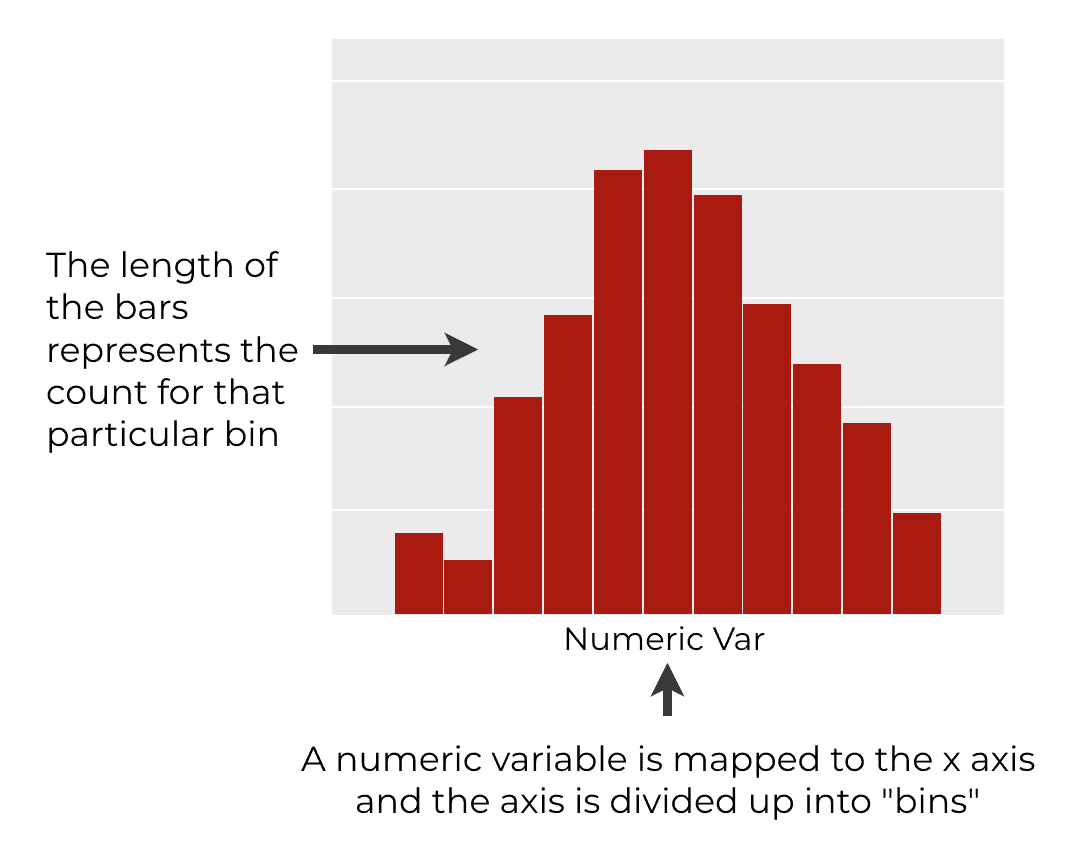
所以直方图是观察变量不同值的数据密度的一种方式。 这是一种绘制变量分布的方法。
绘制直方图
现在我们已经大致回顾了直方图,让我们来讨论如何创建Plotly直方图。
Plotly,正如你可能知道的,是一个用于Python的数据可视化工具包。
Plotly有一个强大的API来创建复杂的可视化。
但它也有一个简化的工具包,叫做Plotly Express,你可以用它来快速创建各种简单的可视化,如柱状图、线状图、散点图等等。
Plotly express有一个专门用于创建直方图的函数,即px.histogram() 函数。
这个函数是在Python中创建直方图的一种简单而又灵活的方法(同时也让你可以使用Plotly系统的强大的底层语法)。
px.histogram的语法
现在我们已经对直方图进行了一般性的回顾,让我们看看Plotly表达直方图的语法。
用px.histogram 制作直方图的语法非常简单。
通常情况下,我们调用该函数为px.histogram() 。
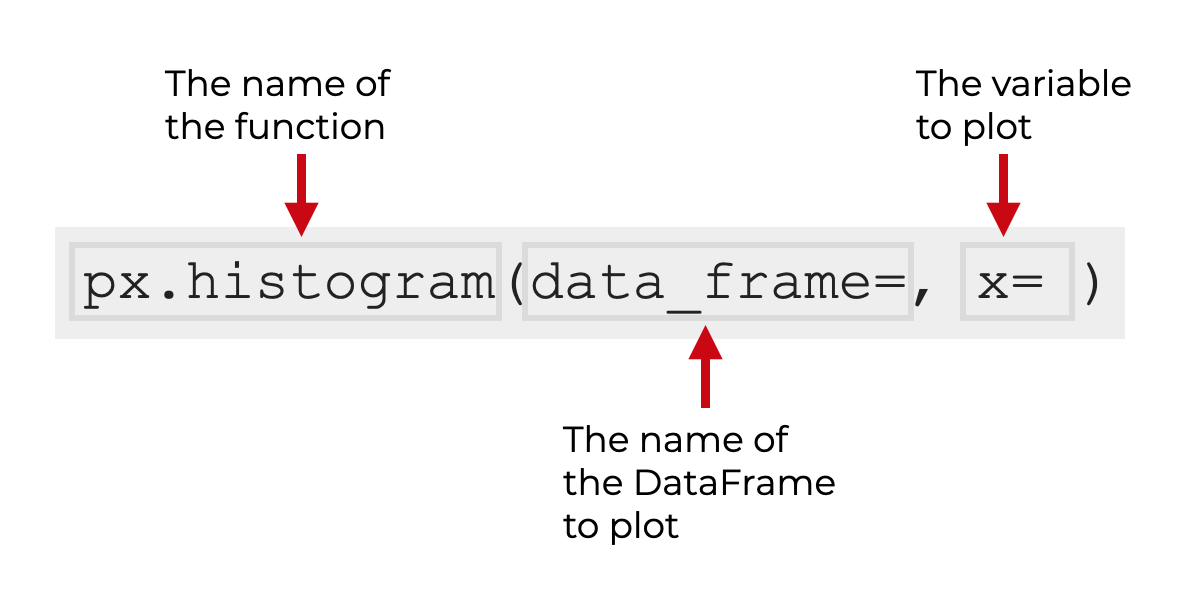
请记住,这是假设你已经用别名px ,导入了Plotly Express。你可以用代码import plotly.express as px 。
在括号内,你可以使用data_frame参数来指定一个DataFrame(可选)。 而你使用x 参数来指定你要绘制的数字变量。
还有一些额外的参数,你可以用来修改你的直方图。
考虑到这一点,让我们看一下几个。
px.histogram的参数
坏消息是,px.histogram 函数有几十个参数。
好消息是,你真的只需要学习其中的几个。 每当你学习 Python 函数时,你应该尝试应用 80/20 法则,并确定最常用的参数。
我建议你学习的参数是。
data_framexnbinscolor_discrete_sequence
让我们来看看这些参数中的每一个。
data_frame (可选)
data_frame 参数允许你指定一个你要绘制的Python数据框架。
这个参数是可选的。
如果你使用它,那么你就告诉px.histogram ,你想在你指定的DataFrame中绘制一个变量。
x
你使用x 参数来指定你想要绘制的特定数字变量。
如果你使用data_frame 参数来指定一个DataFrame,那么这个参数的参数将是该DataFrame中的一个列的名称。 如果你指定了一个DataFrame列,那么你将把该列的名称作为一个字符串传递。 例如,如果你想在DataFrame中绘制mycolumn 变量,你将使用语法x = 'mycolumn' 。
另外,你也可以选择绘制一个存在于DataFrame之外的数字变量。 这可能是Python列表或Numpy数组中的数据。 如果你这样做,那么你可以跳过名称周围的引号。 (在大多数情况下,只有当你绘制一个DataFrame列时才需要引号。)
color_discrete_sequence (可选)
color_discrete_sequence 参数改变直方图的颜色。 它改变条形图的颜色。
这个参数的参数可以是一个 "命名的颜色",比如 'red', 'orange', 或者 'blue'. (Python 有一个很长的命名颜色列表。)
你也可以使用一个十六进制的颜色。 十六进制的颜色对初学者来说有点复杂,所以为了节省空间和简化,我不打算在这里解释它们 (但它们最终还是有用的,可以学习)。
nbins
nbins 参数控制直方图中的bin数量(即条形图的数量)。
这个参数的参数应该是一个整数(即你想要的bin的数量)。例如,如果你设置nbins = 50 ,该函数将创建一个有50个条形(即bin)的柱状图。
我在此指出,有时你会为nbins 指定一个值,但该函数将创建一个具有稍少分值的直方图。 你有时需要玩玩这个,以得到一个具有大致适当数量的直方图。
我将在例子4中向你展示如何改变分层的数量。
例子:如何用Plotly Express制作直方图
现在我们已经看过了语法,让我们来看看如何用Plotly Express创建直方图的一些例子。
例子
先运行这段代码
在我们看这些例子之前,你需要运行一些初步的代码来导入一些包并创建我们的数据。
导入软件包
首先,我们要导入一些Python包。
import numpy as np
import pandas as pd
import plotly.express as px
我们将使用Numpy来创建一些我们可以绘制的正态分布数据。
我们将使用Pandas把这些数据变成一个DataFrame。
我们将使用Plotly Express来创建我们的柱状图。
创建数据集
接下来,让我们创建我们的数据集。
我们将分两步来做这件事。
- 用Numpy随机正态函数创建正态分布数据
- 将正态分布的变量组合成一个DataFrame
首先,我们将使用 Numpy随机正态函数来创建两个正态分布变量。 在这里,我将这些变量称为normal_data_a 和normal_data_b 。
np.random.seed(33)
normal_data_a = np.random.normal(size = 500, loc = 100, scale = 10)
normal_data_b = np.random.normal(size = 700, loc = 75, scale = 5)
我们要创建两个正态分布的数据集,因为我希望数据集有两个独立的峰值。
所以,现在我们有了两个正态分布的变量,我们要把它们各自变成一个数据框。 请注意,在我们这样做的时候,我们正在使用Pandas的assign函数来创建一个新的分类变量,叫做group 。
df_normal_a = pd.DataFrame(data = normal_data_a, columns=['score']).assign(group = 'Group A')
df_normal_b = pd.DataFrame(data = normal_data_b, columns=['score']).assign(group = 'Group B')
score_data = pd.concat([df_normal_a, df_normal_b])
在这里,我们还使用Pandas concat函数将这两个不同的DataFrames合并成一个名为score_data 的单一数据框架。
让我们用打印语句来看看最终的score_data 数据框架。
print(score_data)
输出
score group
0 96.811465 Group A
1 83.970194 Group A
2 84.647821 Group A
3 94.295991 Group A
4 97.832717 Group A
.. ... ...
695 84.728235 Group B
696 75.675768 Group B
697 78.171504 Group B
698 69.243985 Group B
699 75.073327 Group B
如果你看一下数据,你可以看到这个DataFrame有两个变量:score 和group 。 我们将在我们的直方图中使用这两个变量。
设置Plotly图像渲染
在我们绘制数据之前还有一件事。
如果你在Spyder或PyCharm这样的集成开发环境中使用Plotly,你需要运行一些额外的代码来让可视化的东西在IDE中显示。
如果你使用的是IDE,你可以运行以下代码。
import plotly.io as pio
pio.renderers.default = 'svg'
说了这么多,如果你使用的是Jupyter笔记本,应该不需要这些代码了。
好了。 我们所有的设置都应该完成了。 我们准备做一些直方图了。
例子1:创建一个简单的Plotly直方图
让我们从一个简单的柱状图开始。
在这里,我们只是用px.histogram 来绘制score 变量中的数据。
这里是代码。
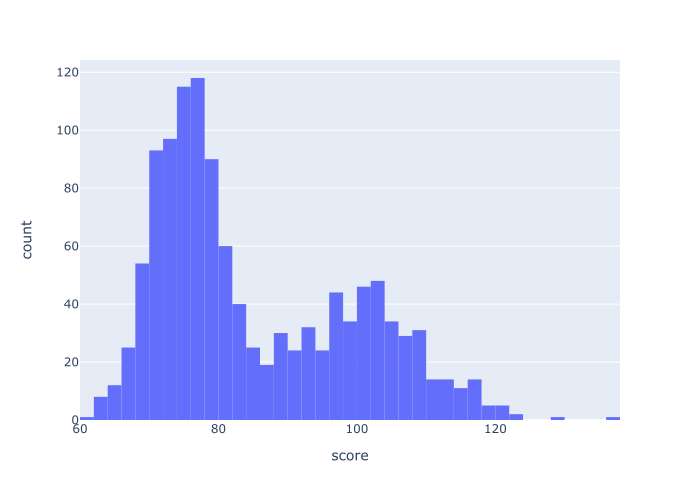
px.histogram(data_frame = score_data
,x = 'score'
)
这里是输出结果
解释
这是用px.histogram 函数绘制的一个非常简单的直方图。
在函数调用中,我们用代码data = score_data 指定了要绘制的DataFrame。 我们还指定了要绘制的确切列x = 'score' 。
请注意,列的名称,'score' ,是以字符串的形式呈现的。 当我们绘制一个DataFrame列时,该列的名称必须以这种方式传递给x 参数。
从视觉上看,你可以看到直方图有大约50个分仓。 实际上我们可以改变这一点,我们会在其他的例子中做。
另外,注意到默认的颜色是浅蓝色。 这在大多数情况下是很好的,但在某些情况下,你可能会因为审美或设计原因而想改变颜色。
让我们来看看如何做到这一点。
实例2:改变条形图的颜色
在这个例子中,我们将看看如何改变直方图条的颜色。
正如我刚才提到的,默认的颜色是一种中等的蓝色。
在这里,我们要把柱状图的颜色改为 "暗红色"。要做到这一点,我们要把color 参数设为color = 'darkred' 。
px.histogram(data_frame = score_data
, x = 'score'
,color_discrete_sequence = ['darkred']
)
输出
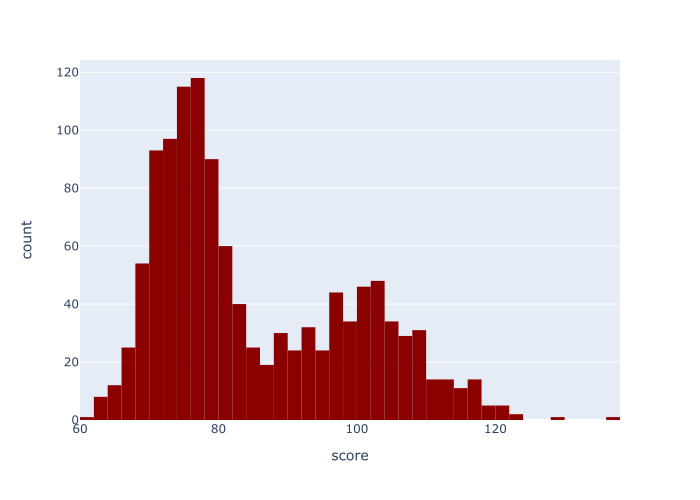
解释
这个直方图与例1中的直方图几乎完全一样。
唯一不同的是,我们将条形图的颜色改为'darkred' 。
要做到这一点,我们将color_discrete_sequence 参数设置为color_discrete_sequence = ['darkred'] 。
请注意,颜色的名称是用引号表示的,在一个列表中。 (有了这个参数,如果你有多个类别,你实际上可以指定多个不同的颜色)。
正如我之前在语法部分提到的,当你使用这个参数时,你可以使用各种命名的颜色,如red 、green 、dark red ,等等。 你也可以使用十六进制的颜色。 试一试吧!
例子3:改变仓的数量
现在,让我们来改变直方图中的分仓数量。
在这里,我们要创建一个有20个分仓的直方图。
px.histogram(data_frame = score_data
,x = 'score'
,nbins = 20
)
输出
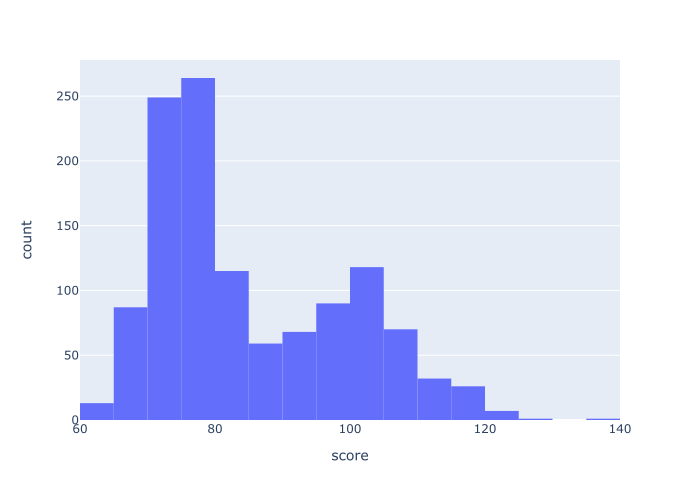
解释
在这里,我们已经创建了一个有20个bin的直方图。
为了做到这一点,我们使用了nbins 参数,我们将其设置为nbins = 20 。
请记住,当你分析你的数据时,看一下不同数量的直方图是很有用的。 大量的分仓往往会显示很多细节,而少量的分仓则会平滑地显示细节,以显示分布的大致形状。 两者都不 "正确"。你如何看待你的数据取决于你在寻找什么或你想做什么。
因此,你需要尝试不同数量的分仓,并根据你的分析目标来评估所产生的直方图。
归根结底,选择正确的分栏数是一门艺术。 你需要练习使用这种技术来了解最佳选择。
实例4:创建一个有多个类别的直方图
接下来,让我们创建一个有多个类别的直方图。
请记住,当我们创建数据集时,我们创建了一个叫做group 的分类变量。 这个变量有两个值:Group A 和Group B 。
我们可以使用这个分类变量来创建一个多类别的直方图。
所以在这个例子中,我们要绘制我们的数据,并将其分成不同的组。
要做到这一点,我们将使用color 参数。
px.histogram(data_frame = score_data
,x = 'score'
,color = 'group'
)
输出
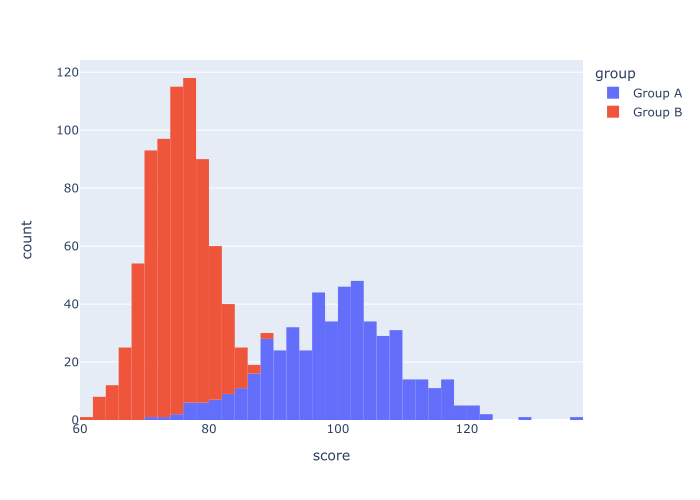
解释
正如你所看到的,产生的可视化有两个直方图:一个是Group A ,一个是Group B 。 这两张直方图都出现在同一个可视化中,但它们的颜色不同。
为了做到这一点,我们把color 的参数设置为color = 'group' 。
请记住,group 这个变量包含分类数据。 它有两个值:Group A 和Group B 。
因此,当我们设置color = 'group' ,Plotly Express实际上将数据分成了两个直方图......每个类别一个,每个直方图有不同的颜色。
如果你的数据有不同的类别,而你想在同一张图上显示这些类别,这是一个很好的技术。
例子5:创建一个有多个类别的直方图,并改变颜色
最后,让我们创建一个有多个类别的直方图,并改变颜色。
这有点像例子4,我们制作了一个多类别的直方图,又有点像例子2,我们改变了颜色。
让我们来看看,然后我再解释。
px.histogram(data_frame = score_data
,x = 'score'
,color = 'group'
,color_discrete_sequence = ['navy','darkorange']
)
输出
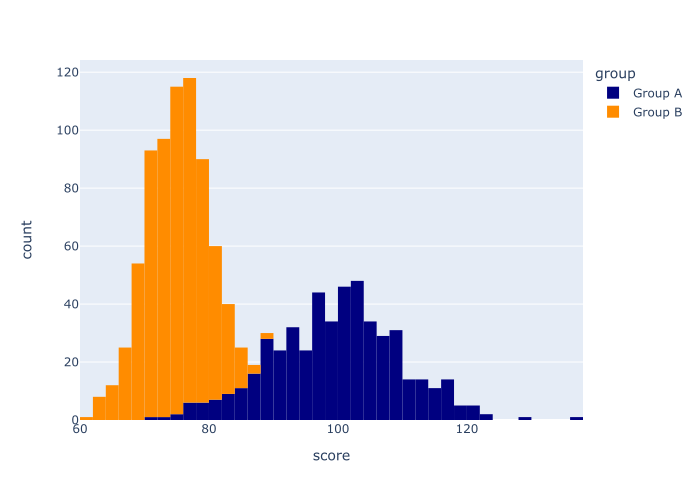
解释
那么这里发生了什么?
在这个例子中,我们调用了px.histogram 函数来创建一个Plotly直方图。
我们使用data_frame 参数来指定DataFrame,我们使用x 参数来指定确切的列。
我们用color = 'group' 来表示我们要做一个多类别的直方图,其中group 变量的不同类别对应于不同的颜色。
最后,我们用代码color_discrete_sequence = ['navy','darkorange'] 来设置不同类别所用的确切颜色。
这个例子有点结合了我们在以前的例子中使用的几种技术。
在这篇文章中,我已经向你展示了如何使用px.histogram() 创建Plotly直方图。
