

在这篇文章中,我们将学习引导的过程和类型。引导涉及使用编译器来编译其他编译器或自己。
目录:
- 简介
- 完整的引导
- 使用一个解释器
- 渐进式引导
- 总结
- 参考资料
先决条件
介绍
引导的概念涉及到使用编译器来编译编译器或自己。为此,我们需要一个坚实的基础,或者一个我们将用来运行编译器的机器。
很多时候,一种源语言的编译器并不存在,它只是没有在所需的机器上运行。假设我们想要一个将ML编译成X86机器代码的编译器,并希望它能在X86机器架构上运行。
我们可以获得一个生成ARM机器代码的ML编译器,它可以在ARM机器上运行。获得所需的编译器的方法是进行二进制翻译,即从ARM机器代码到x86代码编写一个编译器。这使得翻译后的编译器可以在x86上运行,同时生成在ARM机器架构上运行的ARM机器代码。
我们使用ARM到x86编译器将其翻译成x86代码。这引入了以下问题。
- 额外的程序使编译变得很费时。
- 在翻译过程中失去了效率。
- 我们仍然必须使ARM-to-x86编译器在x86机器上运行。
另一个更好的解决方案是在 ML 中编写 ML-to-x86 编译器,然后使用 ARM 上的 ML 编译器对其进行编译:
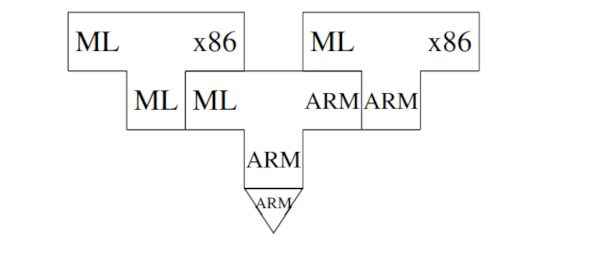
现在我们可以在 ARM 上运行 ML-to-x86 编译器,让它自己编译:
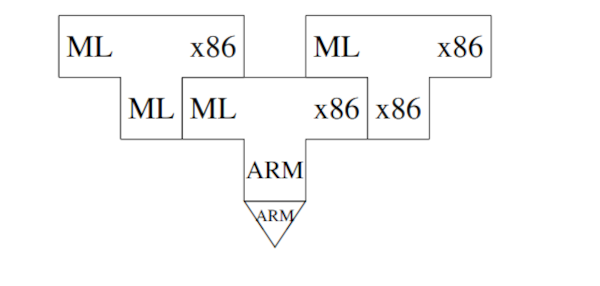
我们现在有了想要的编译器,它可以在x86平台上进行自我编译。如果以后对编译器进行扩展或作为正确性的部分测试,这是很有用的。
如果编译器在自我编译时,产生的目标代码与从进程中获得的目标代码不同,那么它一定有错误。反之则不然,也就是说,即使得到的目标相同,编译器也有错误。
我们可以将上述图表合并成一个涵盖两个执行过程的单一图表:
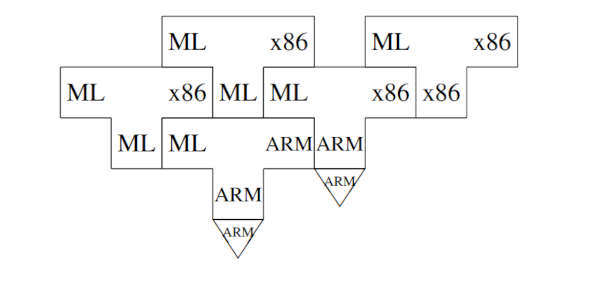
以上,用ARM编写的ML-to-x86编译器有两个功能,它是第一次编译的输出和将执行第二次编译的编译器。
作为第二次编译步骤的输入的编译器看起来像最左边编译器的输出。在这种情况下,我们避免了混乱,因为最左边的编译器没有运行,而且,语言也不匹配。
全面启动
在先决条件的文章中,我们了解到一个引导过程,它依赖于所需编程语言的现有编译器。更确切地说,它被称为半引导。那么在没有预先存在的编译器的时候,例如在开发一种新的编程语言的时候呢?
在这种情况下,我们进行完全的引导。一个常用的方法是使用预先存在的编程语言编写和使用一个QAD(Quick and Dirty)编译器。
同时,使用新的语言编写一个 "真正的 "编译器,并使用QAD编译器进行引导。
假设我们设计了一种语言M+,并且用ML写了一个从M+到ML的编译器。首先,我们对其进行编译,使其能够在目标上运行:
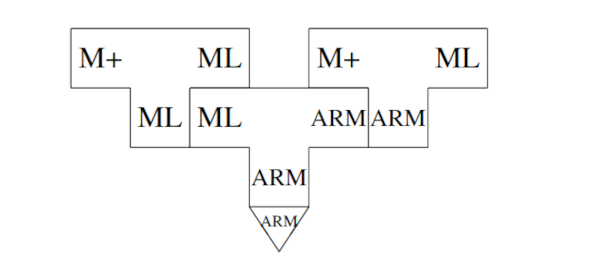
然后用QAD编译器来编译真正的编译器:
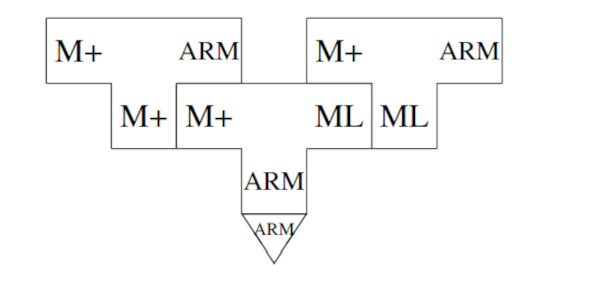
其结果是一个需要编译的ML程序:
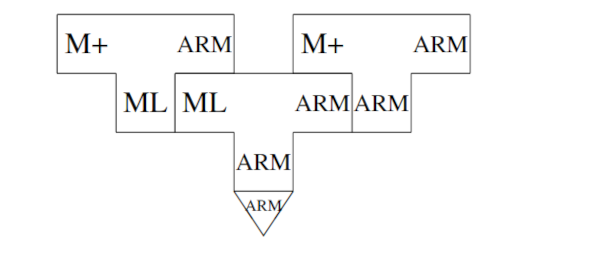
上面的输出是一个具有所需功能的编译器,但是,它仍然很慢,这是因为它是用QAD编译器编译的。通过让生成的编译器自己编译,可以得到一个更好的结果:
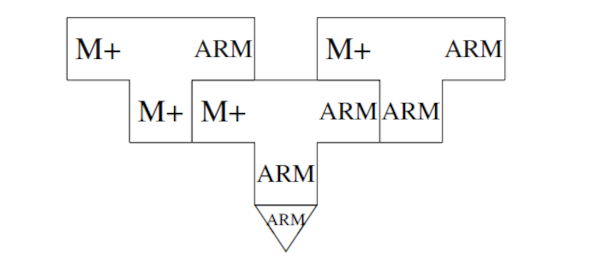
其输出是一个更快的编译器,但具有相同的所需功能。请注意,即使产生了一个具有正确功能的编译器,引导也可能不完整。
使用一个解释器
我们也可以选择写一个解释器,而不是写一个QAD编译器。从我们的例子来看,我们用ML写一个*M+*解释器,首先我们需要编译:
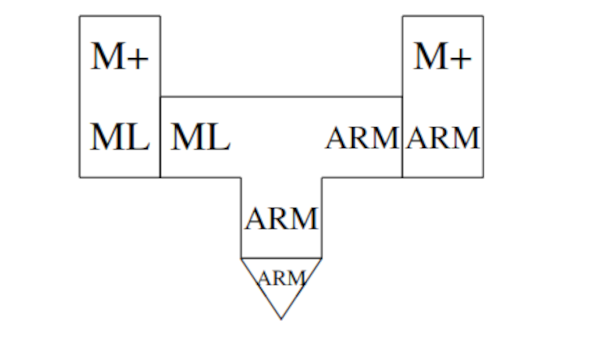
然后我们用上面的方法来直接运行*M+*编译器:
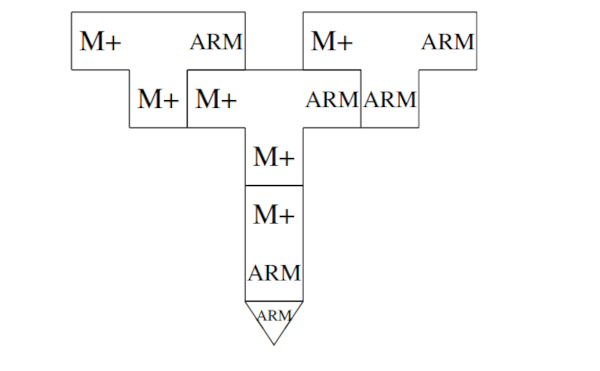
我们使用真正的编译器进行编译,因此当我们使用生成的编译器进行自我编译时,没有任何收获,这一步也可以作为测试,也可以用于扩展。
渐进式引导
我们也可以建立一种新的编程语言,也可以逐步建立其编译器。在这里,第一步是为语言的一个小子集写一个编译器,然后用同样的子集来写。
第一个编译器是用前面几节中描述的任何一种方法来引导的,此后,下面的过程会反复进行:
- 轻微的语言子集扩展
- 编译器扩展以编译扩展的子集,没有新功能
- 使用之前的编译器编译一个新的编译器
在每个步骤中,在前一个步骤中引入的特征被用于编译器。甚至当整个语言被编译后,这个过程还在继续,以提高编译器的质量。
总结
请注意,即使产生了具有正确功能的编译器,引导也可能是不完整的。
在没有预先存在的编译器的情况下,例如在开发一种新的编程语言时,我们进行完全的引导。一个常用的方法是使用预先存在的编程语言编写和使用一个QAD(Quick and Dirty)编译器。编译器应该允许用新语言编写的程序被执行。
增量引导包括建立一种新的编程语言,并逐步建立其编译器。
参考文献
- 编译器设计的基础知识 - Torben Ægidius Mogensen
