

Hibernate是JPA规范的一个实现。Hibernate有效地处理了OOPs和RDBMS处理数据的根本区别,并提供了编程的便利性。实施各种策略来映射hibernate,处理各种对象-关系阻抗不匹配问题。
在这篇文章中,我们将学习hibernate实现的各种继承映射策略,以处理继承的对象-关系阻抗错配问题。
什么是映射
简单来说,映射定义了面向对象模式的实体类在关系数据库表中的样子,也就是说,映射只不过是将对象模型转换为数据模型而已。
一般来说,实体类被映射到表,类的成员变量被映射到表的列,实体类的每个对象都对应于数据库表中的记录。
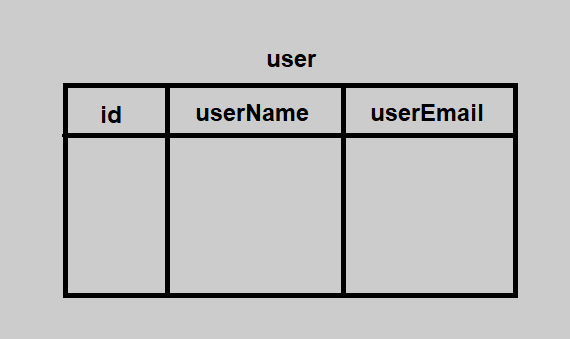
请看下面的实体类User
@Entity
@Table(name = "user")
public class User {
@Id
@Column(name = "id")
private int id;
@Column(name = "userName")
private String name;
@Column(name = "userEmail")
private String email;
//constructor, getters, and setters
}
上面的类对应于下面的表格:
什么是继承映射
在进入继承映射的细节之前,让我们先讨论一下,为什么我们需要继承映射。
ORM工具的一个重要功能是处理对象-关系阻抗不匹配。现在你会想到什么是 "对象-关系阻抗错配"?
在上面的例子中,将Java对象映射到数据库表中并不像它看起来那么容易。上面的例子是最简单的情况。但在很多情况下,由于在OOPs和RDBMS范式中处理数据的观念和风格,将对象模型映射到数据模型并不那么容易。这种认知、风格和范式的不匹配被称为 "对象-关系阻抗不匹配"。
让我们来谈谈一些范式的错配。
- 颗粒度。对象模型中的类的数量不等同于数据模型中的表的数量。
- 继承性或子类型。继承是面向对象编程范式的一个特点,在RDBMS中是不存在的。不存在一个表扩展另一个表的概念。
- 关联。在OOPs中,一个类可以包含对另一个类的引用,这被称为关联,但在RDBMS中,两个表是用外键关联的。不存在一个表进入另一个表的概念。
- 身份识别。Java提供"=="或equals()方法来比较两个对象,但在RDBMS中,主键被用来比较记录。
- 数据导航。在Java中,我们使用dot(.)操作符来遍历对象的网络,但在RDBMS中需要连接来检索表之间的记录。
继承映射有效地处理了上述的继承或子类型对象-关系阻抗不匹配问题。
现在,当我们对映射和继承映射的需求有了一点背景了解后,让我们更深入地挖掘继承映射的内容。要把类的层次结构映射到数据库表中,并没有直接的方法存在。
主要有三种最常用的策略来将类的层次结构映射到数据库表中:
- 每个类的表
- 每个子类的表
- 每个层次的表
让我们来详细谈谈每一种策略。
每个具体类的表
在这个映射策略中,表是为类层次结构中的每个具体类创建的。如果超类是一个接口或抽象类,将不会为其创建表,如果超类也是一个具体的类,那么也将为其创建一个表。
让我们考虑下面的对象模型图:
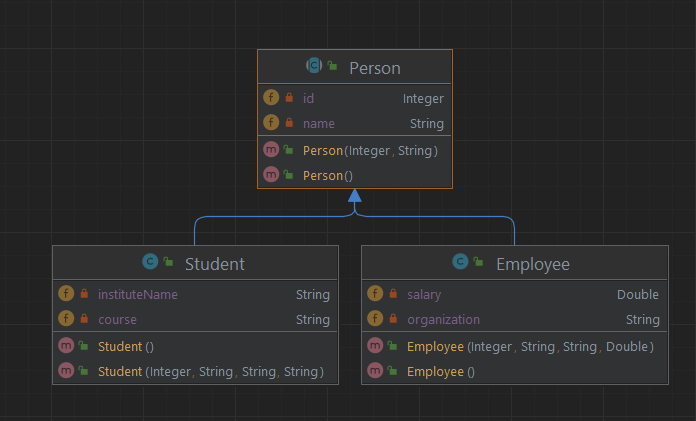
这里是实现每类继承映射的表的类的样子。
Person.java
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Person {
@Id
private Integer id;
private String name;
//constructor, getters, and setters
}
注意:在id属性处,我们不能把生成策略放在使用表的具体类策略上,否则会出现 "MappingException"。
这里是雇员类,它扩展了人的类。雇员类是一个具体的类。
Employee.java
@Entity
public class Employee extends Person {
private String organization;
private Double salary;
//constructor, getters, and setters
}
这里是扩展了Person类的具体类Employee:
@Entity
public class Student extends Person {
private String instituteName;
private String course;
//constructor, getters, and setters
}
我们只需要在父类上加上"@继承 "注释。没有必要把它放在子类上。
下面是hibernate运行的用于创建表employee和student的SQL查询:
create table Employee (
id integer not null,
name varchar(255),
organization varchar(255),
salary float(53),
primary key (id)
);
create table Student (
id integer not null,
name varchar(255),
course varchar(255),
instituteName varchar(255),
primary key (id)
);
在上面的查询中,我们可以清楚地看到,存在于超类Person中的id和name属性已经被复制到两个子类employee和student的数据模型中。
当我们使用这种策略对数据库进行多态查询时,在幕后hibernate使用sql unions从数据库中获取数据。
每个子类的表
在这个策略中,每个子类都被映射到它自己的表。无论超类是抽象类还是具体类,都会为其创建一个表。
超类的表根据超类中的属性设置了一些列。
子类的表根据其类中的属性设置了一些列,另外它还有一个"id "列,用于连接这个类和超类。
下面是我们的实体类在每个子类的表格策略下的样子。
Person.java
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Person {
@Id
private Integer id;
private String name;
//constructor, getters, and setters
}
在这里,我们使用的策略是InheritanceType.JOINED,所以它也被称为 "连接表策略"。
这里是Employee的子类,它扩展了Person的超类。
Employee.java
@Entity
public class Employee extends Person {
private String organization;
private Double salary;
//constructor, getters, and setters
}
这里是扩展了Person超类的Student子类。
Student.java
@Entity
public class Student extends Person {
private String instituteName;
private String course;
//constructor, getters, and setters
}
hibernate创建了三个表:
- 人表,有列--ID和名字
- 雇员表,有列--ID、组织和工资,以及
- 学生表,有列--id、机构名和课程
id "列是唯一一个可以复制到所有其他表中的列。
在执行多态查询以从数据库中获取数据时,hibernate使用连接操作来获取数据。
由于连接操作,JOINED表的策略缺乏性能。
每类层次的表
在这个策略中,只为整个类的层次结构创建一个表。
对于前面提到的类图,实体类看起来如下。
Person.java
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "identity", discriminatorType = DiscriminatorType.STRING)
public class Person {
@Id
private Integer id;
private String name;
//constructor, getters, and setters
}
这里是雇员类,它扩展了个人类。
Employee.java
@Entity
@DiscriminatorValue(value = "employee")
public class Employee extends Person {
private String organization;
private Double salary;
//constructor, getters, and setters
}
这是扩展了Person类的Student类。
Student.java
@Entity
@DiscriminatorValue(value = "student")
public class Student extends Person {
private String instituteName;
private String course;
//constructor, getters, and setters
}
我们使用"InheritanceType.SINGLE_TABLE "策略来实现每类层次的表继承映射策略,这就是为什么它也被称为单表策略。
由于整个类的层次结构只创建了一个表,我们需要一种方法来区别、区分或辨别记录,以确定它属于哪个类。为此,@DiscriminationColumn注解被用在超类上,@DiscriminationValue注解被用在子类上。
注意:如果我们不指定@DicriminationColumn和@DiscriminationValue注解,默认情况下会创建一个 "DTYPE "列,这个列的值是类本身的名称。
只有一个名为 "person "的表,以层次结构根的名义被创建,包含以下列:
- 身份
- id
- 姓名
- 组织
- 工资
- 课程和
- 机构名称
这里的 "身份 "列是判别列,用来判别、区分或区别属于不同类别的记录。
单表策略是默认的继承映射策略。在这个策略中,表的列可以包含空值。从性能上讲,这是实现的最佳策略,因为它在从数据库中检索数据时不需要任何连接或联合操作,因为所有的列都只存在于单表中。
这段文字就到此为止
💖👻💖编码快乐!👻🤩👻
