

当使用神经网络运行大型机器学习训练工作时,你需要一个GPU。说实话,现在芯片短缺,GPU很贵,而且很难买到!因此,你不可能有大量闲置的GPU在身边。
这就是为什么在云上租赁GPU是有意义的。但是,由于GPU很昂贵,你不希望在它们身上停留的时间超过必要的时间
这就是为什么在谷歌Kubernetes引擎上运行大型机器学习工作是合理的。GKE让你可以访问所有类型的机器。从拥有1个vCPU的简陋虚拟机到拥有几十个vCPU的怪物级虚拟机,并能使用最先进的GPU,如Nvidia A100。
Kubernetes的魅力在于,你可以根据你的工作负载的繁重程度,扩大或缩小资源的数量。
Kubernetes还有一个优秀的Jobs API,你可以利用它在大量的节点上分配工作。
而且,更重要的是,你不必重新发明车轮。要运行机器学习工作流,你可以使用例如流行的 kubeflow 开源机器学习框架,它就是为这个特定目的而设计的。
GPU很贵
但GPU还是很贵的
为了让你了解租用GPU的价格,让我们看看谷歌云中最先进的Nvidia A100的定价。
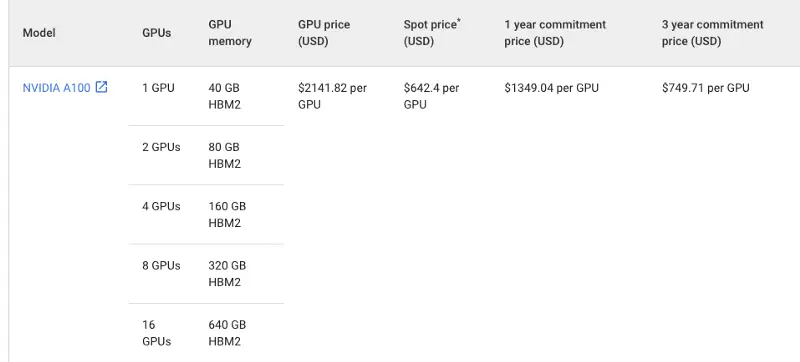
这是一个相当高的成本,每个GPU每月2141.82美元。是的,你可以通过承诺1年到3年的长期使用来大大降低成本。但是,这对大多数人来说几乎是行不通的!
如果有一种方法可以以60-90%的价格借用同样的GPU呢?
是的,你猜对了。Spot VMs就有这样的方法。
Spot VMs有什么问题?
当它听起来好得不像真的时候,它可能就是真的,对吗?
问题是,带有昂贵的Nvidia A100的Spot VM可以在任何时候从你身上拿走,而且很少有警告。但话又说回来,你不需要支付2140美元/月,而只需支付642美元/月(0.88美元/小时)?
与最多只能使用24小时的可抢占式虚拟机不同,现货虚拟机没有时间限制。
现货价格是动态的
我知道我提到了确切的价格,但现货价格确实每月至少变化一次。因此,对我刚才提到的数字要慎重考虑。还要记住,并非GCP的所有地区都有GPU可用。平均而言,你应该期望在现货价格下支付的GPU比全价GPU少60-91%。而且你只需要为你使用的部分付费。
弹性/冗余/并行性
为了利用Spot VMs和GKE的优势,你需要编写自己的机器学习作业,使其可以分布在多个节点和多个GPU上,并能够应对频繁的故障。因此,并行性、训练的分布以及在失败时重新启动作业将是能够利用Spot VMs的关键。
使用Terraform创建带有Spot VMs的GKE集群的代码
我将向你展示如何使用Terraform自动创建一个带有Spot VMs的GKE集群。
在撰写本文时,使用Spot VMs创建节点池的能力仍是一个预览功能。因此,为了用Spot VMs创建一个集群,我们需要解锁谷歌Terraform模块的一些测试功能。
要做到这一点,你会在文件terraform/gke**.tf**中看到以下源代码。
module "gke" {
depends_on = [google_service_account.gke-sa, google_project_service.kubernetes, google_project_service.compute, google_project_service.iam]
source = "terraform-google-modules/kubernetes-engine/google//modules/beta-public-cluster"
version = "19.0.0"
....
}
我们正在使用一个名为beta-public-cluster的测试版子模块,它使我们能够用Spot VM创建一个节点池。
而在terraform/providers**.tf**文件中你会看到。
provider "google" {
credentials = var.gcp_credentials
project = var.gcp_project_id
region = var.gcp_region
}
provider "google-beta" {
credentials = var.gcp_credentials
project = var.gcp_project_id
region = var.gcp_region
}
你需要同时设置谷歌提供商和谷歌-贝塔提供商。
现在让我们回到terraform/gke.tf,特别是node_pool部分。
module "gke" {
...
node_pools = [
{
name = var.gke_default_nodepool_name
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
initial_node_count = 1
},
{
name = "ephemeral-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
preemptible = true
},
{
name = "spot-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
spot = true
}
]
对于一个有全价虚拟机的标准节点池,不需要任何标志。
控制Kubernetes中每个Worker Node的机器类型
注意,machine_type控制每个工作节点使用的虚拟机。在上面的示例代码中,我使用的是一个廉价的虚拟机。但如果我觉得自己很有钱,我可以选择使用a2-megagpu-16g作为机器类型。这将使我能够访问一个拥有16个GPU和超过1TB内存的虚拟机。如果我试图解读生命的意义,这就是我想要的机器类型。
创建一个具有可抢占的虚拟机的节点池
要创建一个具有可抢占虚拟机的节点池,只需要在节点池中添加一个标志。
{
name = "ephemeral-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
preemptible = true
},
创建带有Spot VMs的节点池
要创建一个带有Spot VMs的节点池,只需添加标志spot = true就可以了
{
name = "spot-node-pool"
machine_type = "e2-medium"
min_count = 1
max_count = 1
local_ssd_count = 0
disk_size_gb = 25
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
service_account = "${var.gke_sa_name}@${var.gcp_project_id}.iam.gserviceaccount.com"
spot = true
}
variables.auto.tfvars
gcp_credentials = "../creds/gcp-service-account.json"gcp_project_id = "<YOUR-PROJECT-ID>"gcp_region = "us-west1"gcp_zone = "us-west1-a"gke_default_nodepool_name= "<DEFAULT-NODEPOOL-NAME>"gke_cluster_name = "<CLUSTER-NAME>"gke_network = "<VPC-NETWORK-NAME>"gke_subnetwork = "<VPC-SUBNETWORK-NAME>"gke_zones = ["us-west1-a"]gke_sa_name= "<GKE_SERVICE_ACCOUNT_NAME>"
现在我们看了一下源代码,让我们创建一个带有现货虚拟机和可抢占虚拟机的GKE集群。
terraform init
就这样吧!我希望这篇文章对你有用,也希望你能用Spot虚拟机为你的工作负载节省大量资金。
