

编译器的前端包括四个阶段,源代码从高级代码转换为中间表示,中间表示被优化并编译为机器代码。
目录
- 介绍
- 编译器的前端
- LLVM
- Kaleidoscope
- 总结
- 参考资料
先决条件
编译器的前端。
编译器的前端包括四个阶段,分别是词法分析、语法分析和语义分析:
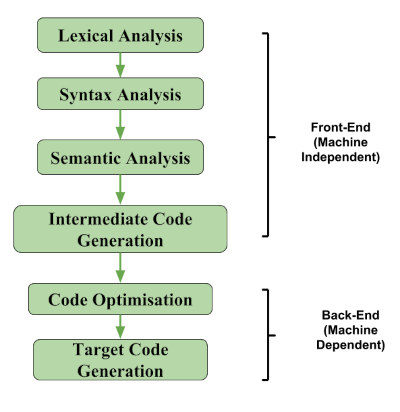
词法分析 : 在这里,用高级编程语言(如C/C++)编写的源代码被转换为有意义的词条,这些词条被词法分析器表示为标记。
语法分析 : 在这个阶段,标记被输入,它们被用来产生一个解析树。
语义分析 : 这里我们检查解析树是否符合所用编程语言的语义。
中间代码生成 : 中间代码是介于高级和低级机器代码之间的代码。它是可读的,同时也是低级的。
编译器前端的功能包括:
- 确定源代码的有效性
- 确定源代码的内容
- 构建源代码以方便分析和优化
编译器的设计过程遵循以下步骤:
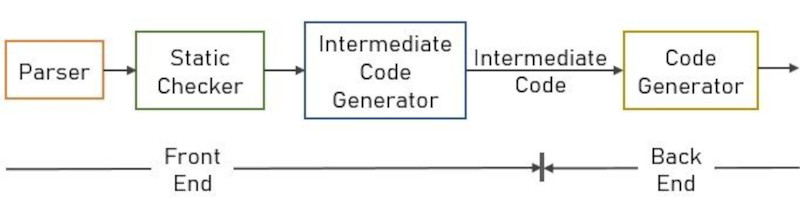
首先,用高级语言(如C/C++)编写的代码被用作解析器
的
输入,解析器产生一个AST(抽象语法树),它是代码生成器
的输入,生成机器代码,即处理器可以理解的指令。
LLVM
另一方面,用LLVM编译代码使编程语言创造者摆脱了产生高度优化代码的编译器后端的挑战。
在这种情况下,当AST通过代码生成器时,它现在有一个LLVM编译器组件,我们将有一个代码的LLVM中间表示IR作为输出。
我们将把IR通过LLVM编译器--llc ,将LLVM IR编译成可由处理器执行的二进制代码:
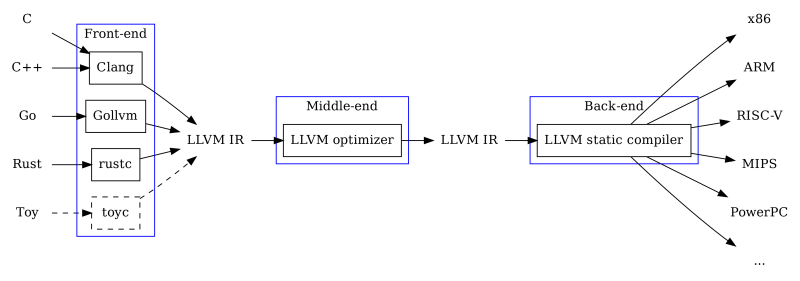
换句话说,就网络开发而言,我们正在构建前端,然后将存储、认证、托管等后端服务外包。
为什么使用LLVM
- 我们使用LLVM是为了不与机器代码打交道
- 它还允许我们针对多种处理器,如ARM、X86、Spark等
- LLVM专注于性能,这意味着它能生成更多的优化代码
万花筒(Kaleidoscope)
这是 "万花筒 "语言教程,展示了如何使用C++中的LLVM组件实现一种简单的语言。
我们将实现一个词法分析器,当输入以Kaleidoscope编写的源代码时,该词法分析器将产生标记,我们还将实现一个解析器,该解析器
将由词法分析器产生的标记转换成IR表示,该表示是低级的,但仍然是人类可读的,我们还将建立一个AST代码生成器,它将产生解析树,一个JIT编译器,我们将使用LLVM来添加优化,最后进行调试。
使用万花筒寻找第n个斐波那契数:
# find nth fibonacci number
def fib(x)
if x < 3 then
1
else
fib(x-1)+fib(x-2)
# 10th fibonacci number.
fib(10)
上面的代码返回55,这是第10个斐波那契数。
Kaleidoscope是一种程序性语言,它允许我们定义函数,就像我们在上面的例子中看到的那样--def fib(x),有循环结构,如for-loops和条件语句,如if-then-else,用户定义的操作符,JIT编译与简单的REPL和调试信息。
Kaleidoscope中唯一的数据类型是64位浮点--双倍数。因此,所有的值都是隐含的双精度,而且万花筒不需要像Java或C++那样进行类型声明。
我们还可以调用标准库。我们在LLVM的JIT中实现了这一点。这也意味着我们可以在使用前使用"extern"关键字来定义一个函数,如下图所示:
extern sin(arg);
extern cos(arg);
extern atan2(arg1 arg2);
atan2(sin(.4), cos(42))
我们还可以做其他的事情,比如显示曼德布罗特集。
总结
编译器的前端包括四个阶段,词法分析、语法分析和语义分析。
我们使用LLVM是为了不处理机器码,并针对广泛的处理器等原因。
当我们完成后,Kaleidoscope将支持用户定义的二进制和单进制运算符,它也将有自己的JIT编译器来即时评估代码,它也将支持控制流结构,如for-loops和if-then-else语句与SSA结构。
