


什么是Apache Airflow?
- Airflow是一个以编程方式编写、安排和监控工作流的平台。这些功能是通过任务的有向无环图(DAG)实现的。它是一个开源的,仍然处于孵化阶段。它于2014年在Airbnb的保护伞下初始化,从那时起,它在GitHub上有大约800个 贡献者和13000 颗星,获得了很好的声誉。Apache Airflow的主要功能是安排工作流、监控和编写。
- Apache airflow是一个由Airbnb开发的工作流(数据管道)管理系统。它被200多家公司使用,如Airbnb、Yahoo、PayPal、Intel、Stripe等。
- 在这里面,一切都围绕着以有向无环图 (DAG)实现的工作流对象。例如,这样的工作流程可能涉及多个数据源的合并和随后分析脚本的执行。它负责调度任务,同时尊重其内部的依赖性,并协调相关的系统。
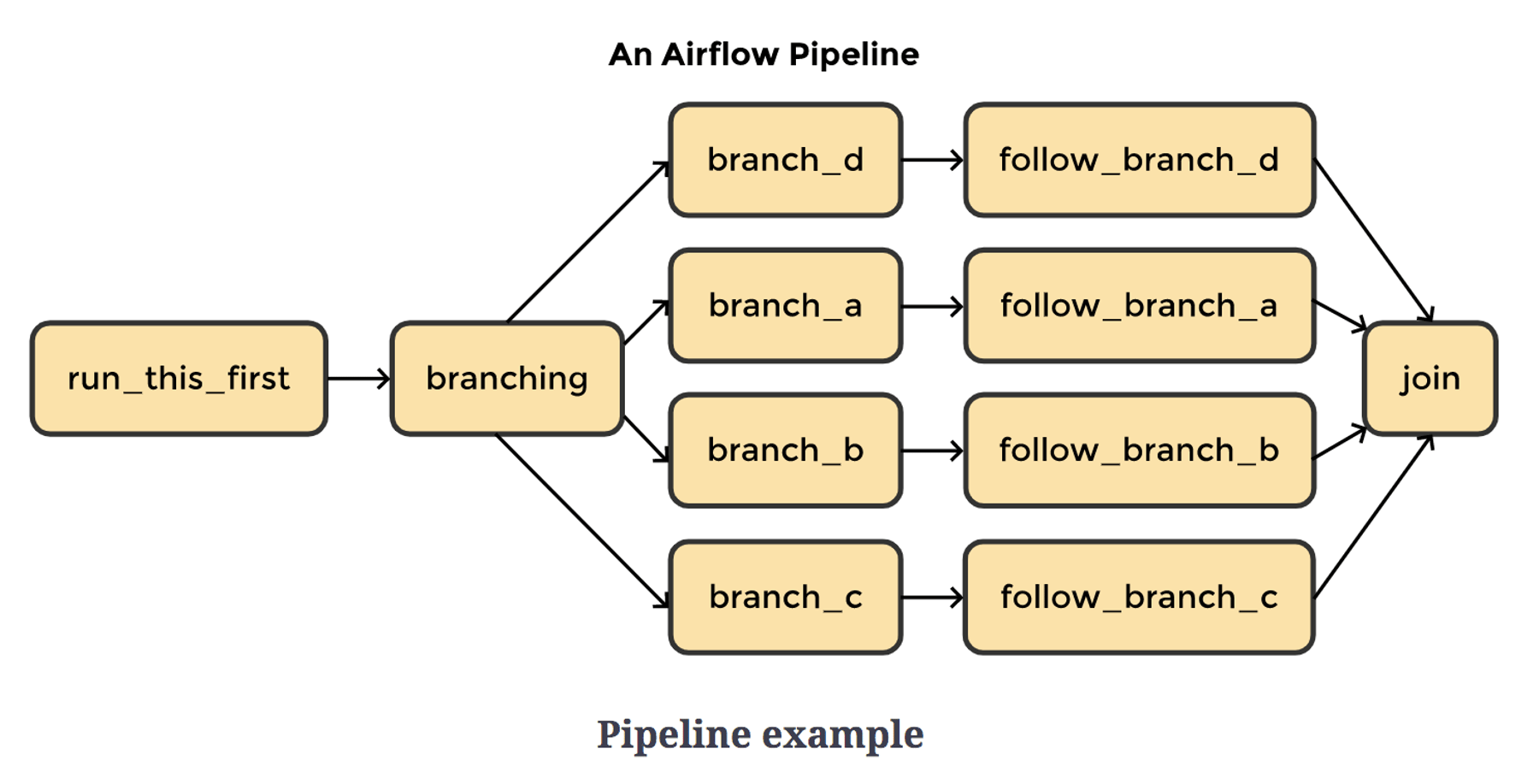
什么是工作流?
工作流是一个任务序列,它按计划启动或由一个事件触发。它经常被用来处理大数据处理管道。
一个典型的工作流程图

- 在任何工作流程中,总共有5个阶段。
- 首先,我们从源头下载数据
- 然后,将这些数据发送到其他地方进行处理
- 当处理完成后,我们得到结果并生成报告,通过电子邮件发送。
Apache Airflow的工作原理
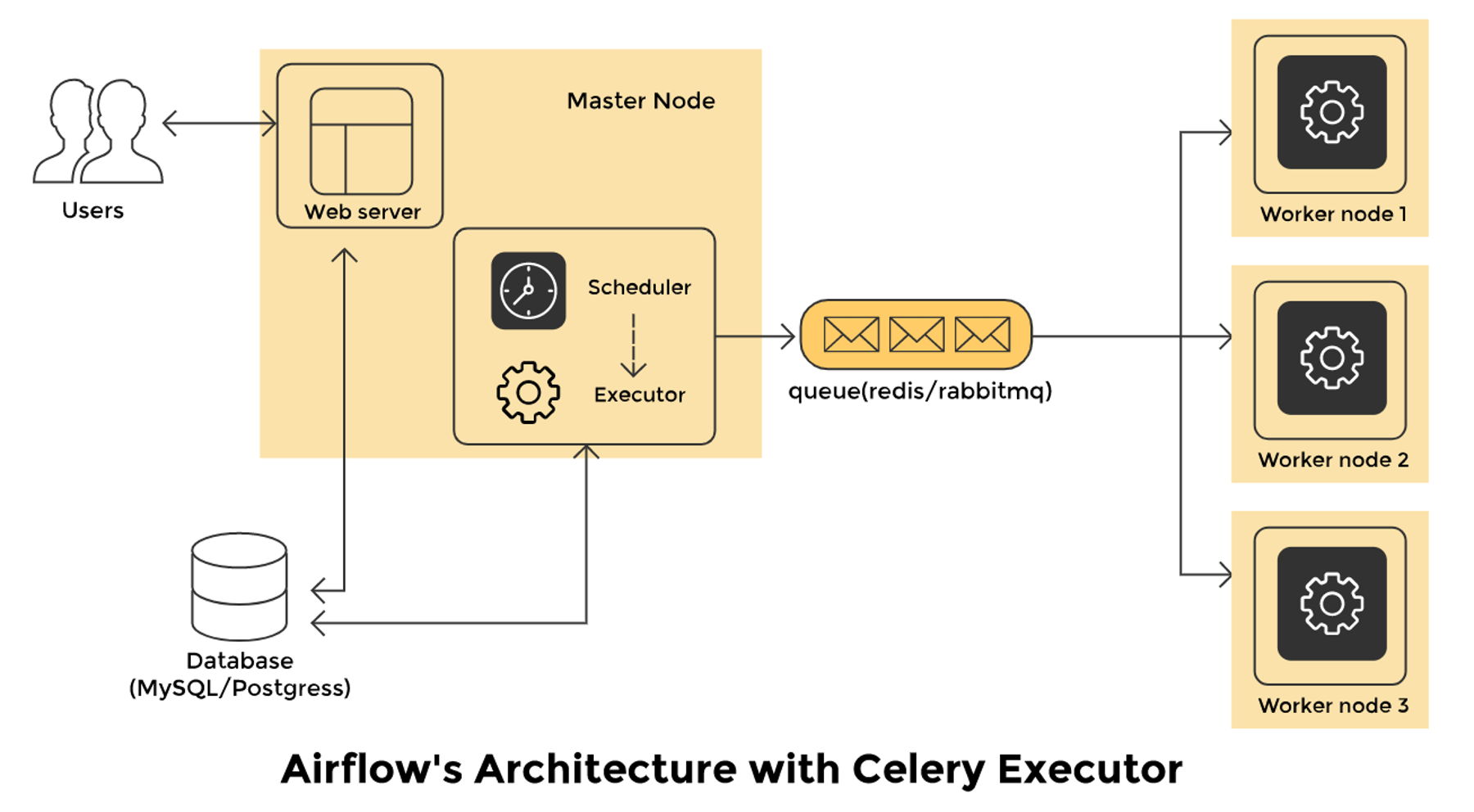
Apache Airflow的架构
有四个主要组件组成了这个强大的、可扩展的工作流调度平台。
- 调度器:调度器监控所有的DAG和它们相关的任务。 它定期检查活动任务的启动。
- 网络服务器:网络服务器是Airflow的用户接口。它显示任务的状态,并允许用户与数据库互动,从远程文件存储中读取日志文件,如谷歌云存储、微软Azure blobs等。
- 数据库:DAG及其相关任务的状态被保存在数据库中,以确保日程表能记住元数据信息。Airflow使用SQLAlchemy和对象关系映射(ORM)来连接到元数据数据库。调度器检查所有的DAG,并存储相关的信息,如调度间隔、每次运行的统计数据和任务实例。
- 执行器:有不同类型的执行器用于不同的使用情况。执行器的例子。
SequentialExecutor:这个执行器可以在任何时候运行一个任务。它不能并行地运行任务。它在测试或调试的情况下很有帮助。LocalExecutor:这种执行器可以实现并行化和超线程化。它非常适用于在本地机器或单个节点上运行Airflow。CeleryExecutor:该执行器是运行分布式Airflow集群的最受欢迎的方式。KubernetesExecutor:该执行器调用Kubernetes API,为每个任务实例的运行制作临时荚。
那么,Airflow是如何工作的呢?
Airflow在一定时期内对后台的所有DAG进行检查。这个周期是用processor_poll_interval 配置设置的,等于一秒钟。为需要执行的任务实例化,它们的状态在元数据数据库中被设置为SCHEDULED 。
日程表查询数据库,检索状态为SCHEDULED 的任务,并将其分配给执行者。然后,任务的状态变为QUEUED 。那些排队的任务被执行它们的工作者从队列中抽出。当这种情况发生时,任务的状态会变为RUNNING 。
当一个任务完成时,工作者会将其标记为失败或完成,然后调度员会更新元数据库中的最终状态。
特点
- 易于使用:如果你有一点python知识,你就可以在Airflow上进行部署了。
- 开源:它是免费和开源的,有很多活跃的用户。
- 强大的集成:它将给你提供现成的操作符,使你可以与谷歌云平台、亚马逊AWS、微软Azure等合作。
- 使用标准Python进行编码:你可以使用Python来创建简单到复杂的工作流程,具有完全的灵活性。
- 惊人的用户界面:你可以监控和管理你的工作流程。它将允许你检查已完成和正在进行的任务的状态。
原则
- 动态:Airflow管道是作为代码的配置(Python),允许动态管道生成。这允许编写动态实例化管道的代码。
- 可扩展性:轻松地定义你自己的操作者、执行者,并扩展库,使其适合适合你的环境的抽象水平。
- 优雅的:Airflow管道是精简和明确的。
- 可扩展性:它有一个模块化的架构,并使用一个消息队列来协调任意数量的工作者。Airflow已经准备好扩展到无穷大。
总结
在这篇文章中,我们讨论了Apache Airflow的基本概况。
