

让我们先来看看激活函数的定义。
"在人工神经网络中,每个神经元对其输入形成一个加权和,并将产生的标量值通过一个被称为激活函数的函数。"
-维基百科的定义
听起来有点复杂?别担心!读完这篇文章后,你会对激活函数有更好的理解。
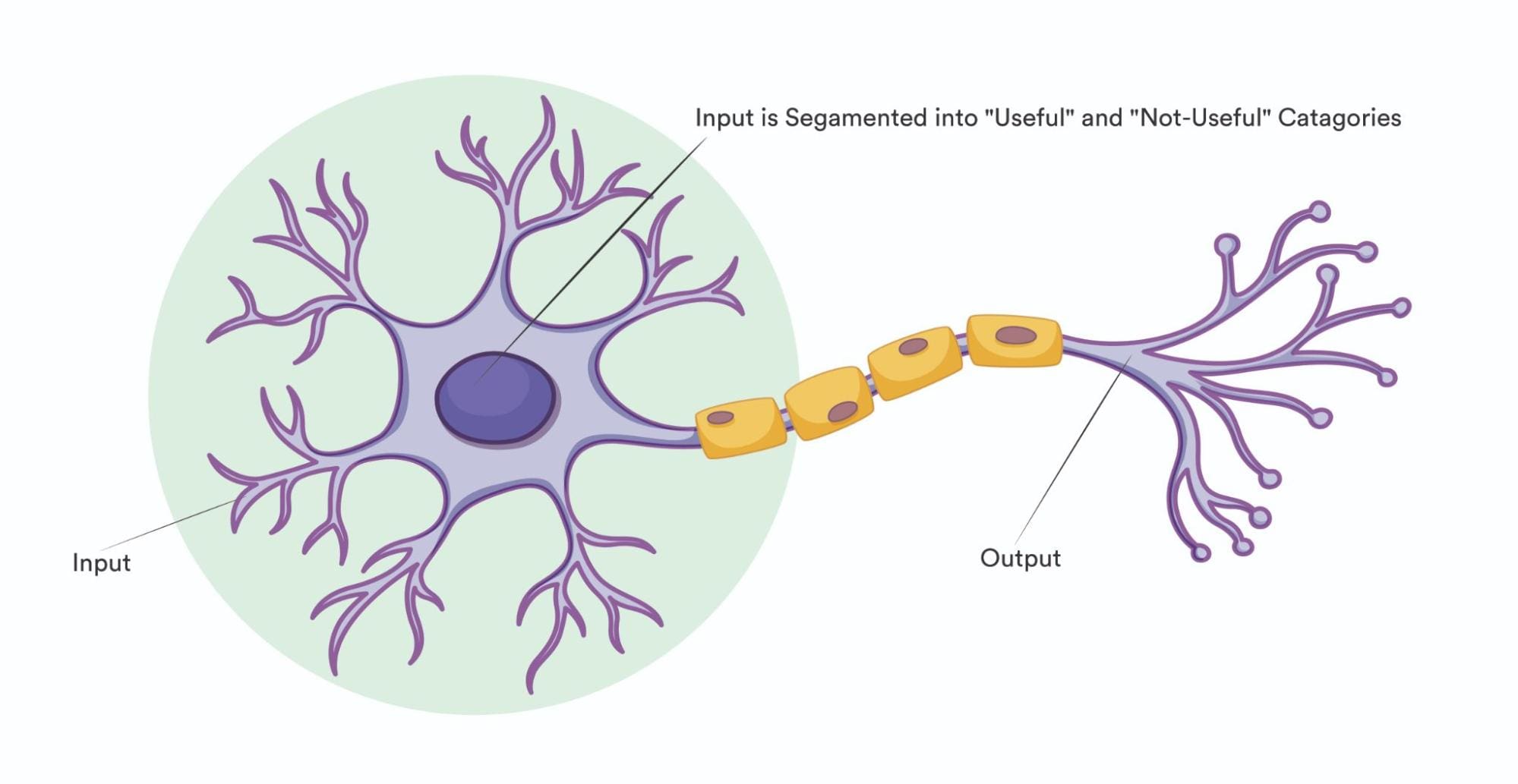
在人类中,我们的大脑接收来自外部世界的输入,对接收输入的神经元进行处理,并激活神经元的尾部以产生所需的决策。同样,在神经网络中,我们提供的输入是图像、声音、数字等,在人工神经元上进行处理,由算法激活正确的最终神经元层来产生结果。
为什么我们需要激活函数?
激活函数决定了一个神经元应该被激活还是不被激活。这意味着它将使用一些简单的数学运算来确定神经元对网络的输入在预测过程中是相关还是不相关。
为人工神经网络引入非线性并从输入值的集合中产生输出,是激活函数的目的。
激活函数的类型
激活函数可以分为三种类型。
- 线性激活函数
- 二进制步骤函数
- 非线性激活函数
线性激活函数
线性激活函数,通常称为身份激活函数,与输入成正比。线性激活函数的范围将是(-∞到∞)。线性激活函数只是将输入的加权总数相加,并返回结果。
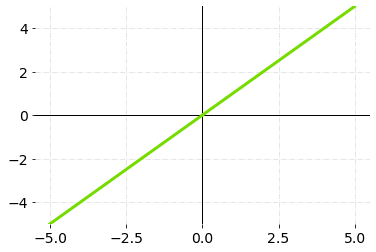
线性激活函数 - 图表
在数学上,它可以被表示为。
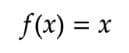
线性激活函数 - 方程式
优点和缺点
- 它不是一个二元激活,因为线性激活函数只提供一个激活范围。我们肯定可以把几个神经元连接在一起,如果有多个激活,我们可以在此基础上计算出最大值(或软最大值)。
- 这个激活函数的导数是一个常数。也就是说,梯度与x(输入)无关。
二进制步骤激活函数
在二进制步骤激活函数中,一个阈值决定了一个神经元是否应该被激活或不激活。
激活函数将输入值与阈值进行比较。如果输入值大于阈值,神经元被激活。如果输入值小于阈值,它就被禁用,这意味着它的输出不会被发送到下一层或隐藏层。
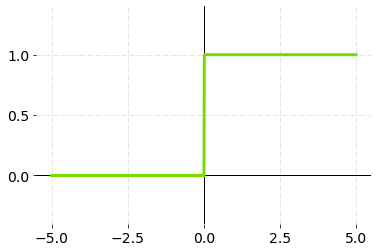
二进制阶梯函数--图表
在数学上,二元激活函数可以表示为。
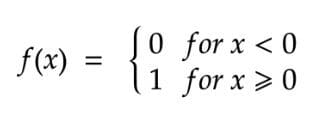
二元阶梯激活函数--方程式
优点和缺点
- 它不能提供多值输出--例如,它不能用于多类分类问题。
- 阶梯函数的梯度为零,这使得反向传播程序变得困难。
非线性激活函数
非线性激活函数是最常用的激活函数。它们使人工神经网络模型适应各种数据和区分输出的过程变得不复杂。
非线性激活函数允许多层神经元的堆叠,因为现在的输出将是通过多层输入的非线性组合。任何输出都可以表示为神经网络中的功能计算输出。
这些激活函数主要根据其范围和曲线来划分。本文的其余部分将概述神经网络中使用的主要非线性激活函数。
1.西格玛
Sigmoid接受一个数字作为输入,并返回一个介于0和1之间的数字。它使用起来很简单,并且具有激活函数的所有理想特性:非线性、连续微分、单调性和设定的输出范围。
这主要用于**二元分类问题。**这个sigmoid函数给出了一个特定类别存在的概率。
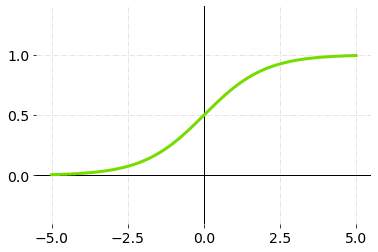
西格玛激活函数 - 图表
在数学上,它可以表示为。
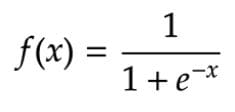
西格玛激活函数 - 方程
优点和缺点
- 它在本质上是非线性的。这个函数的组合也是非线性的,它将给出一个模拟的激活,而不像二进制阶梯激活函数。它也有一个平滑的梯度,对分类器类型的问题很好。
- 与线性激活函数的(-∞,∞)相比,激活函数的输出总是要在(0,1)的范围内。因此,我们为我们的激活定义了一个范围。
- Sigmoid函数引起了一个**"梯度消失 "**的问题,Sigmoids会饱和并杀死梯度。
- 它的输出 不是以零为中心,它使梯度的更新在不同的方向上走得太远。输出值在零和一之间,所以它使优化更加困难。
- 该网络要么拒绝学习更多的东西,要么就是极其缓慢。
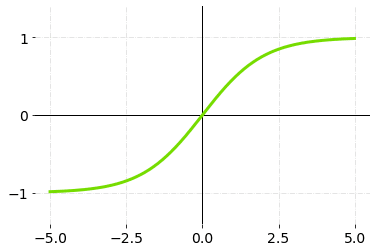
2.TanH (双曲正切)
TanH将一个实值的数字压缩到**[-1, 1]的范围。它是非线性的,但它与Sigmoid不同,它的输出是以零为中心的**。这样做的主要好处是,在TanH的图形中,负数输入将被强烈地映射到负数,而零数输入将被映射到几乎为零。
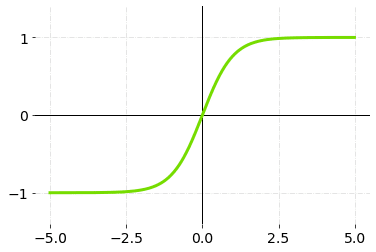
TanH 激活函数 - 图表
在数学上,TanH函数可以表示为。
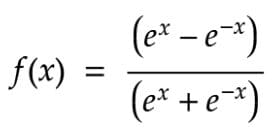
TanH 激活函数 - 方程
优点和缺点
- TanH也有梯度消失的问题,但TanH的梯度比sigmoid强(导数更陡峭)。
- TanH是以零为中心的,梯度不需要向特定方向移动。
3.ReLU (Rectified Linear Unit)
ReLU是Rectified Linear Unit的缩写,是应用中最常使用的激活函数之一。它解决了梯度消失的问题,因为ReLU函数的最大梯度值是1。它还解决了神经元饱和的问题,因为ReLU函数的斜率从不为零。ReLU的范围在0到无穷大之间**。**
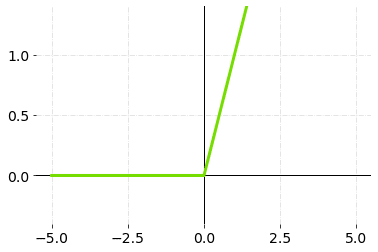
ReLU 激活功能 - 图形
在数学上,它可以表示为。
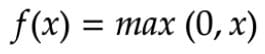
ReLU 激活功能 - 方程
优点和缺点
- 由于只有一定数量的神经元被激活,与sigmoid和TanH函数相比,ReLU函数的计算效率高得多。
- 由于ReLU的线性、非饱和特性,它加速了梯度下降向损失函数的全局最小值的收敛。
- 它的局限性之一是,它只能在 人工神经网络模型的隐藏层内使用 。
- 一些梯度在训练中可能是脆弱的。
- 换句话说,对于ReLu区域(x<0)的激活,梯度将是0,因为在下降过程中,权重不会得到调整。这意味着,那些进入该状态的神经元将停止对输入的变化做出反应(仅仅是因为梯度为0,没有任何变化),这被称为垂死的ReLu问题。
4.Leaky ReLU
Leaky ReLU是ReLU激活函数的升级版,用于解决垂死的ReLU问题,因为它在负区有一个小的正斜率。但是,目前在不同的任务中,其效益的一致性是模糊的。
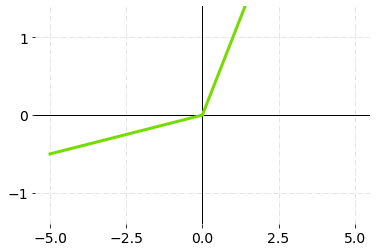
泄漏的ReLU激活功能 - 图表
在数学上,它可以表示为。
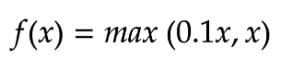
泄漏的ReLU激活功能 - 方程
优点和缺点
- Leaky ReLU的优点与ReLU的优点相同,此外,它还可以进行反向传播,甚至对负的输入值也是如此。
- 对负的输入值稍作修改,图形左边的梯度就会变成一个真实的(非零)值。因此,该区域将不再有死的神经元。
- 对于负的输入值,预测可能不稳定。
5.ELU (指数线性单位)
ELU也是ReLU的变化之一,它也解决了死ReLU的问题。ELU,就像泄漏的ReLU一样,也通过引入一个新的α参数并将其与另一个方程相乘来考虑负值。
ELU的计算成本比泄漏式ReLU略高,除了负输入,它与ReLU非常相似。对于正输入,它们都是同一函数的形状。
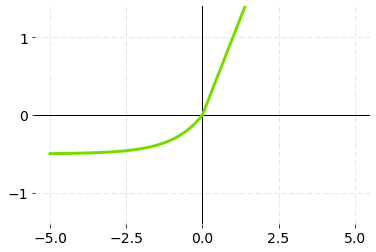
ELU的激活功能--图
在数学上,它可以表示为。
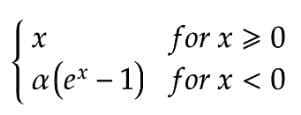
ELU激活功能 - 方程
优点和缺点
- ELU是ReLU的一个强有力的替代品。与ReLU不同,ELU可以产生负输出。
- 在ELU中存在指数运算,所以它增加了计算时间。
- 没有对'a'值的学习,以及爆炸梯度问题。
6.6.Softmax
许多sigmoids的组合被称为Softmax函数。它决定了相对概率。与sigmoid激活函数类似,Softmax函数返回每个类别/标签的概率。在多类分类中,Softmax激活函数最常被用于神经网络的最后一层。
Softmax函数给出了当前类别相对于其他类别的概率。这意味着它也考虑了其他类别的可能性。
Softmax 激活功能--图表
在数学上,它可以表示为。
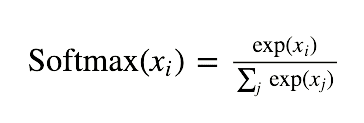
Softmax 激活功能--方程式
优点和缺点
- 它比绝对值更好地模拟了一个编码标签。
- 如果我们使用绝对值(模数),就会失去信息,但指数本身就能解决这个问题。
- softmax函数也应该用于多标签分类和回归任务。
7.7.Swish
Swish允许传播少量的负权重,而ReLU将所有非正权重设置为零。这是决定非单调平滑激活函数(如Swish的)在渐进式深度神经网络中成功的一个关键属性。
这是一个由谷歌研究人员创造的自我门控激活函数。
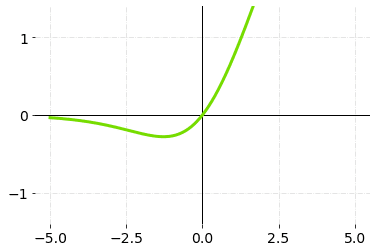
摆动激活功能--图表
在数学上,它可以被表示为。
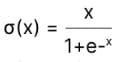
Swish激活功能--公式
优点和缺点
- Swish是一个平滑的激活函数,这意味着它不会像ReLU那样在x等于零时突然改变方向。相反,它平稳地从0向<0的值弯曲,然后再向上弯曲。
- 非正值在ReLU激活函数中被清零。另一方面,负数对于检测数据中的模式可能是有价值的。由于稀疏性,大的负数被抹去,导致双赢的局面。
- 唰唰激活函数的非单调性增强了输入数据和权重的学习期限。
- 计算成本略高,而且随着时间的推移,该算法可能会出现更多问题。
重要的考虑因素
在选择适当的激活函数时,必须考虑以下问题和议题。
梯度消失是神经网络训练过程中经常遇到的问题。像sigmoid激活函数,一些激活函数的输出范围很小(0到1)。因此,sigmoid激活函数的输入的巨大变化将在输出中产生一个小的修改。因此,导数也变得很小。这些激活函数只用于只有几层的浅层网络。当这些激活函数应用于多层网络时,梯度可能会变得太小,无法进行预期的训练。
爆炸梯度是指在训练过程中建立大量不正确的梯度的情况,导致神经网络模型权重的巨大更新。当出现爆炸性梯度时,可能会形成一个不稳定的网络,而训练无法完成。由于爆炸梯度,权重值有可能增长到溢出的程度,导致NaN值的损失。
最后的经验之谈
- 所有隐藏层一般都使用相同的激活函数。ReLU激活函数只应 在隐藏层中使用,以获得更好的效果。
- 由于梯度消失,Sigmoid和TanH激活函数不应该在隐藏层中利用,因为它们使模型在训练中更容易出现问题。
- 在深度超过40层的人工神经网络中使用Swish函数**。**
- 回归问题应使用线性激活函数
- 二元分类问题应使用sigmoid激活函数
- 多类分类问题应使用softmax激活函数。
神经网络结构及其可用的激活函数。
- 卷积神经网络(CNN)。ReLU激活函数
- 递归神经网络(RNN)。TanH或sigmoid激活函数
你可以找到无数的其他文章来评估激活函数的比较。我建议你亲自动手,好好练习。
